Adjusting Data
Feature Engineering with PySpark

John Hogue
Lead Data Scientist, General Mills
Why Transform Data?

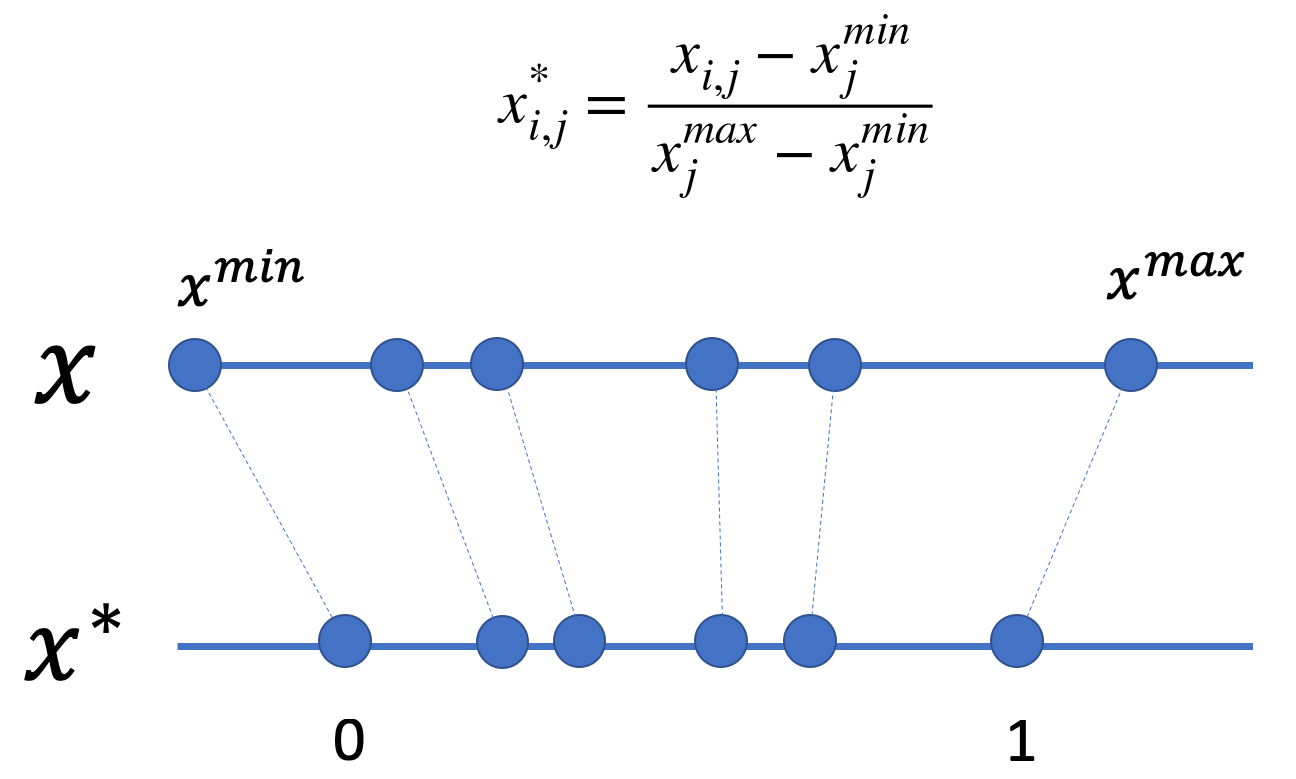
What is MinMax Scaling
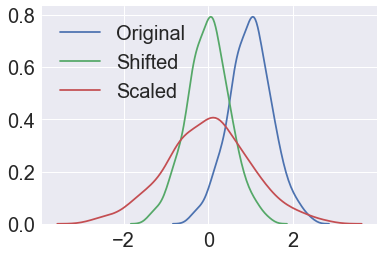
What is Standardization?
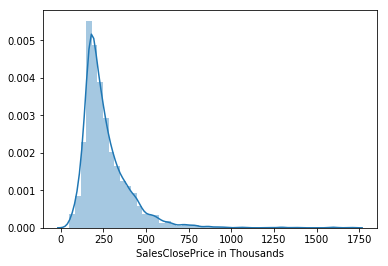
What is Log Scaling
Unscaled distribution
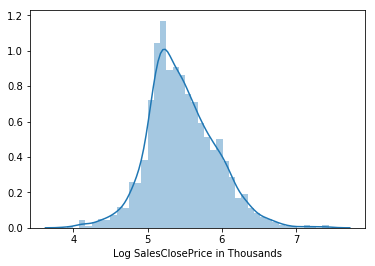
Log-scaled distribution
Feature Engineering with PySpark
John Hogue
Lead Data Scientist, General Mills
Unscaled distribution
Log-scaled distribution

