How Caching Works in Snowflake
Data Pipeline Automation in Snowflake

Emily Melhuish
Technical Curriculum Developer, Snowflake
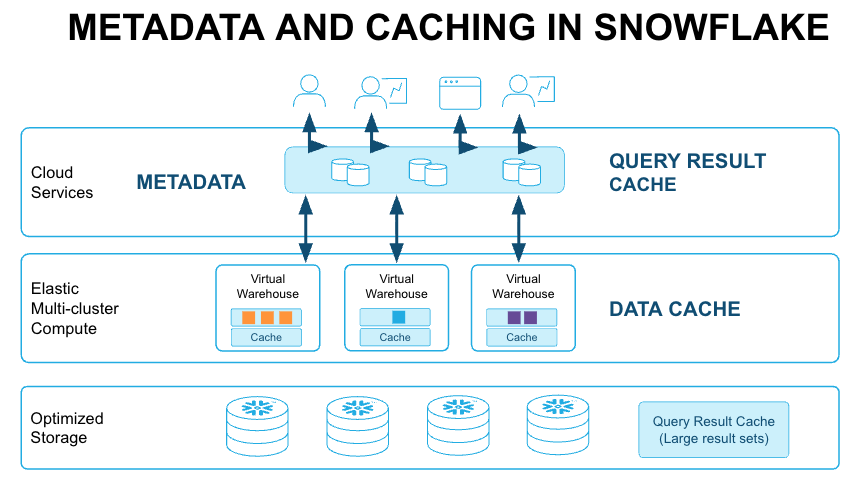
Three Caching Layers
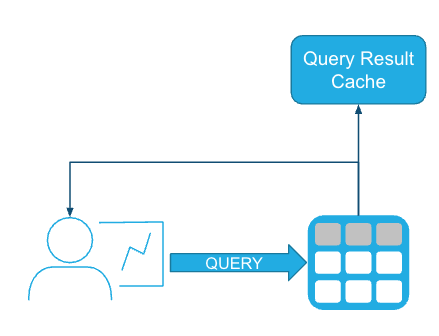
When the Result Cache is used (and when it isn't)
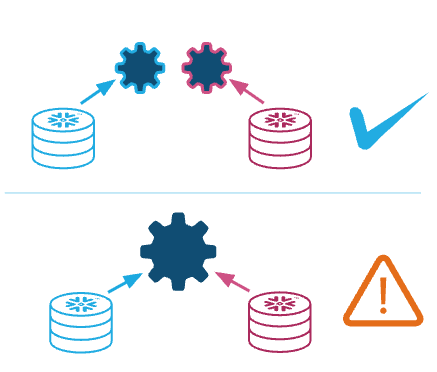
Warehouse cache and Metadata cache
Data Pipeline Automation in Snowflake
Emily Melhuish
Technical Curriculum Developer, Snowflake

