Stages, File Formats, and COPY INTO
Data Pipeline Automation in Snowflake

Emily Melhuish
Technical Curriculum Developer, Snowflake
Snowflake powers many workloads
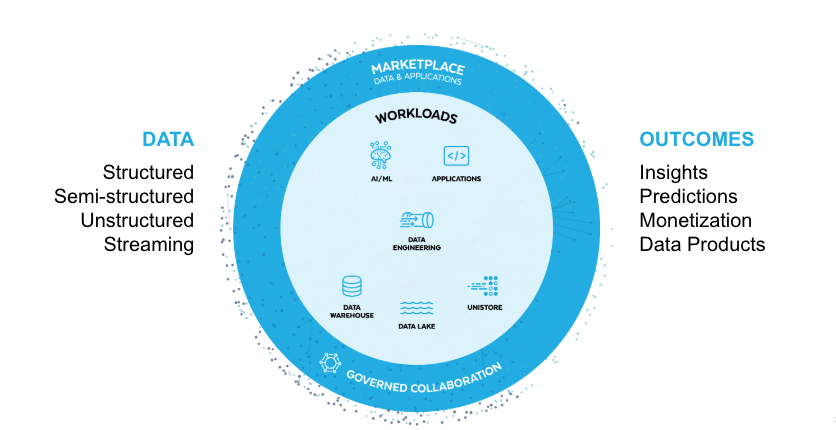
1 * Snowflake Learning Material
Example pipeline
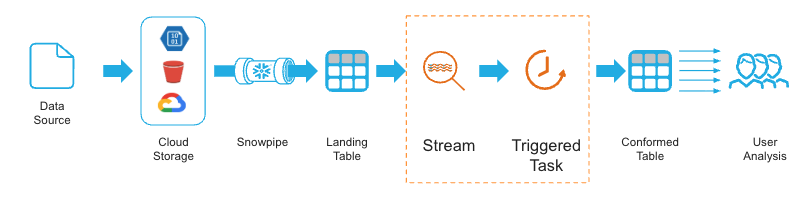
1 * Snowflake Learning Material
Meet Harbr

The Data Loading Problem
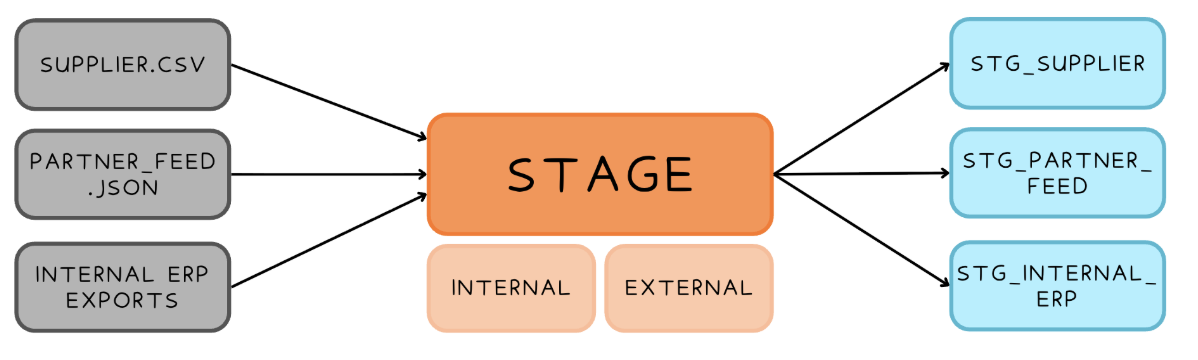
Stage = temporary storage location
Stage Types


