Time Features
Feature Engineering with PySpark

John Hogue
Lead Data Scientist, General Mills
The Cyclical Nature of Things

Choosing the Right Level
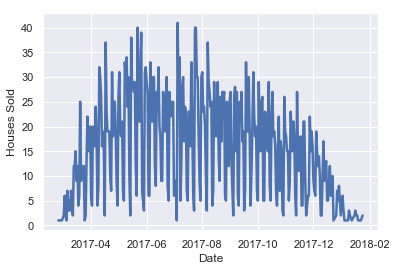
Choosing the Right Level
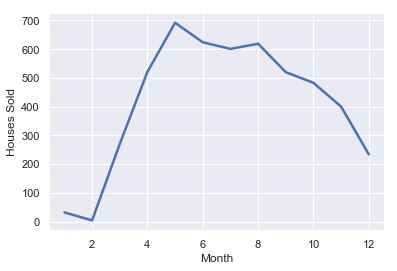
Basic Time Based Metrics

from pyspark.sql.functions import datediff
# Calculate difference between two date fields
df.withColumn('DAYSONMARKET', datediff('OFFMARKETDATE', 'LISTDATE'))
Lagging Features


