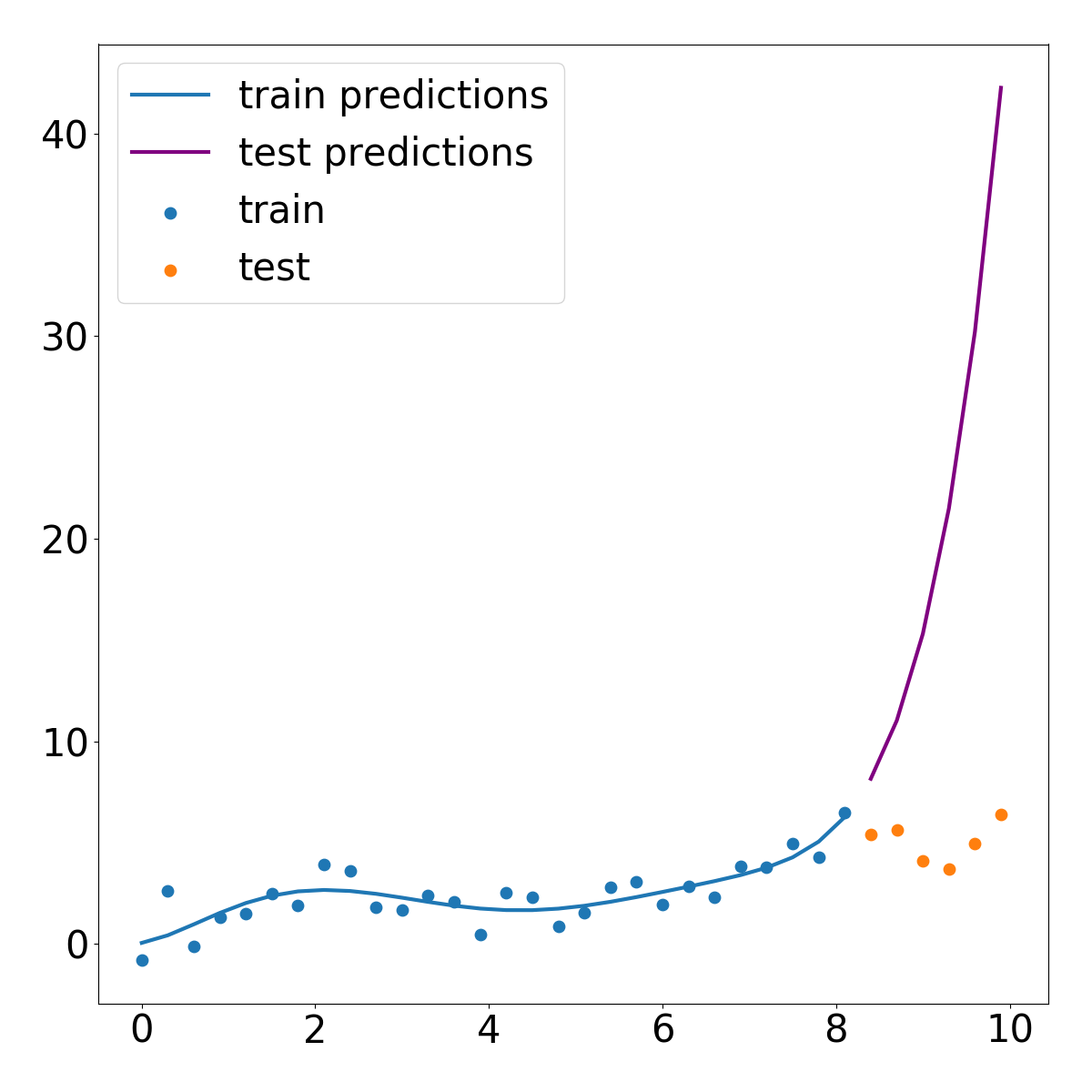
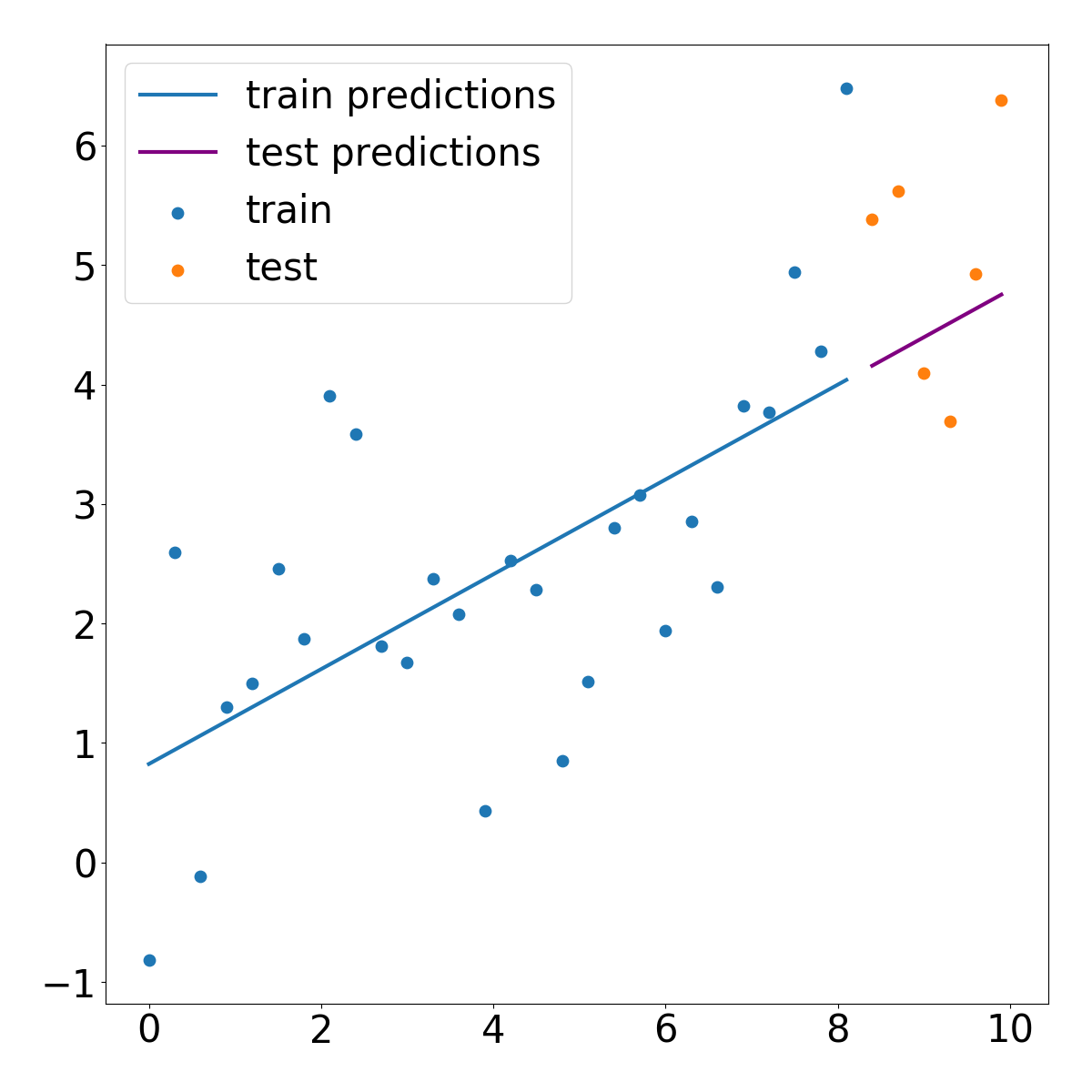
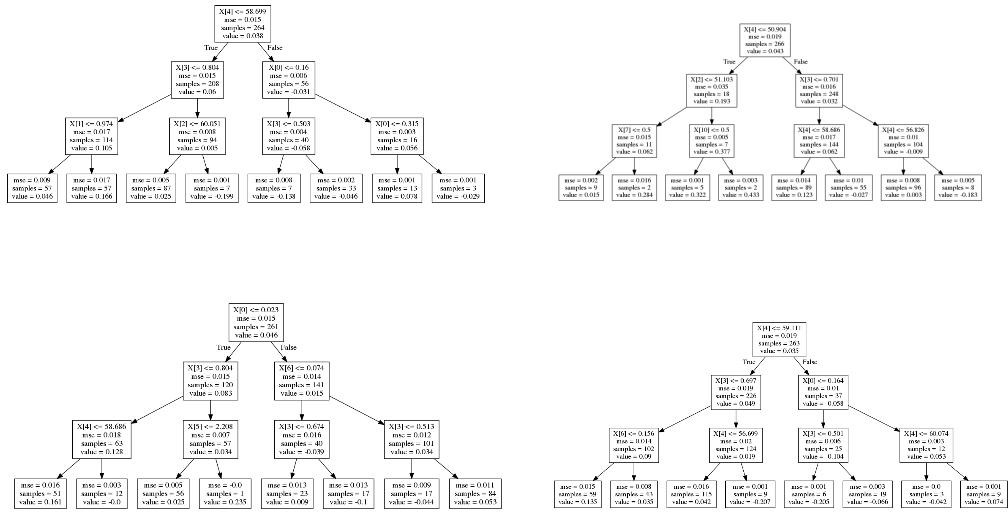
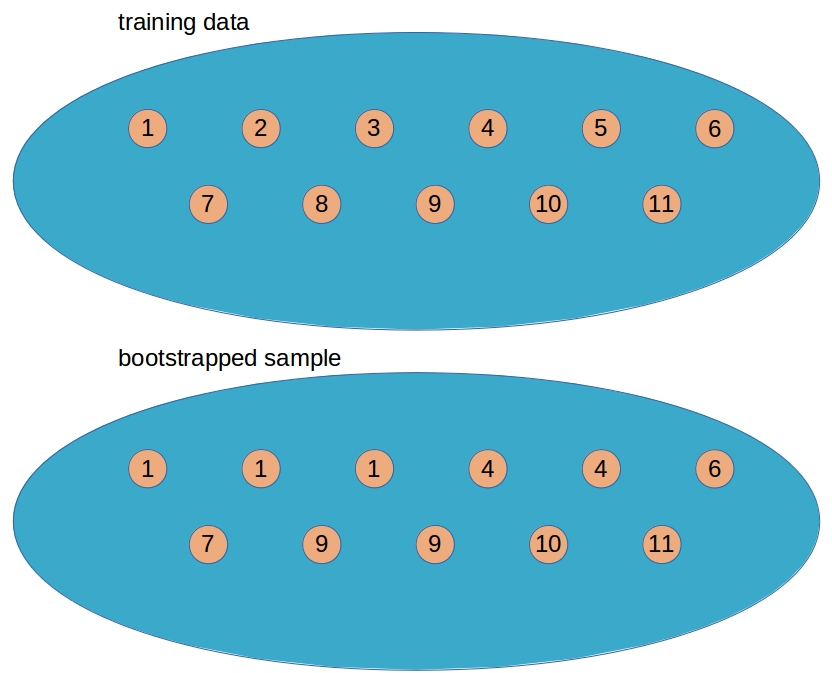
test_scores = []
# loop through the parameter grid, set hyperparameters, save the scores
for g in ParameterGrid(grid):
rfr.set_params(**g) # ** is "unpacking" the dictionary
rfr.fit(train_features, train_targets)
test_scores.append(rfr.score(test_features, test_targets))
# find best hyperparameters from the test score and print
best_idx = np.argmax(test_scores)
print(test_scores[best_idx])
print(ParameterGrid(grid)[best_idx])