External and Iceberg Tables
Data Pipeline Automation in Snowflake

Emily Melhuish
Technical Curriculum Developer, Snowflake
What is an External Table?
Use case:
- Harbr receives files from dozens of partners daily
- Loading them into Snowflake doesn't make sense

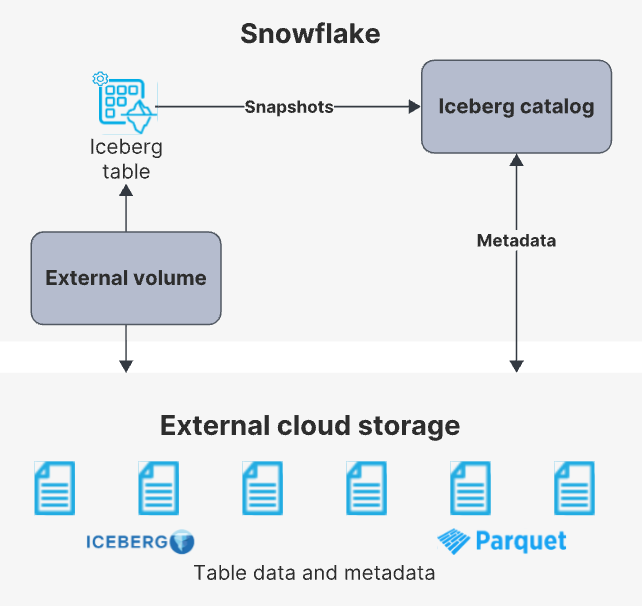
Apache Iceberg Tables
1 * Snowflake learning material

