Data Unloading and Connectivity
Data Pipeline Automation in Snowflake

Emily Melhuish
Technical Curriculum Developer, Snowflake
The Unloading Use Case
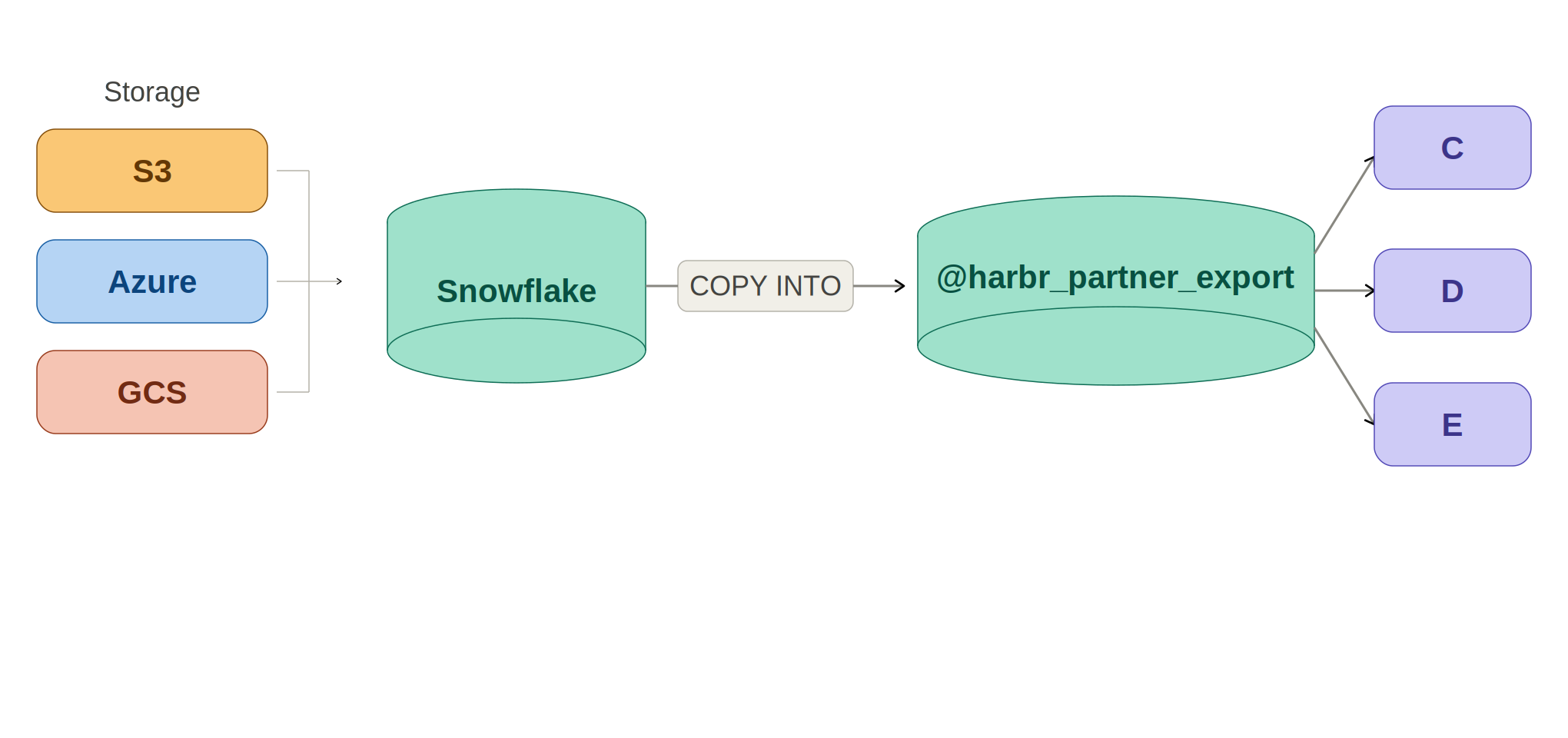
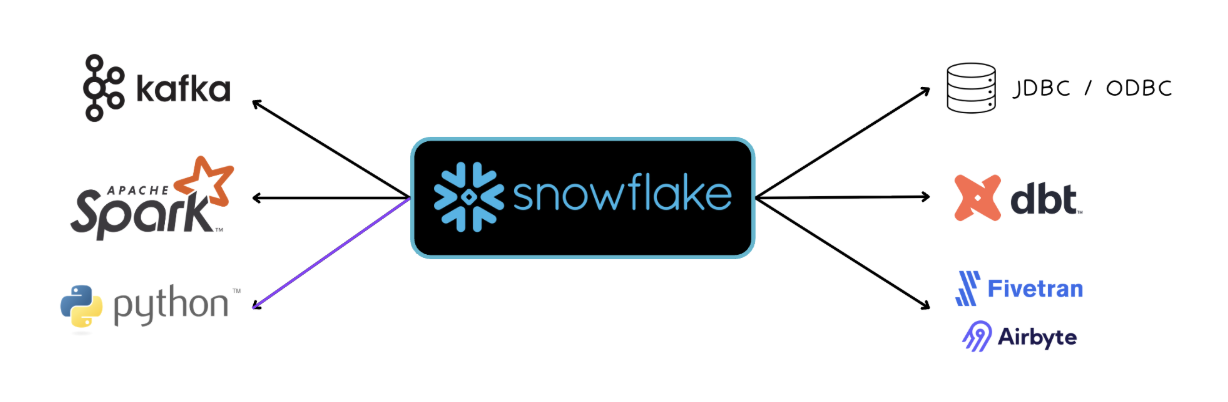
The Connectivity Landscape
Data Pipeline Automation in Snowflake
Emily Melhuish
Technical Curriculum Developer, Snowflake

