User-Defined Functions and Stored Procedures
Data Pipeline Automation in Snowflake

Emily Melhuish
Technical Curriculum Developer, Snowflake
What is a UDF?
![]()
UDFs in the Pipeline
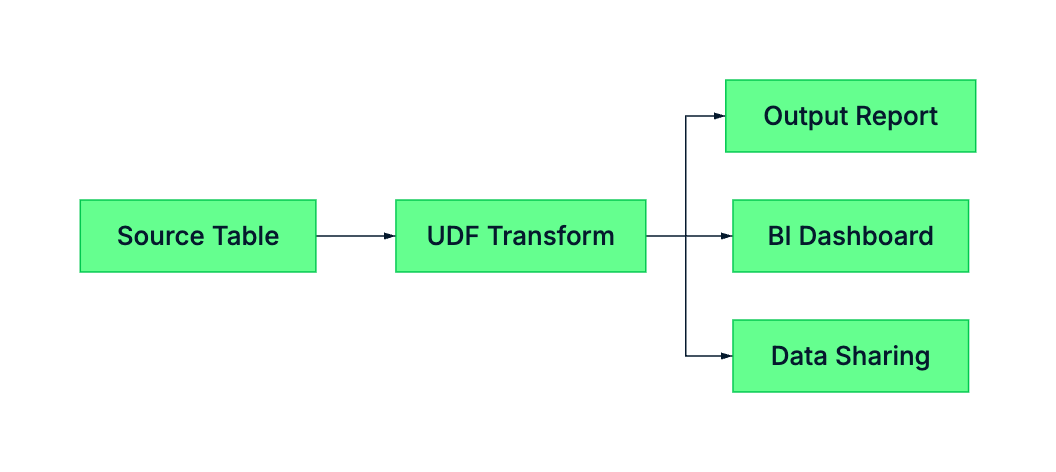
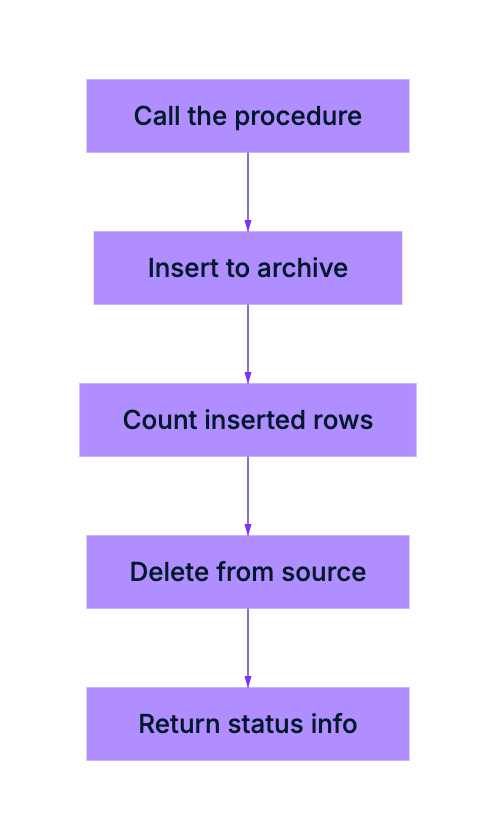
What is a Stored Procedure?
Data Pipeline Automation in Snowflake
Emily Melhuish
Technical Curriculum Developer, Snowflake
![]()

