Intermediate Aggregate Functions
Data Pipeline Automation in Snowflake

Emily Melhuish
Technical Curriculum Developer, Snowflake
Order of Operations
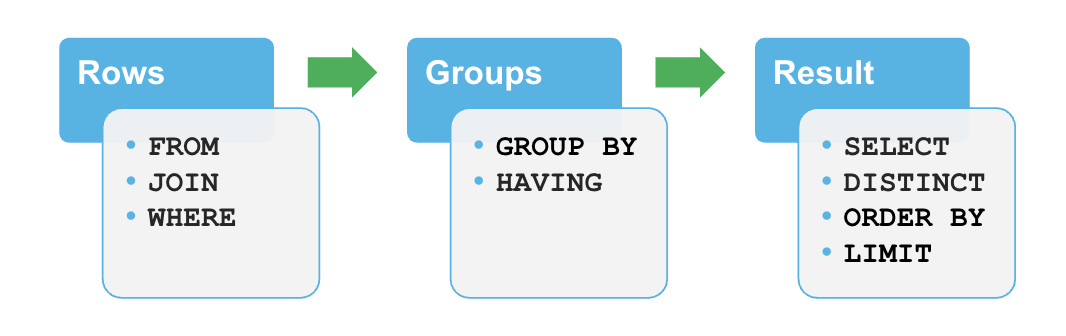
SQL doesn't run in the order you write it
- Rows: build the dataset
- Groups: summarise it
- Result: shape the output
1 * Snowflake Learning Material
GROUPING() and GROUPING_ID()
SELECT region, warehouse_name, SUM(credits_used) AS total_credits, GROUPING(region) AS is_region_agg, GROUPING(warehouse_name) AS is_wh_agg ,
GROUPING_ID(region, warehouse_name) AS grouping_level
FROM usage
GROUP BY ROLLUP (region, warehouse_name);


