Answering the question: Should I have a beach party?
Fundamentals of Bayesian Data Analysis in R

Rasmus Bååth
Data Scientist
The questions
- What's likely the average water temperature on 20th of Julys?
- What's the probability that the water temperature is going to be 18 or more on the next 20th?
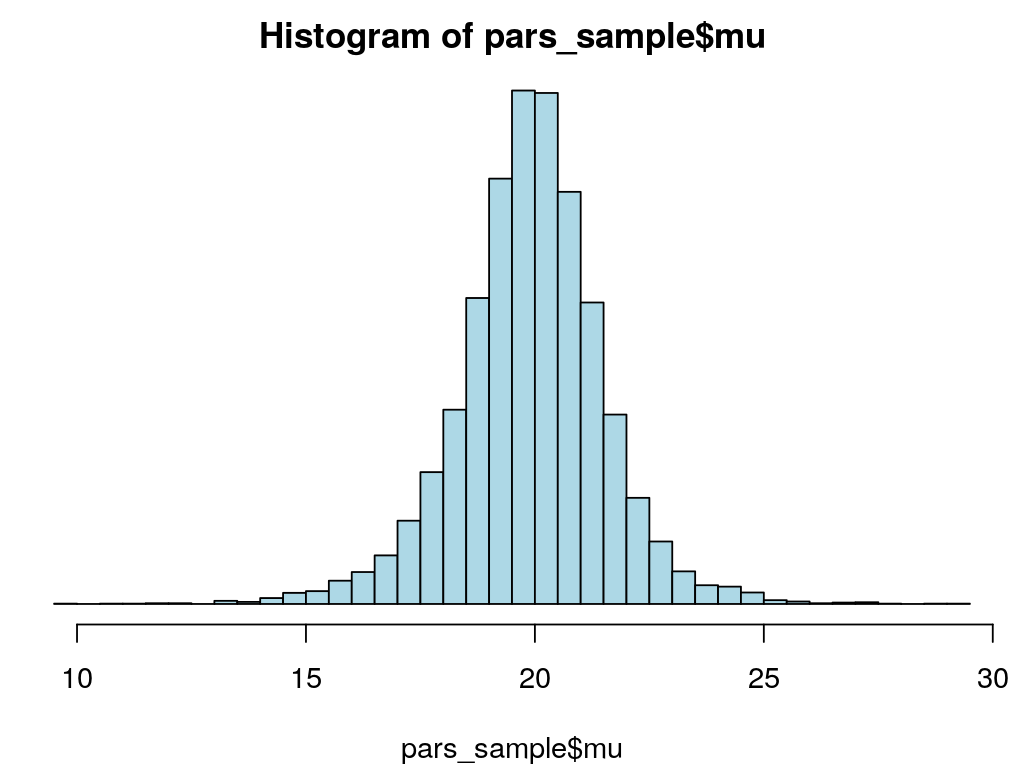
The probability distribution over the mean temperature
hist(pars_sample$mu, 30)
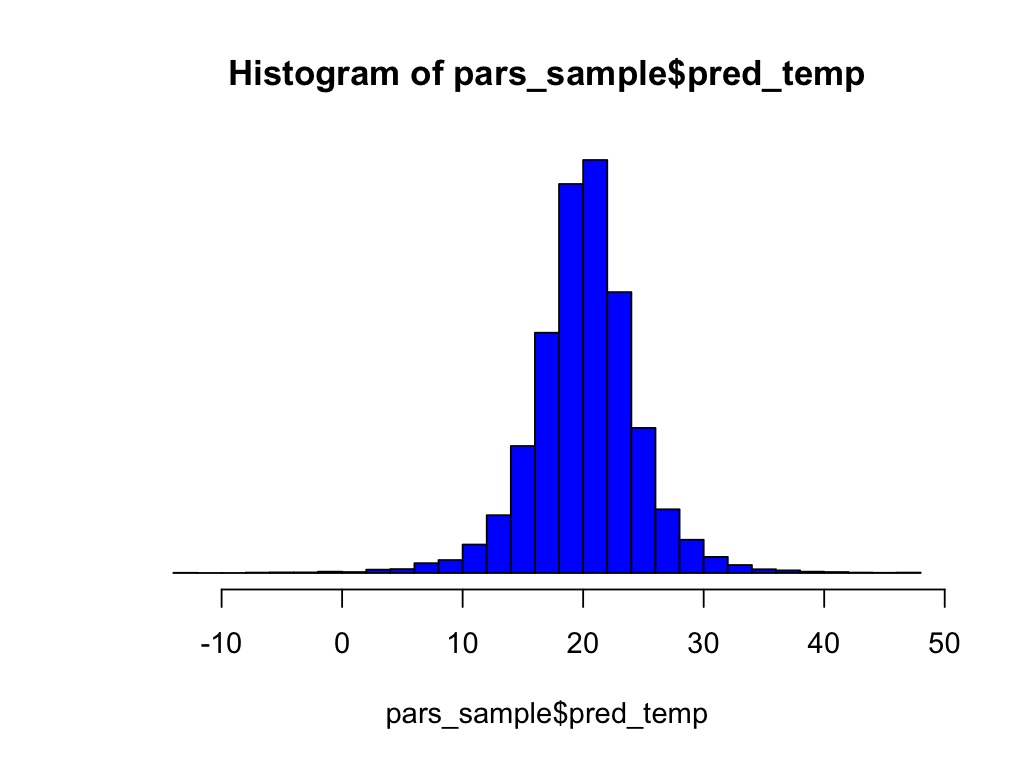
Is the temperature 18 or above on the 20th?
pred_temp <- rnorm(10000, mean = pars_sample$mu, sd = pars_sample$sigma)
hist(pred_temp, 30)