Visually Inspecting Data
Feature Engineering with PySpark

John Hogue
Lead Data Scientist, General Mills
seaborn: statistical data visualization
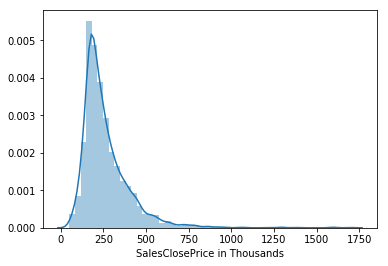
Distribution plot of sales closing price
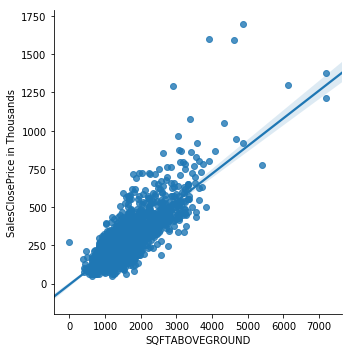
Linear model plot between SQFT above ground and sales price
Feature Engineering with PySpark
John Hogue
Lead Data Scientist, General Mills

