Getting More Data
Feature Engineering with PySpark

John Hogue
Lead Data Scientist, General Mills
Thoughts on External Data Sets
PROS
- Add important predictors
- Supplement/replace values
- Cheap or easy to obtain
CONS
- May 'bog' analysis down
- Easy to induce data leakage
- Become data set subject matter expert
![]()
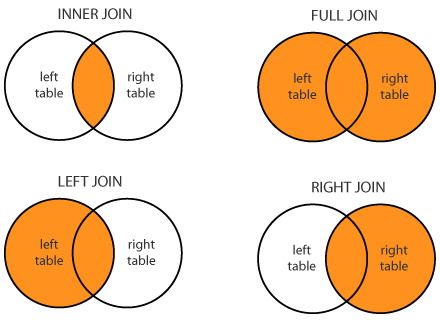
About Joins