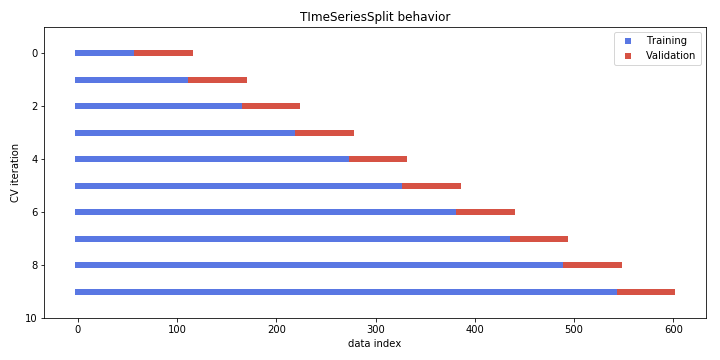
Cross-validating timeseries data
Machine Learning for Time Series Data in Python

Chris Holdgraf
Fellow, Berkeley Institute for Data Science
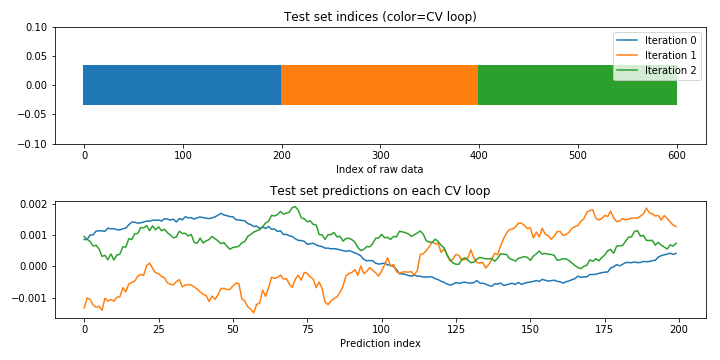
Visualizing KFold CV behavior
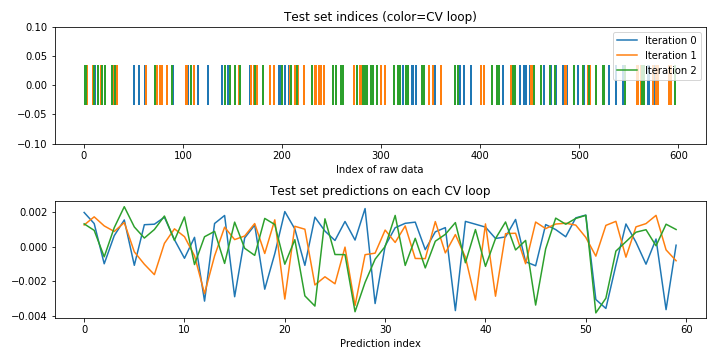
Visualizing shuffled CV behavior
Visualizing the TimeSeriesSplit cross validation iterator