Dynamic Tables
Data Pipeline Automation in Snowflake

Emily Melhuish
Technical Curriculum Developer, Snowflake
Dynamic Tables vs Streams and Tasks
Dynamic Tables:
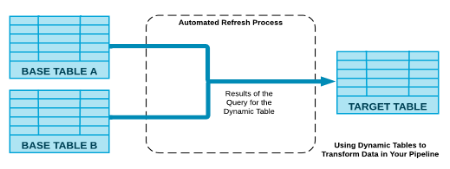
- Simplify data pipeline transformation using SQL declarative statements
- Automatic refresh process
- Snowflake detects, schedules and merges
Streams and tasks:
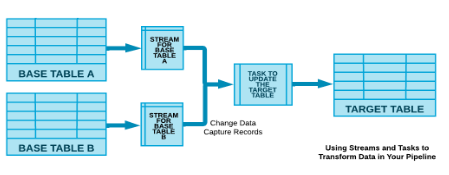
1 * Snowflake Learning Material
Chaining Dynamic Tables

- Each transformation is a separate dynamic table with its own query
- Refreshes propagate automatically through the chain
DOWNSTREAMlag defers to what the next table needs - no over-refreshing

