Tasks and DAG Orchestration
Data Pipeline Automation in Snowflake

Emily Melhuish
Technical Curriculum Developer, Snowflake
DAG-based Task Orchestration

- DAGs: Directed Acyclic Graph
- Root task holds the CRON schedule
- Child tasks declare their predecessor with
AFTER - Entire chain is centralized
- DAGs control when and in what order things run
Managing Task States
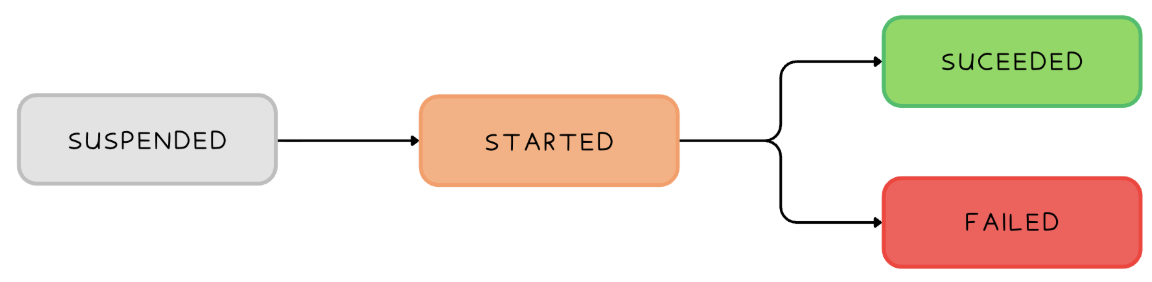
-- Activate a task
ALTER TASK mytask RESUME;
-- Pause a task
ALTER TASK mytask SUSPEND;
-- Execute a task
EXECUTE TASK mytask SUSPEND;
Tasks and Streams Combined
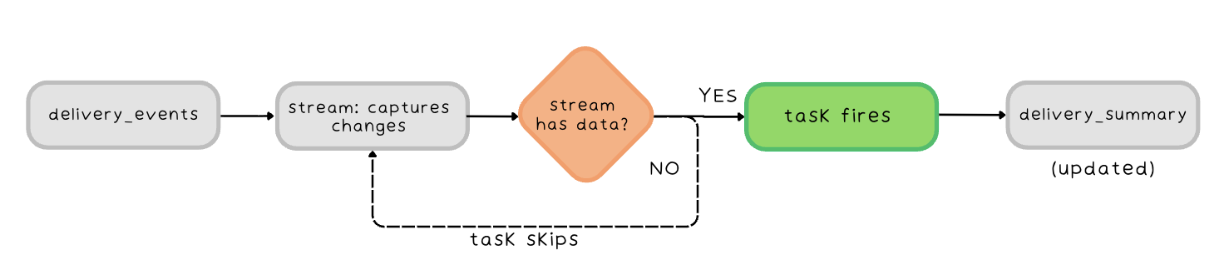
CREATE OR REPLACE TASK logistics.process_delivery_events
WAREHOUSE = compute_wh
SCHEDULE = '5 minute'
WHEN SYSTEM$STREAM_HAS_DATA('logistics.delivery_events_stream')
AS
INSERT INTO logistics.processed_events
SELECT * FROM logistics.delivery_events_stream;

