Dropping Data
Feature Engineering with PySpark

John Hogue
Lead Data Scientist, General Mills
Where can data go bad?

Outlier Filtering
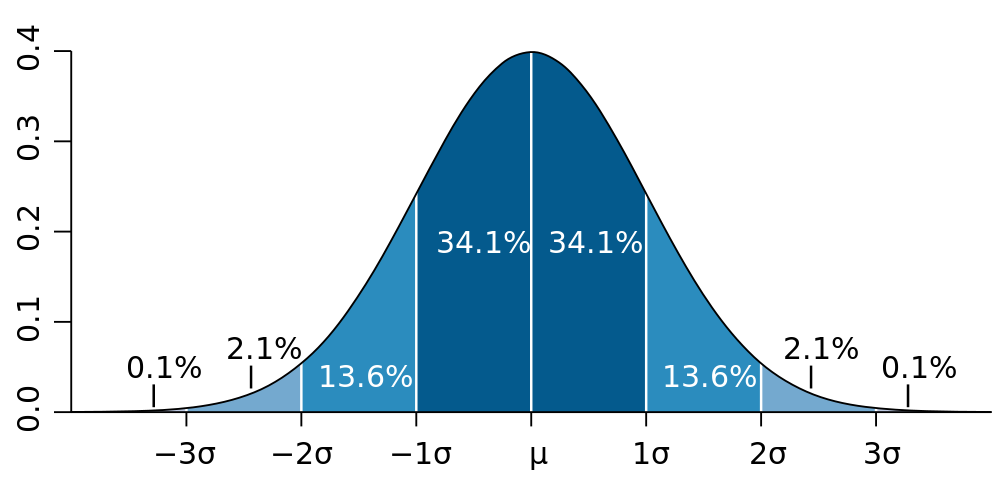
Filter data to within three standard deviations (3σ) of the mean (μ)
Feature Engineering with PySpark
John Hogue
Lead Data Scientist, General Mills
Filter data to within three standard deviations (3σ) of the mean (μ)

