Window Functions
Data Pipeline Automation in Snowflake

Emily Melhuish
Technical Curriculum Developer, Snowflake
LAG and LEAD
Input

Output
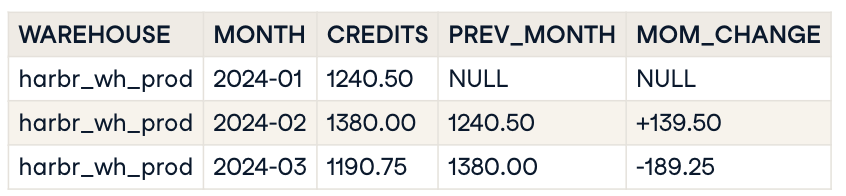
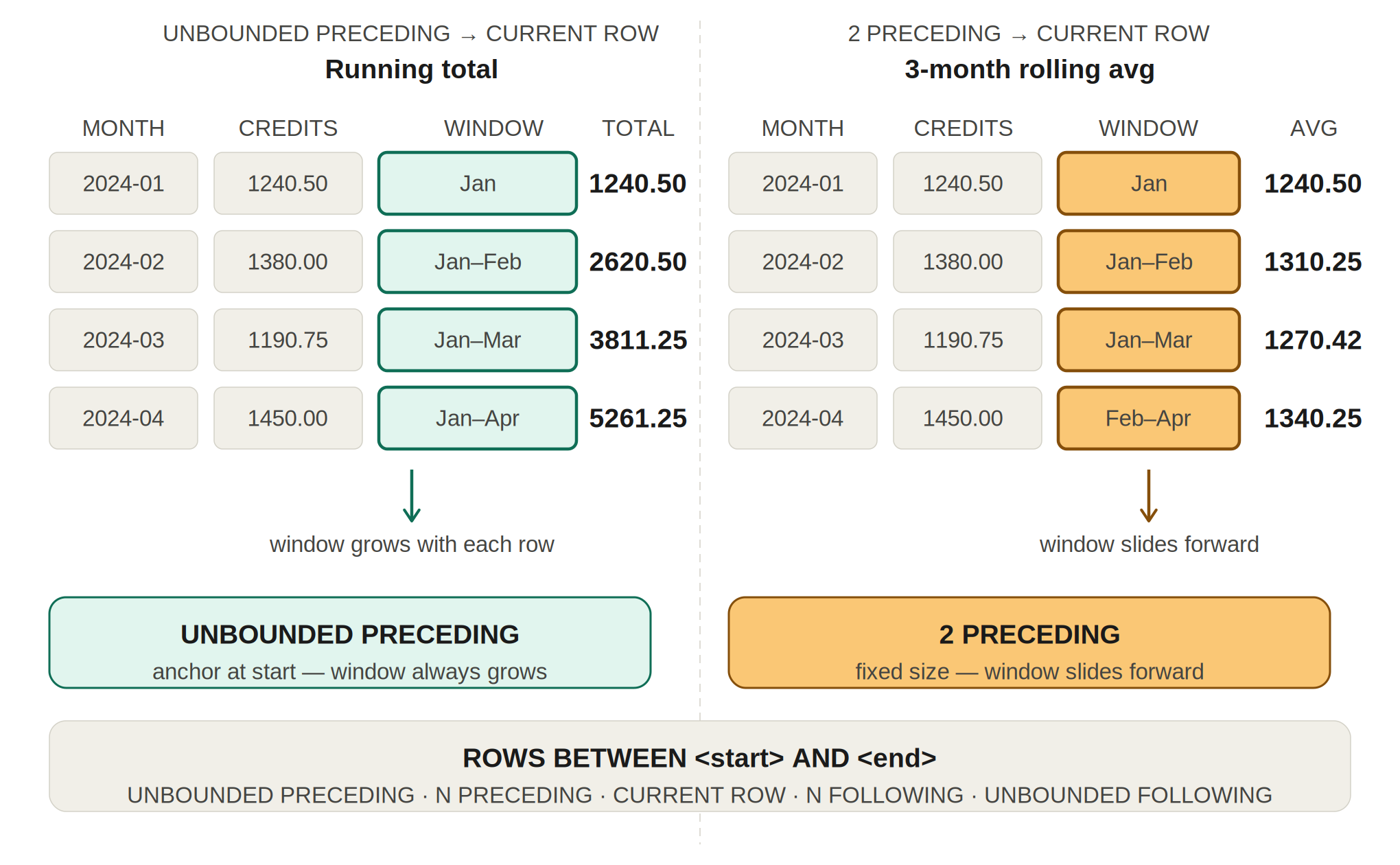
Running Totals and Rolling Averages
Data Pipeline Automation in Snowflake
Emily Melhuish
Technical Curriculum Developer, Snowflake
Input
Output

