Working with the streaming and GPU engines
Scaling and Optimizing Data Pipelines with Polars

Liam Brannigan
Data Scientist & Polars Contributor
Query execution engines
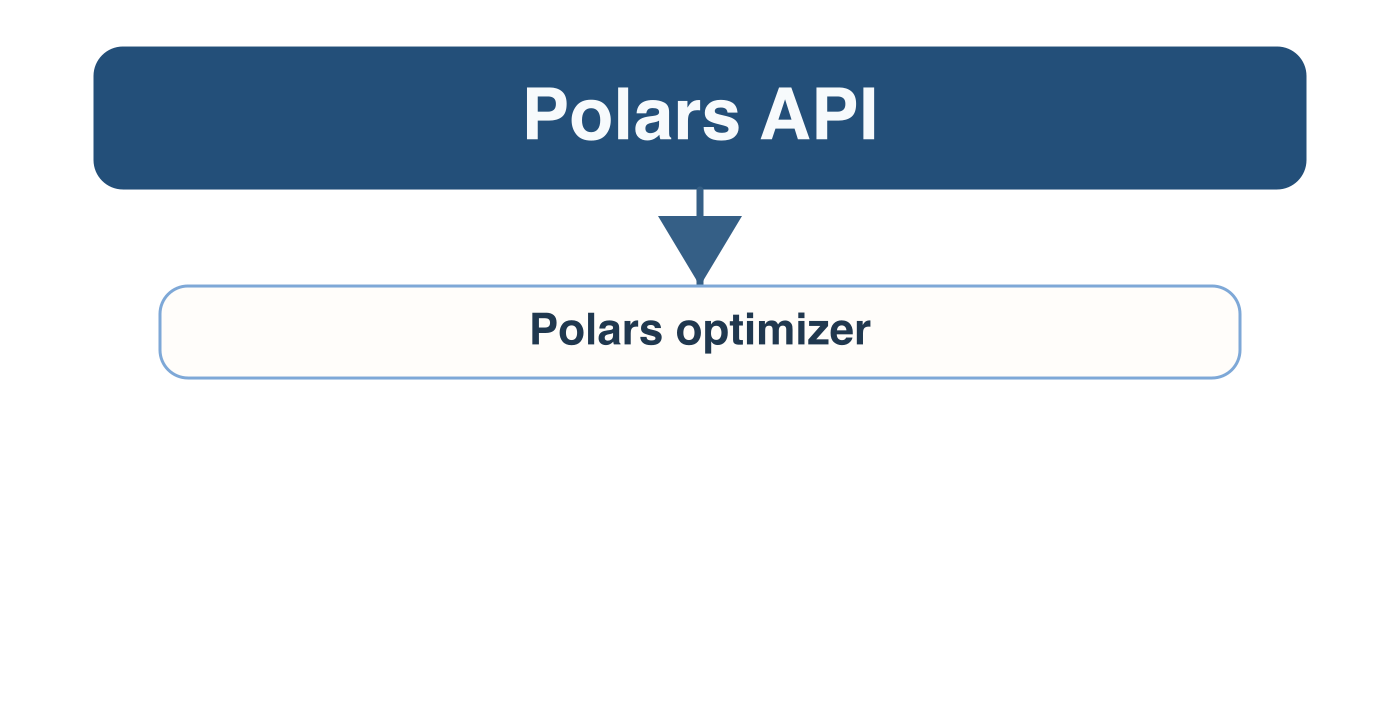
Query execution engines
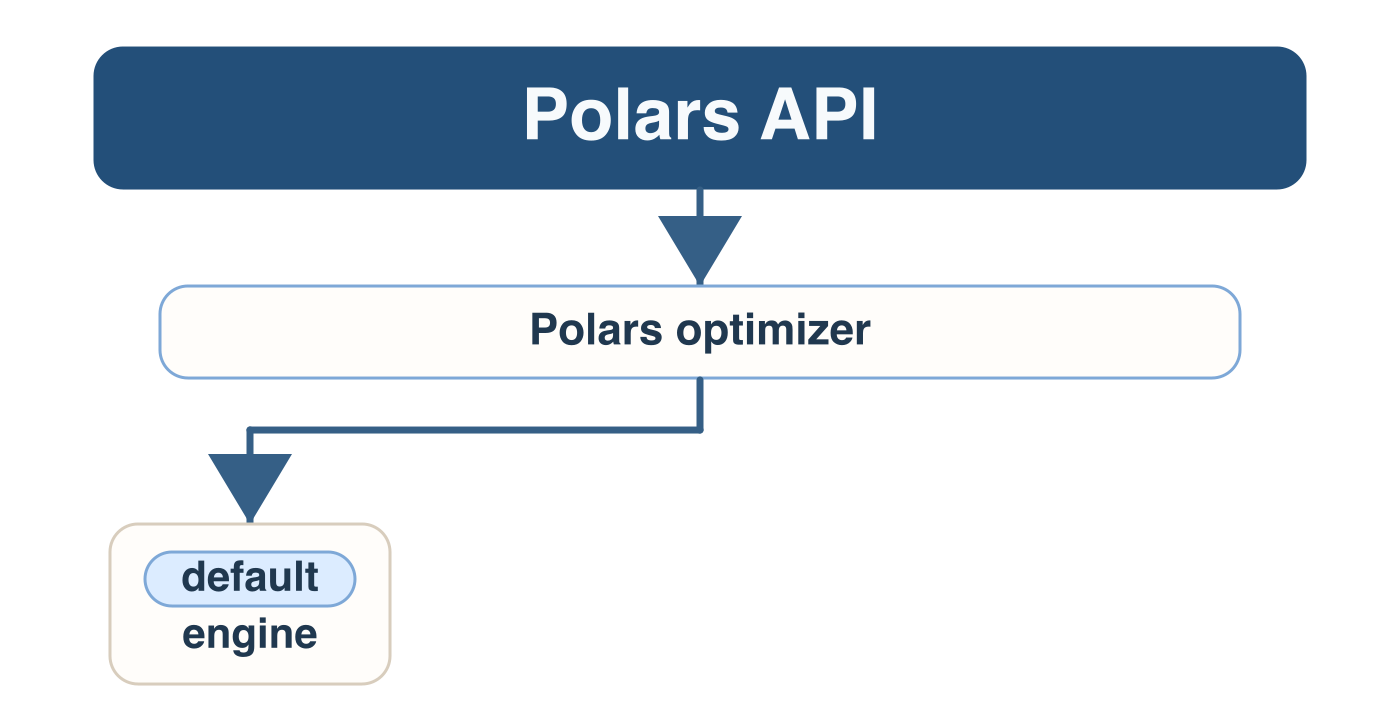
Query execution engines
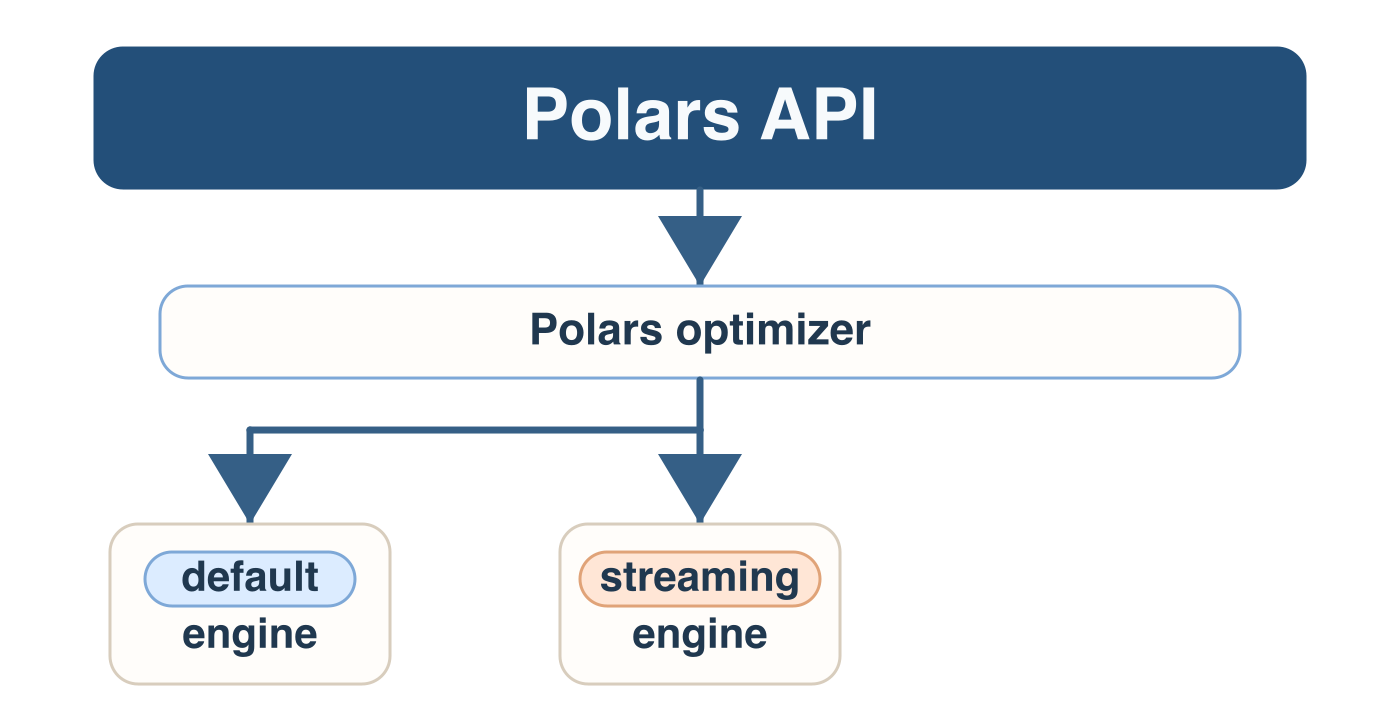
Query execution engines
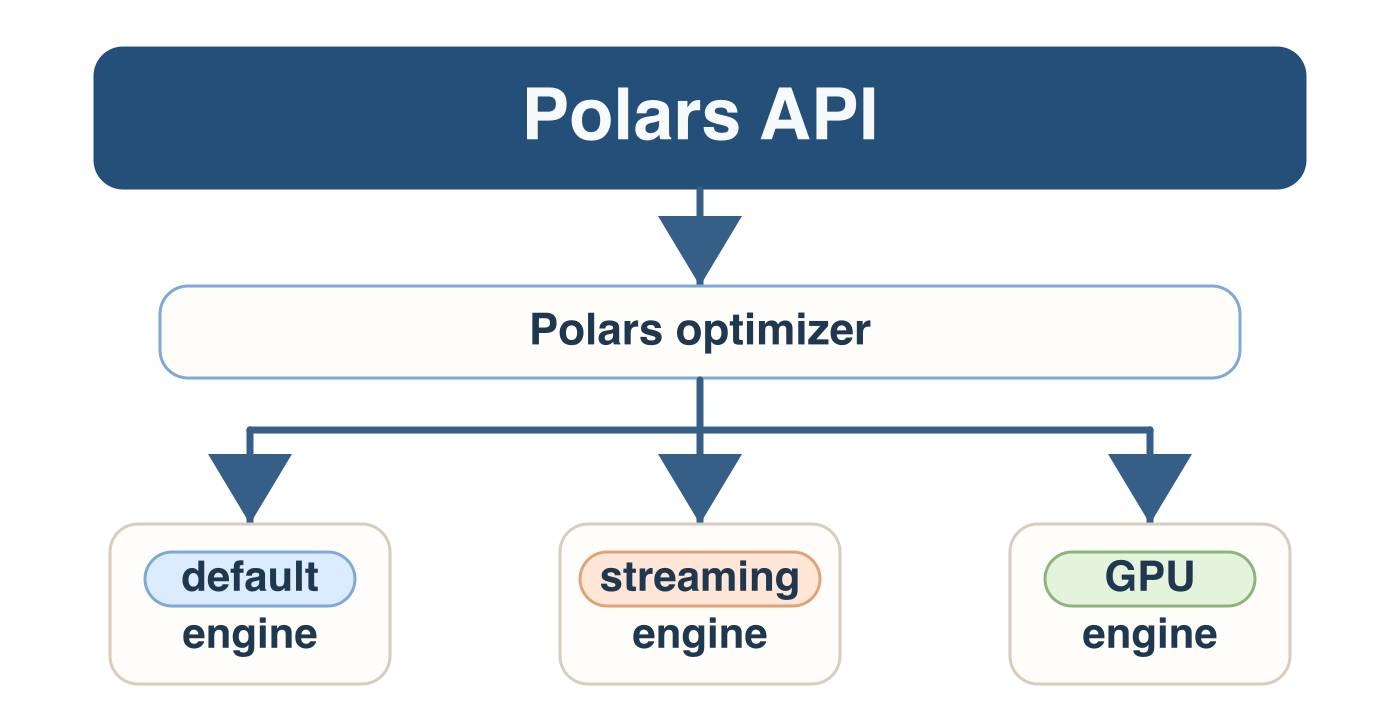
Targeting the streaming engine
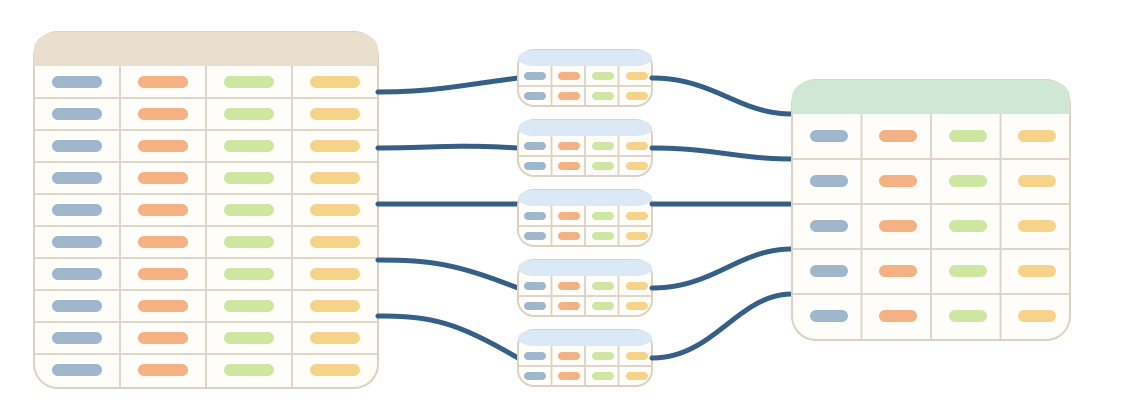
- Unsupported streaming steps automatically fall back to the default engine
Choosing an engine