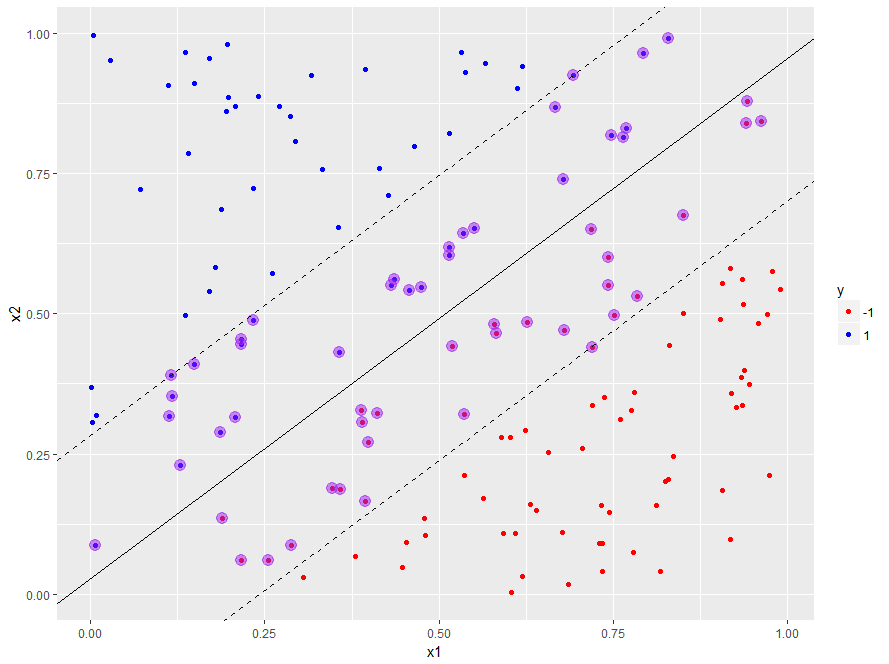
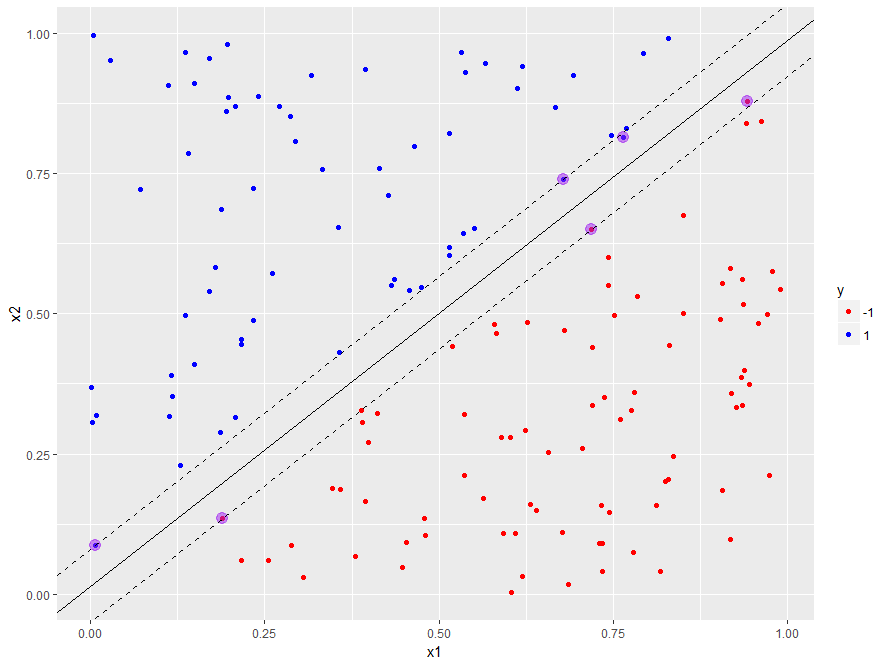
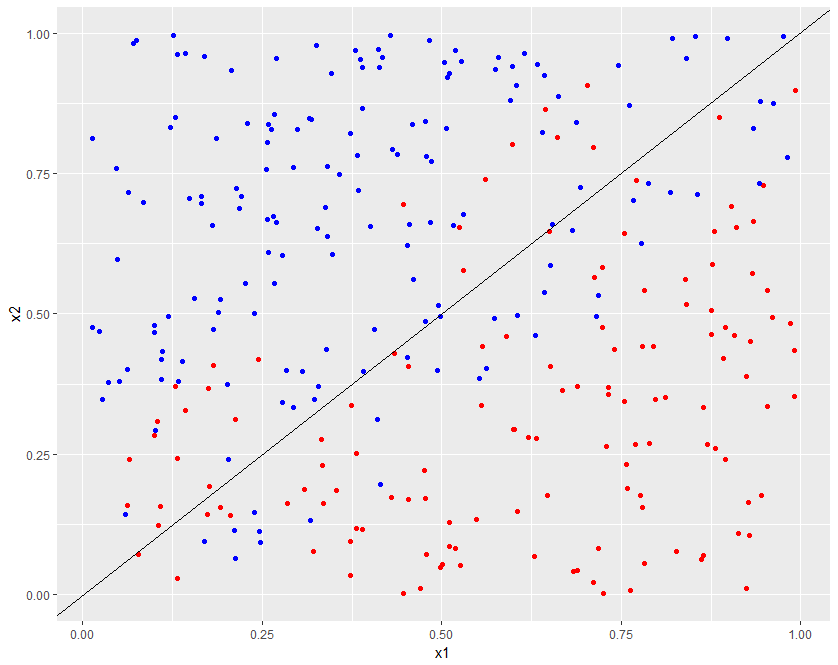
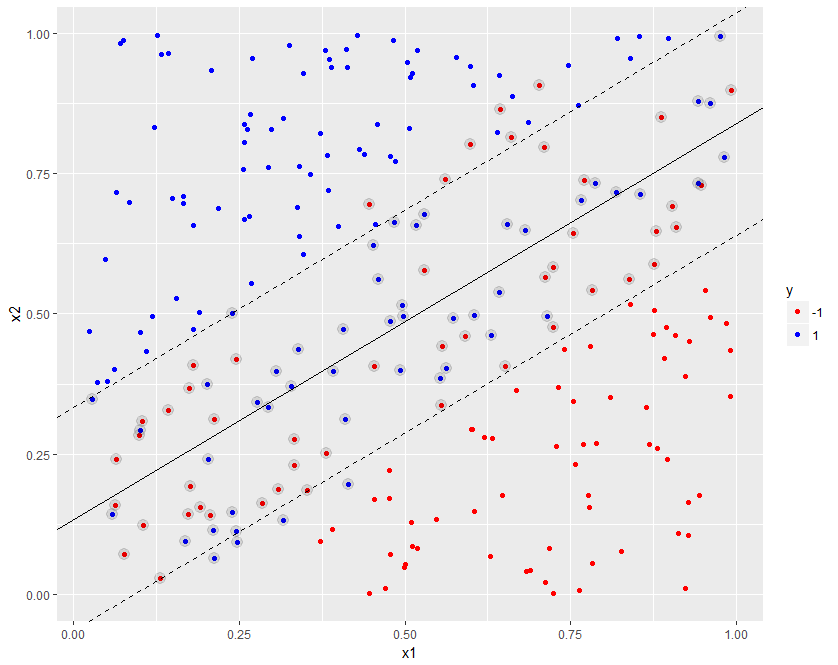
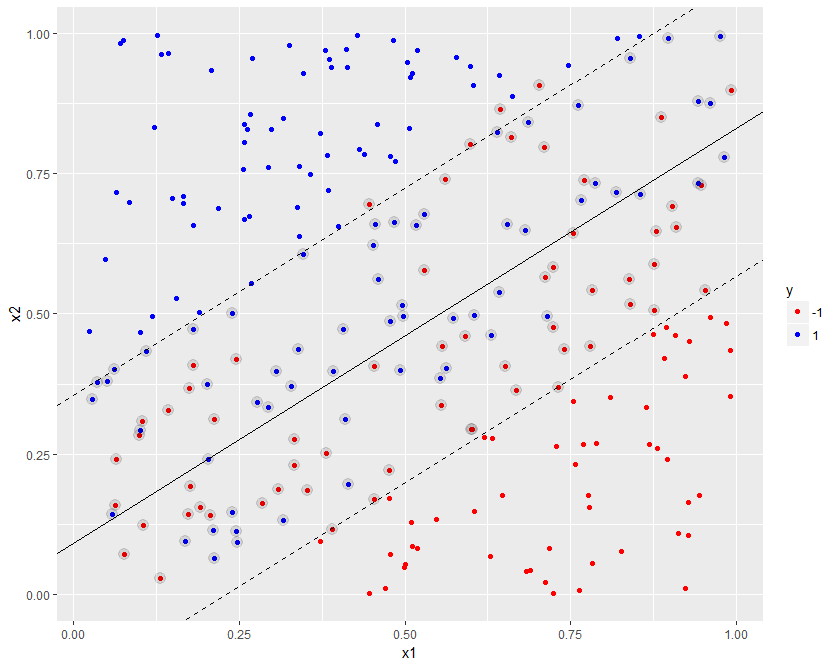
Linear SVM, default cost
library(e1071)
svm_model <- svm(y ~ .,
data = trainset,
type = "C-classification",
kernel = "linear",
scale = FALSE)
# Print model summary
svm_model
Call:
svm(formula = y ~ .,
data = trainset,
type = "C-classification",
kernel = "linear",
scale = FALSE)
Parameters:
SVM-Type: C-classification
SVM-Kernel: linear
cost: 1
gamma: 0.5
Number of Support Vectors: 55