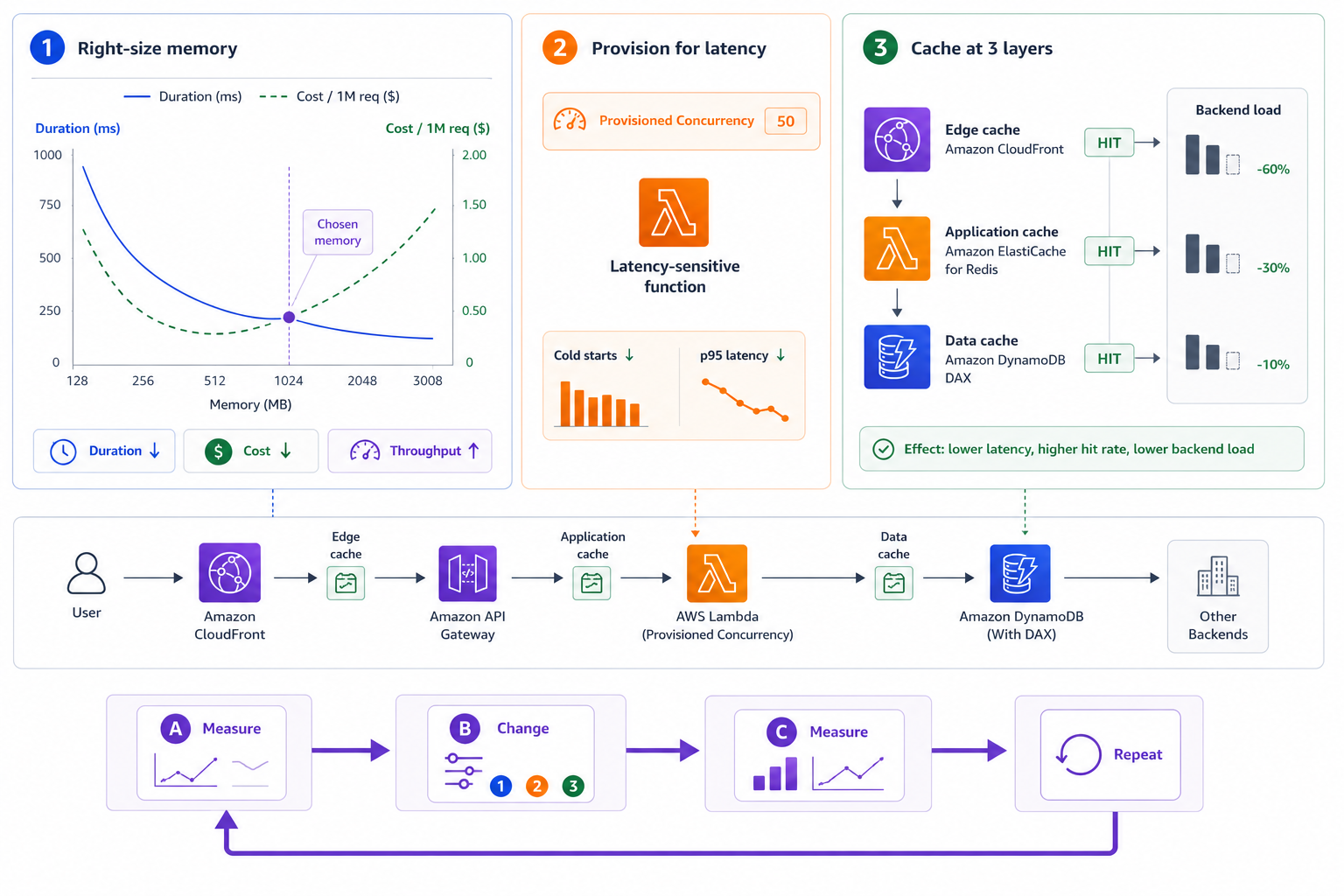
Performance and resource optimization
Deploying Applications on AWS

Dunieski Otano
Amazon Web Services Solutions Architect
Slow and expensive
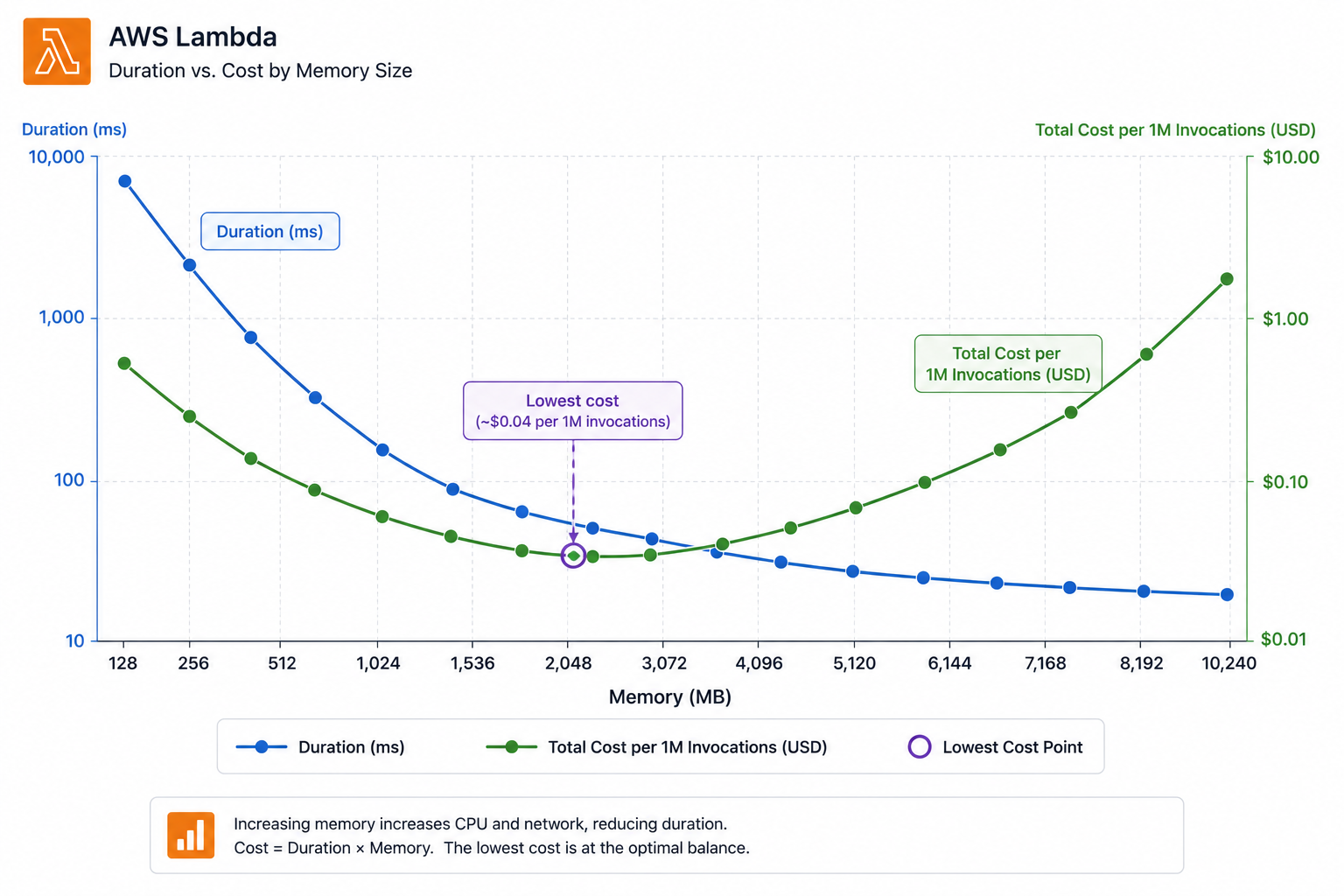
Right-sizing memory with the duration-cost curve
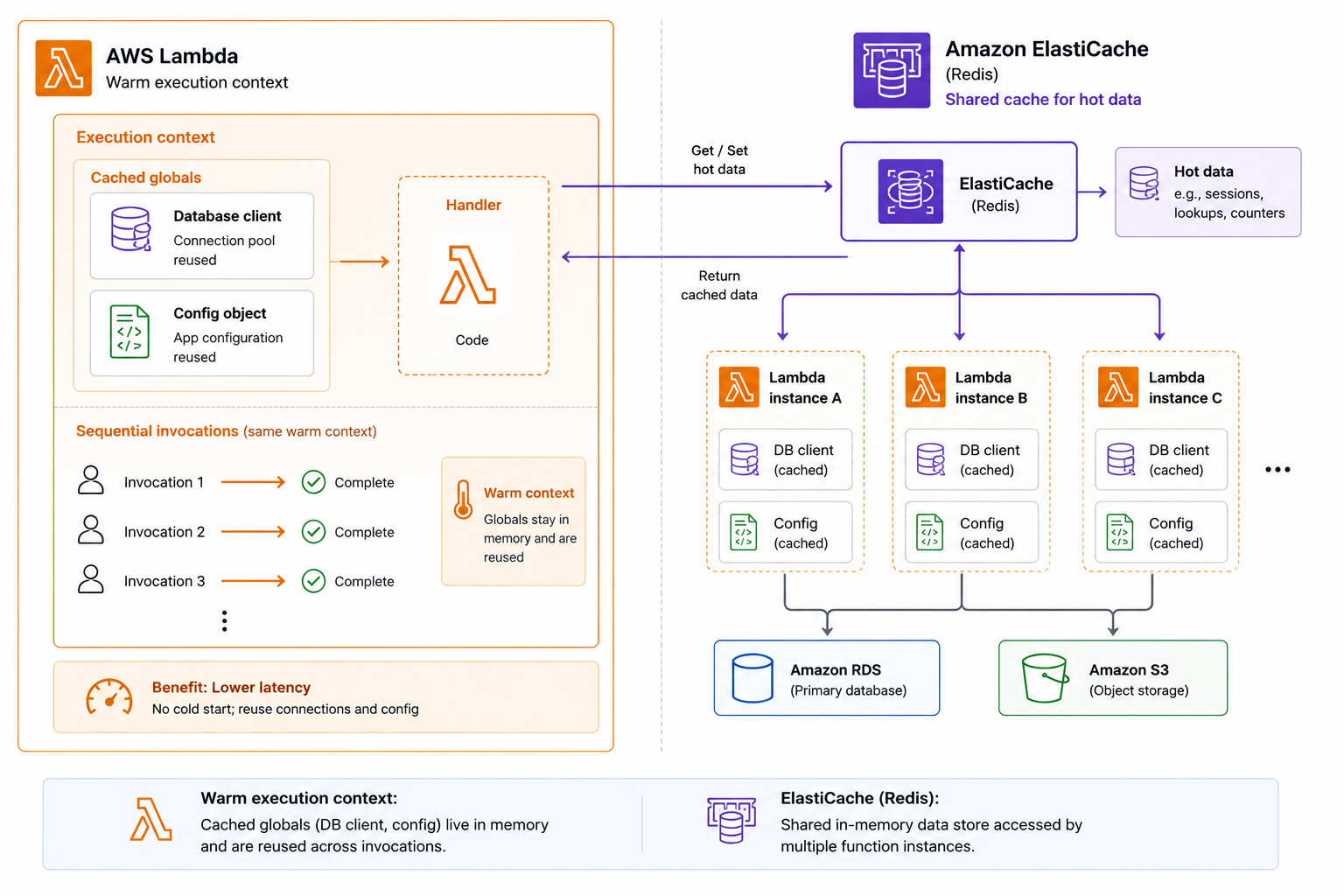
Application-level caching
CloudFront caching at the edge
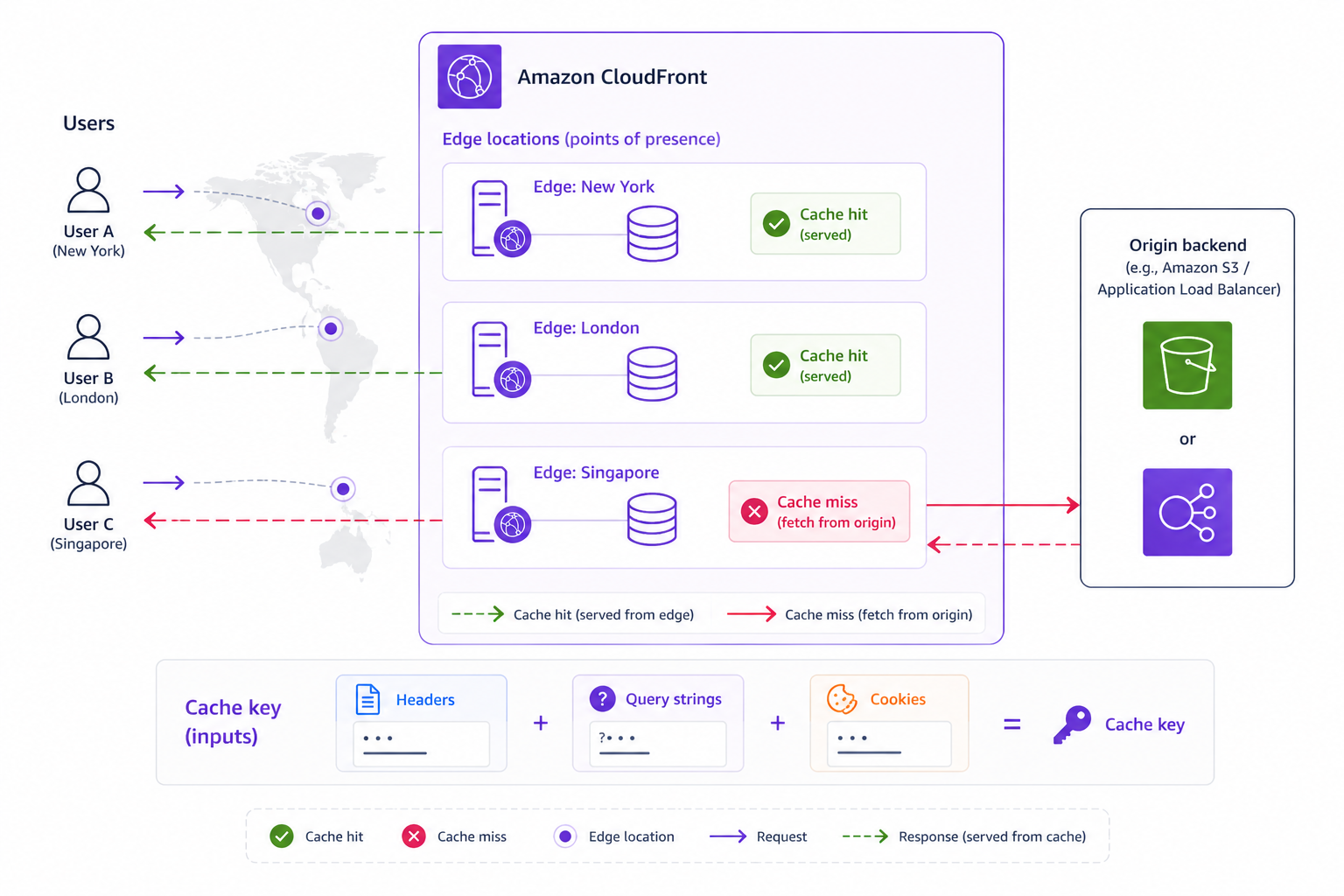
Choosing the right cache layer
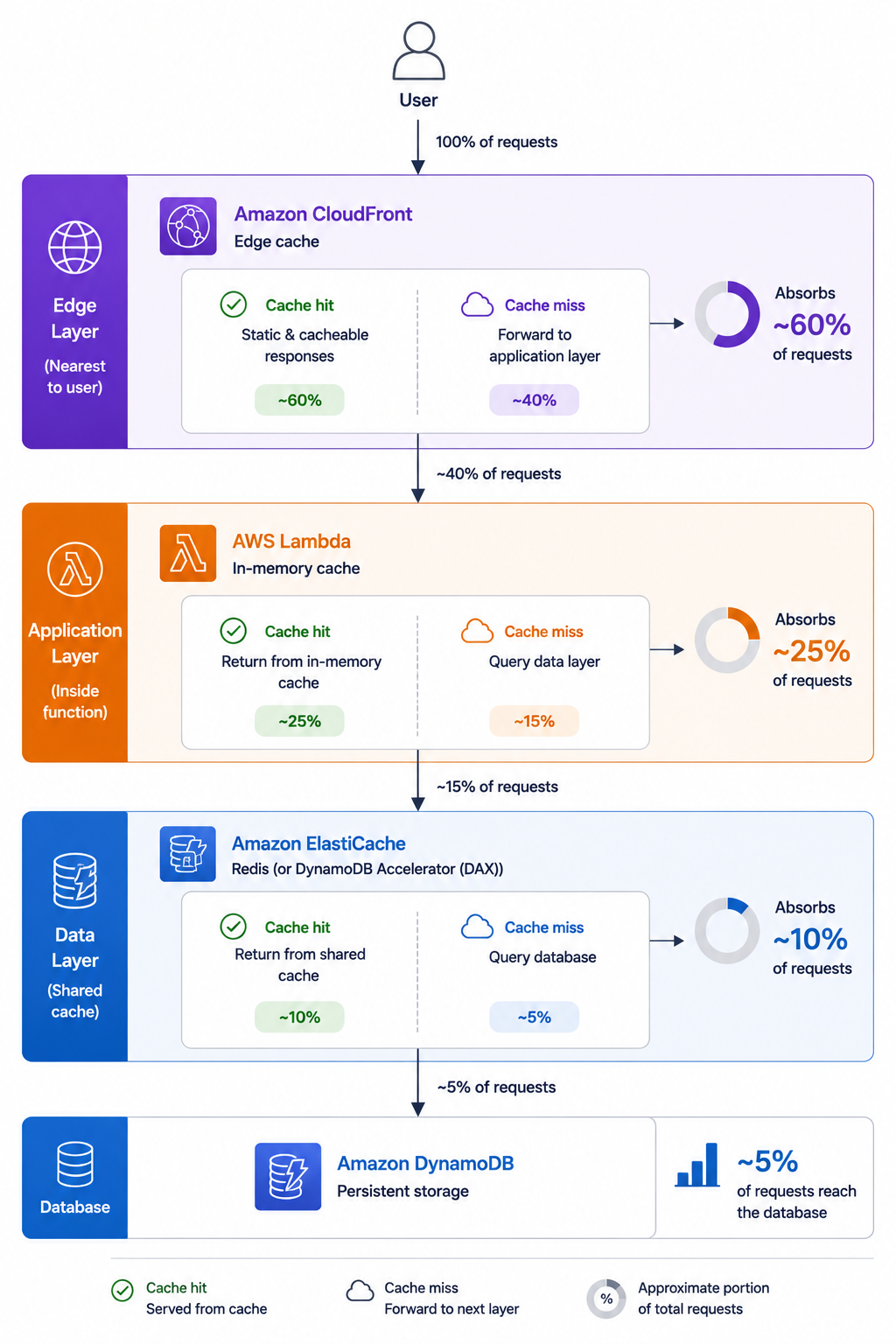
Putting optimization together