Wrapping up
Scaling and Optimizing Data Pipelines with Polars

Liam Brannigan
Data Scientist & Polars Contributor
Chapter 1
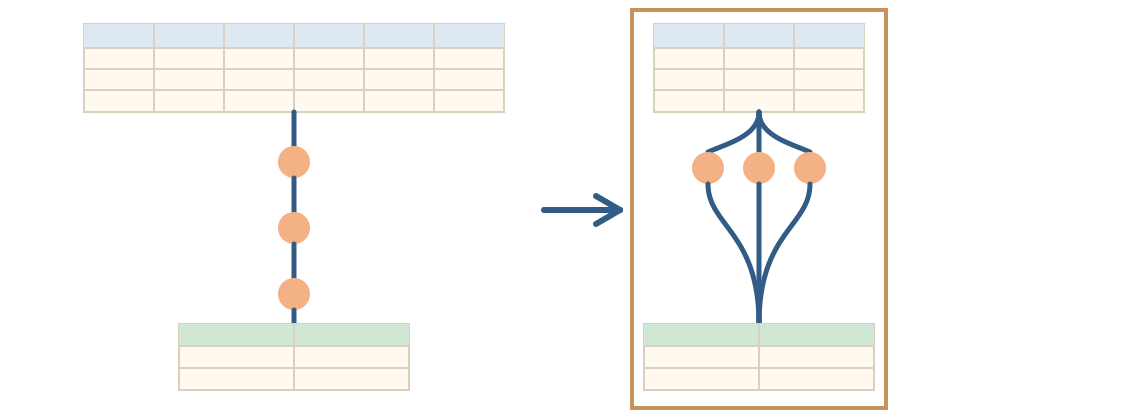
- Understanding how Polars optimizes lazy queries behind the scenes
- Reading query plans and profiling execution
- Using sorted data and fast-path operations to reduce work
Chapter 2
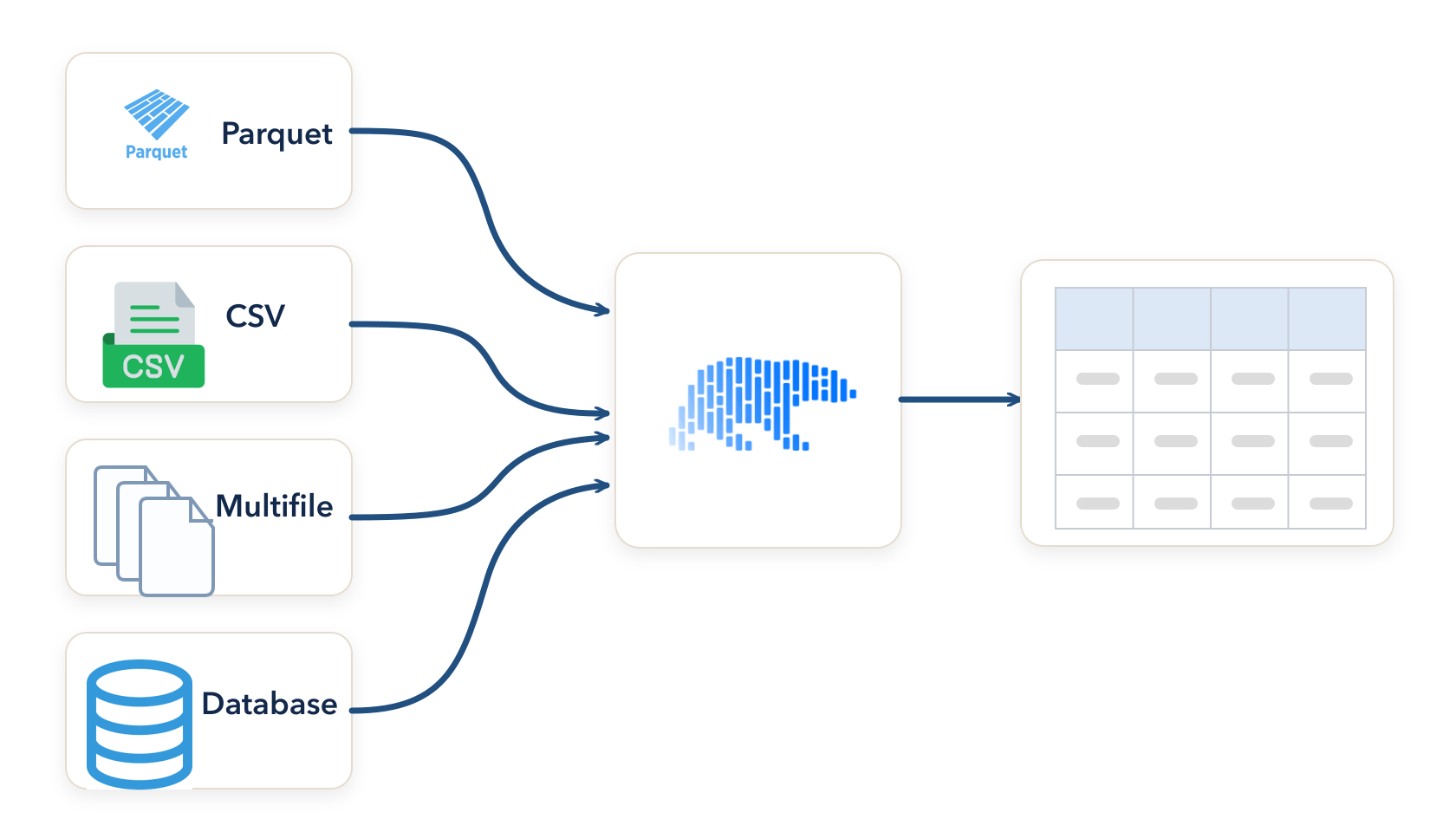
- Comparing CSV and Parquet and inspecting file metadata
- Controlling how Polars scans and writes data
- Scaling to multifile datasets, partitioned layouts, and databases
Chapter 3
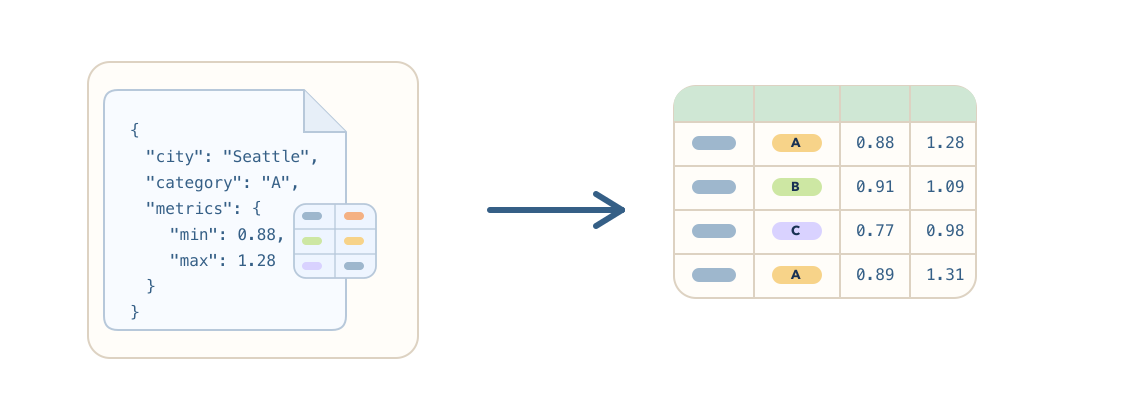
- Working with list and struct columns for nested data
- Using categorical and enum types for repeated strings
- Estimating DataFrame size and tuning numeric precision
Chapter 4
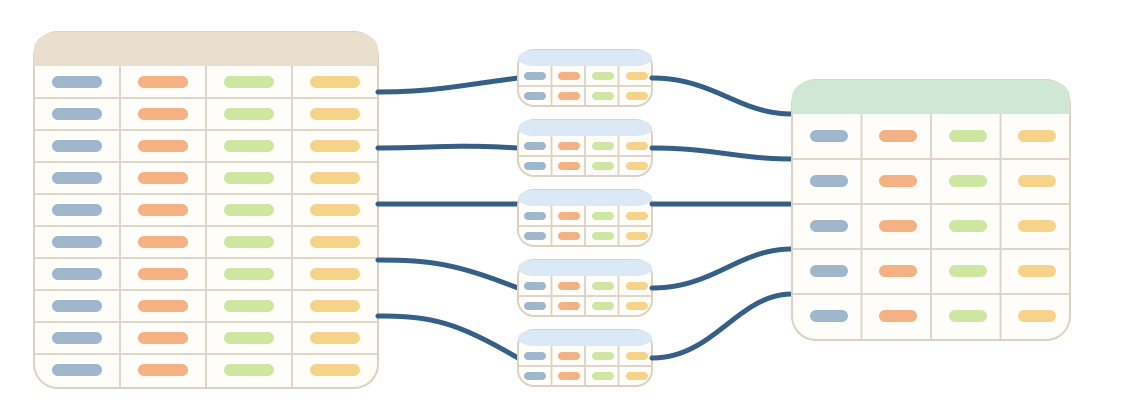
- Targeting default, streaming, and GPU execution engines
- Processing results in batches and sinking outputs to disk
- Testing Polars queries for robust, reliable pipelines

