Choosing the Algorithm
Feature Engineering with PySpark

John Hogue
Lead Data Scientist, General Mills
Spark ML Landscape

Spark ML Landscape
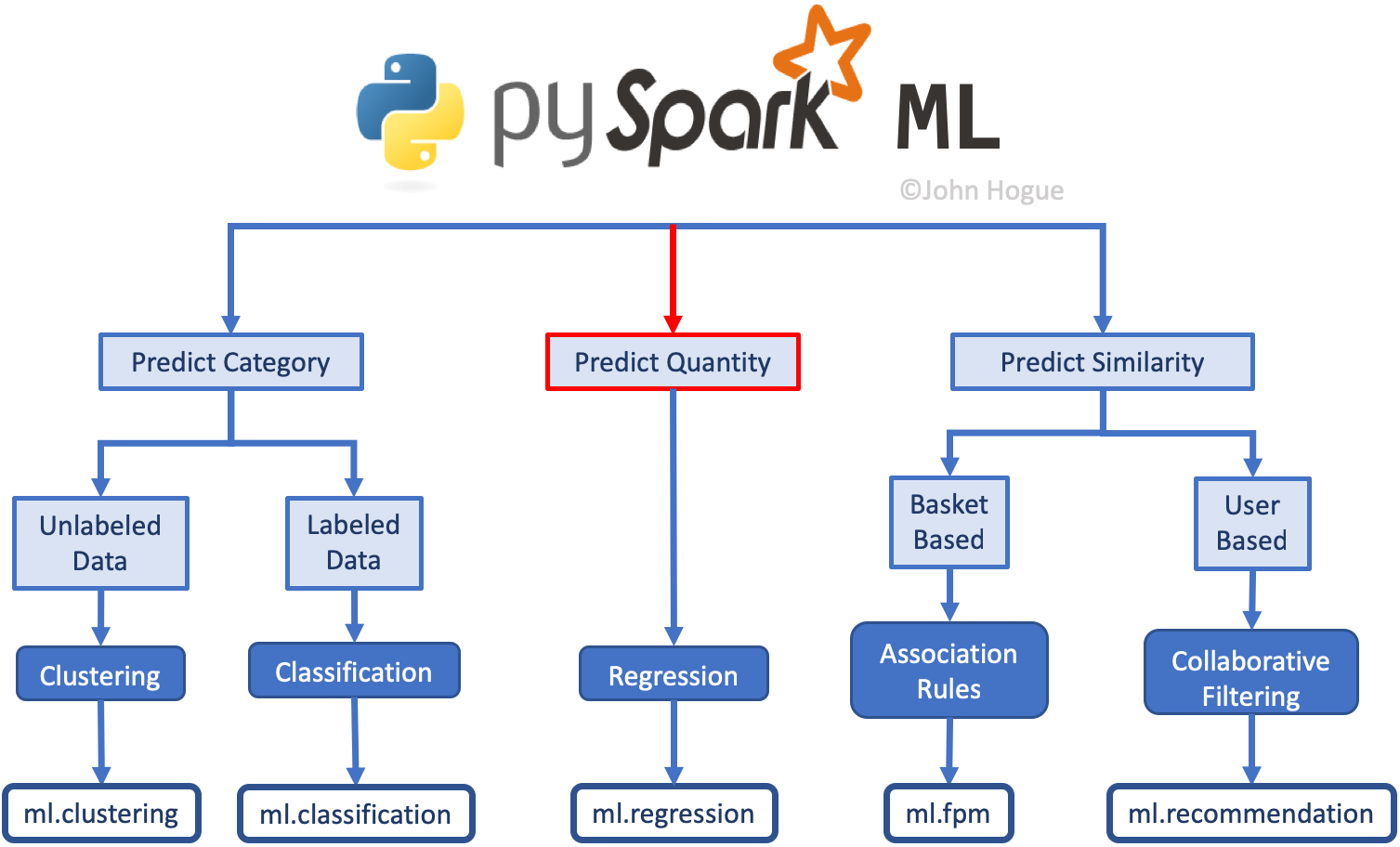
Spark ML Landscape
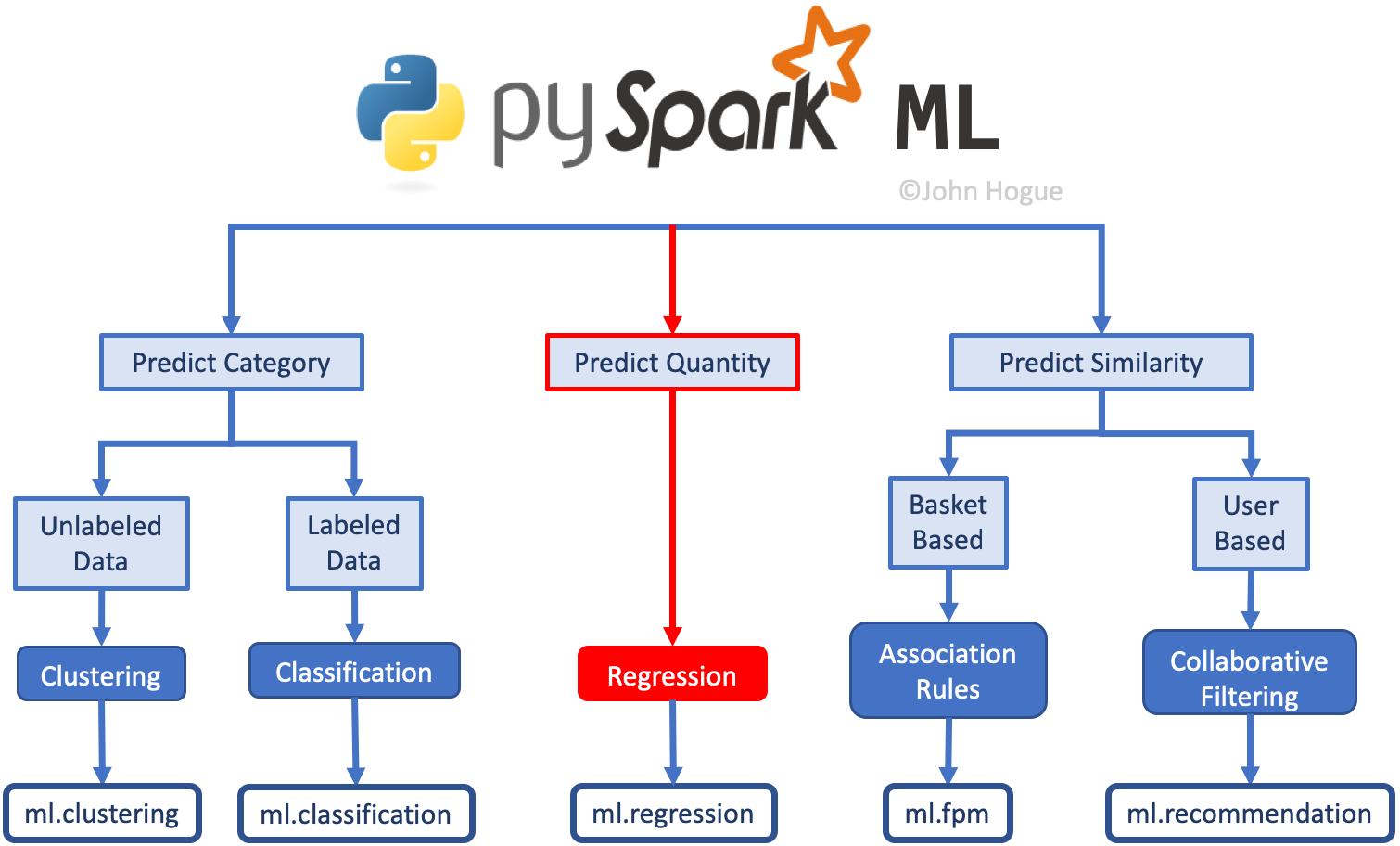
Spark ML Landscape
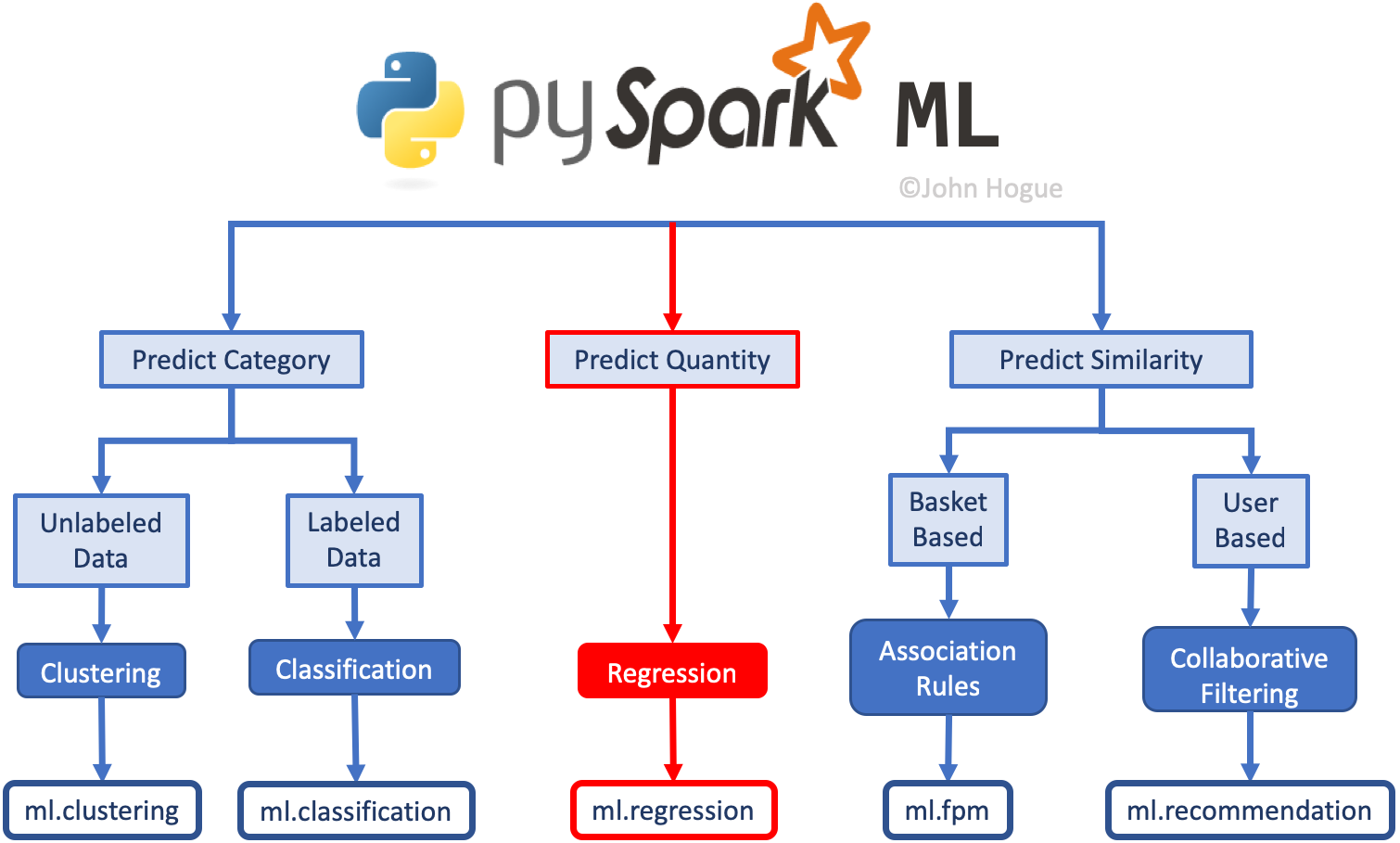
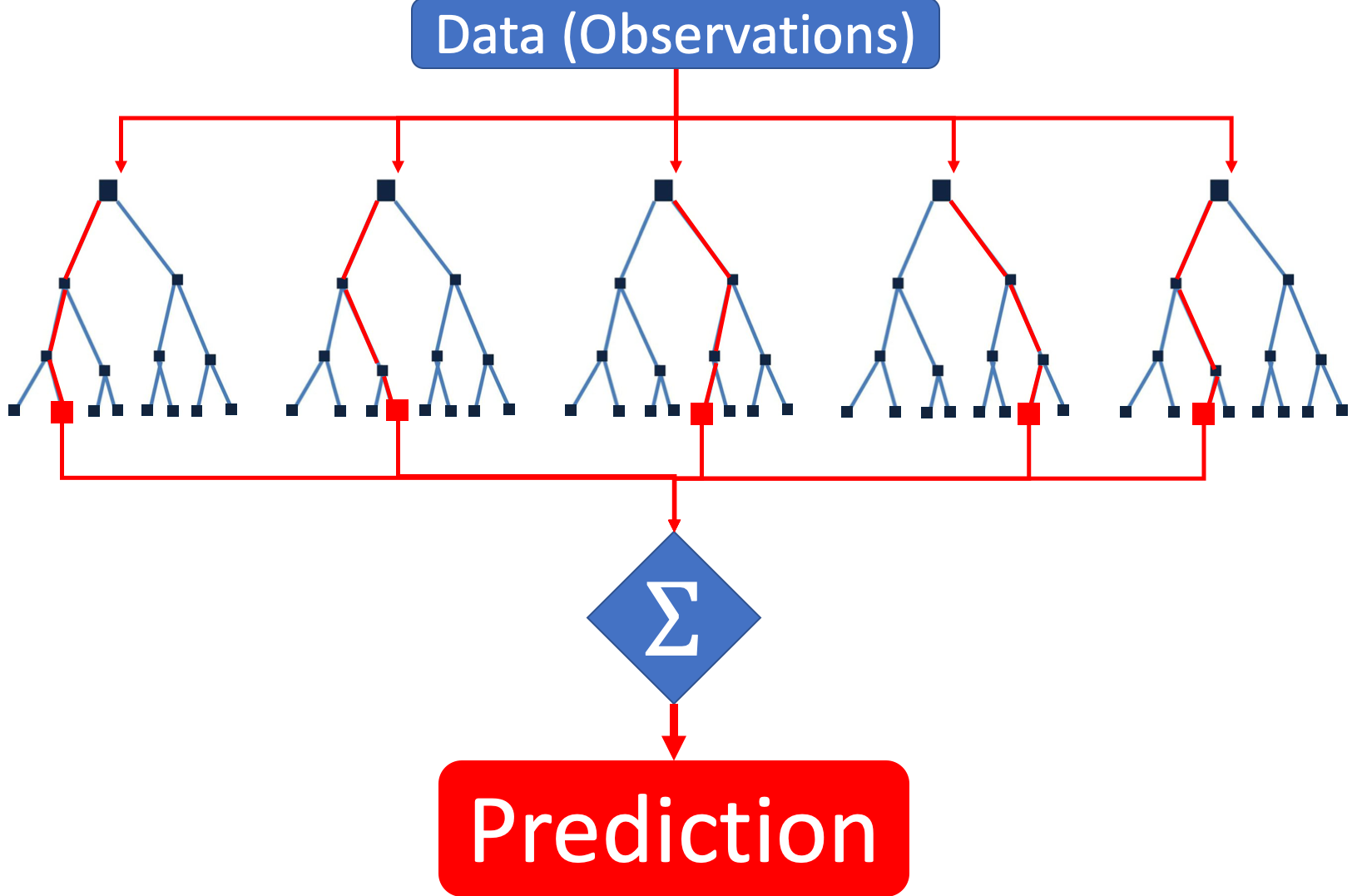
Feature Engineering with PySpark
John Hogue
Lead Data Scientist, General Mills


