Diagnosing Bias and Variance Problems
Machine Learning with Tree-Based Models in Python

Elie Kawerk
Data Scientist
Estimating the Generalization Error
How do we estimate the generalization error of a model?
Cannot be done directly because:
$f$ is unknown,
usually you only have one dataset,
noise is unpredictable.
Estimating the Generalization Error
Solution:
- split the data to training and test sets,
- fit $\hat{f}$ to the training set,
- evaluate the error of $\hat{f}$ on the unseen test set.
- generalization error of $\hat{f} \approx$ test set error of $\hat{f}$.
Better Model Evaluation with Cross-Validation
Test set should not be touched until we are confident about $\hat{f}$'s performance.
Evaluating $\hat{f}$ on training set: biased estimate, $\hat{f}$ has already seen all training points.
Solution $\rightarrow$ Cross-Validation (CV):
K-Fold CV,
Hold-Out CV.
K-Fold CV
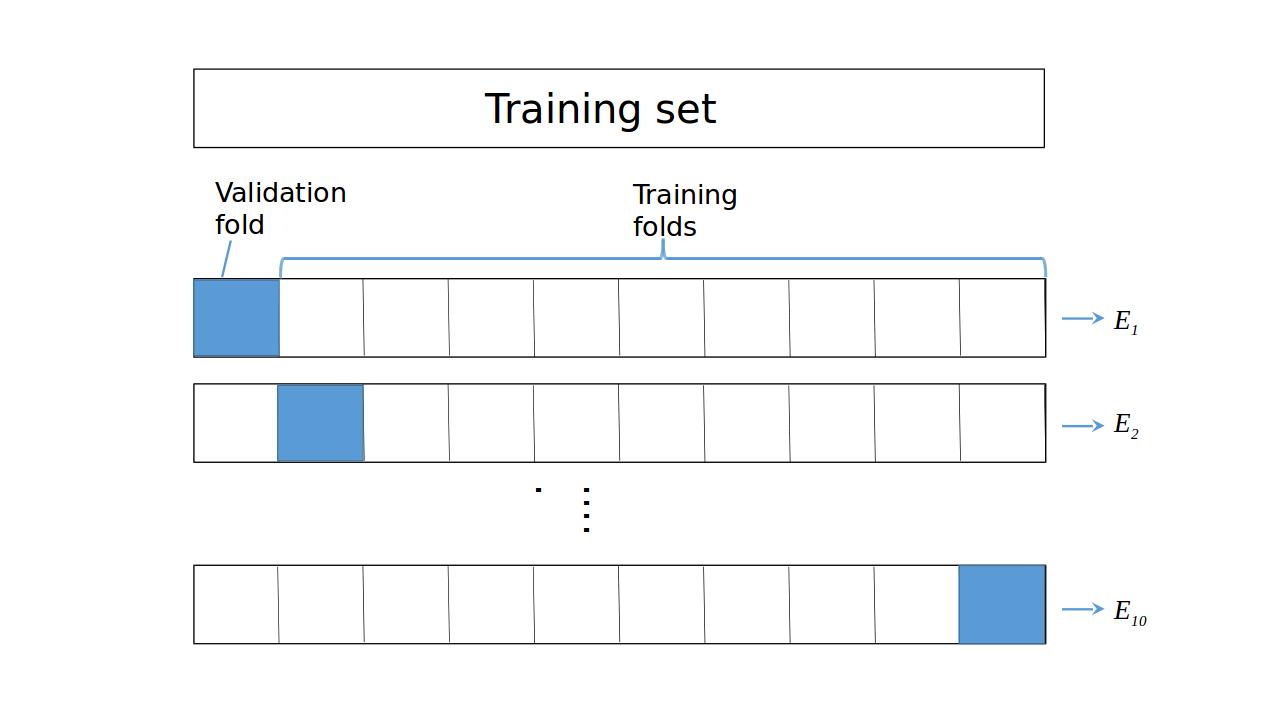
K-Fold CV
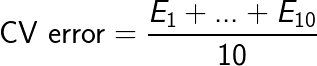
Diagnose Variance Problems
If $\hat{f}$ suffers from high variance:
CV error of $\hat{f}$ > training set error of $\hat{f}$.
- $\hat{f}$ is said to overfit the training set. To remedy overfitting:
- decrease model complexity,
- for ex: decrease max depth, increase min samples per leaf, ...
- gather more data, ..
Diagnose Bias Problems
if $\hat{f}$ suffers from high bias:
CV error of $\hat{f} \approx$ training set error of $\hat{f} >>$ desired error.
$\hat{f}$ is said to underfit the training set. To remedy underfitting:
- increase model complexity
- for ex: increase max depth, decrease min samples per leaf, ...
- gather more relevant features
K-Fold CV in sklearn on the Auto Dataset
from sklearn.tree import DecisionTreeRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error as MSE from sklearn.model_selection import cross_val_score# Set seed for reproducibility SEED = 123 # Split data into 70% train and 30% test X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3, random_state=SEED)# Instantiate decision tree regressor and assign it to 'dt' dt = DecisionTreeRegressor(max_depth=4, min_samples_leaf=0.14, random_state=SEED)
K-Fold CV in sklearn on the Auto Dataset
# Evaluate the list of MSE ontained by 10-fold CV # Set n_jobs to -1 in order to exploit all CPU cores in computation MSE_CV = - cross_val_score(dt, X_train, y_train, cv= 10, scoring='neg_mean_squared_error', n_jobs = -1)# Fit 'dt' to the training set dt.fit(X_train, y_train) # Predict the labels of training set y_predict_train = dt.predict(X_train) # Predict the labels of test set y_predict_test = dt.predict(X_test)
# CV MSE
print('CV MSE: {:.2f}'.format(MSE_CV.mean()))
CV MSE: 20.51
# Training set MSE
print('Train MSE: {:.2f}'.format(MSE(y_train, y_predict_train)))
Train MSE: 15.30
# Test set MSE
print('Test MSE: {:.2f}'.format(MSE(y_test, y_predict_test)))
Test MSE: 20.92
Let's practice!
Machine Learning with Tree-Based Models in Python

