Cartographic workflows with tigris and tidycensus
Analyzing US Census Data in R

Kyle Walker
Instructor
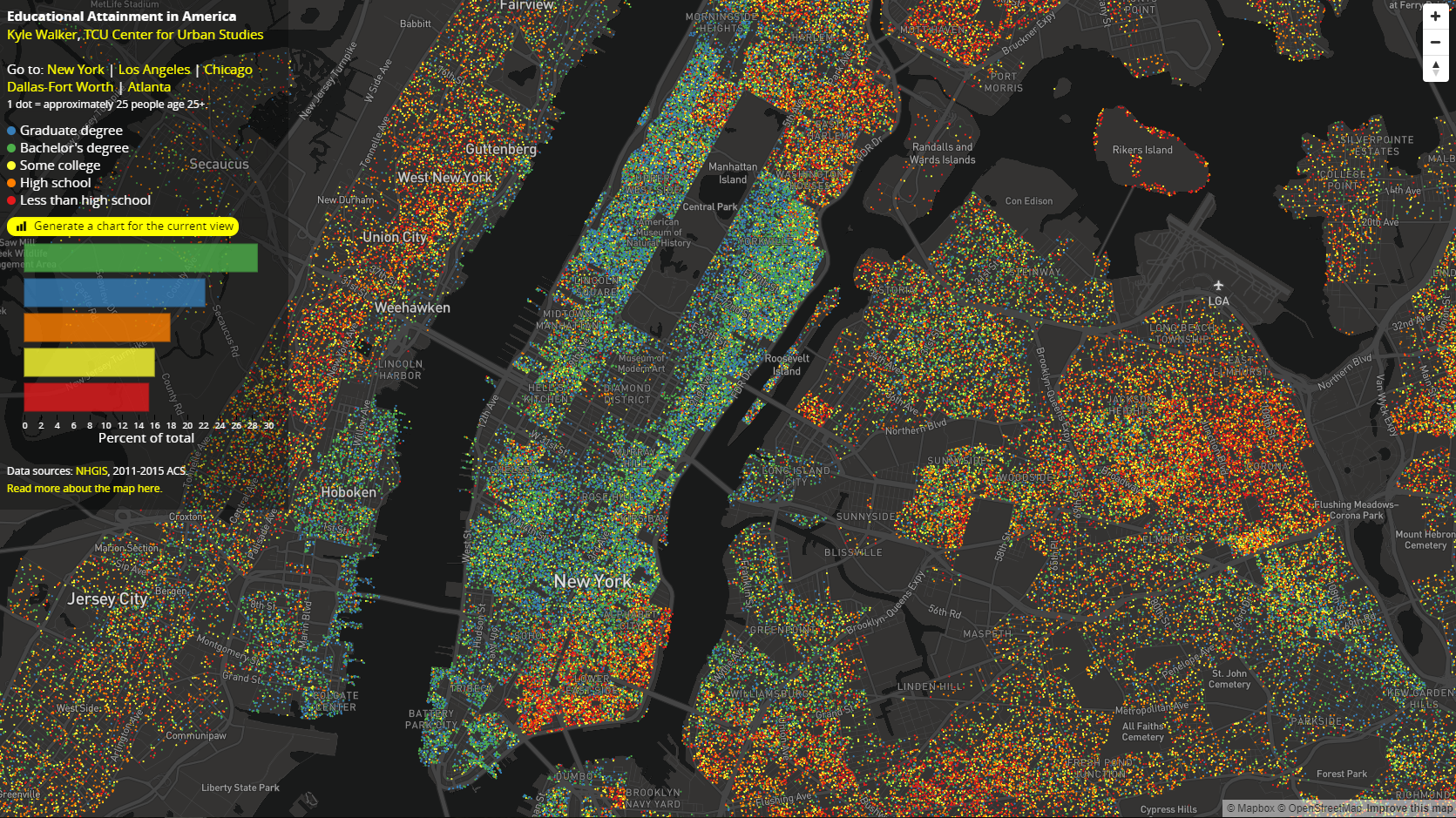
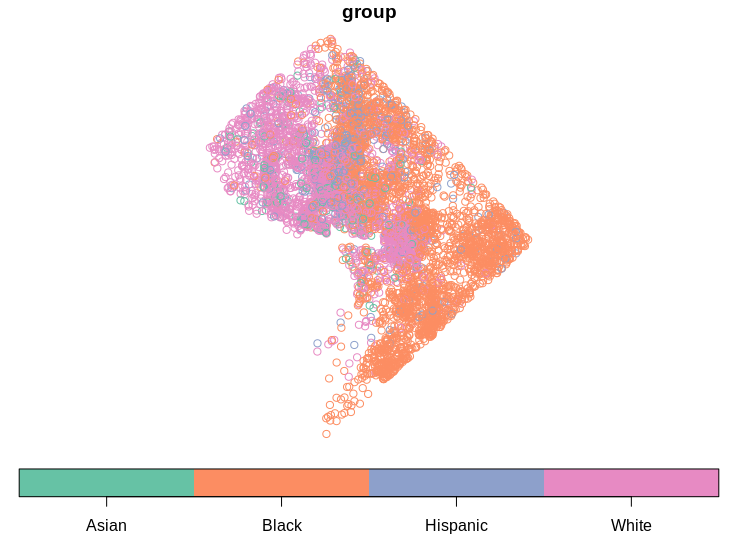
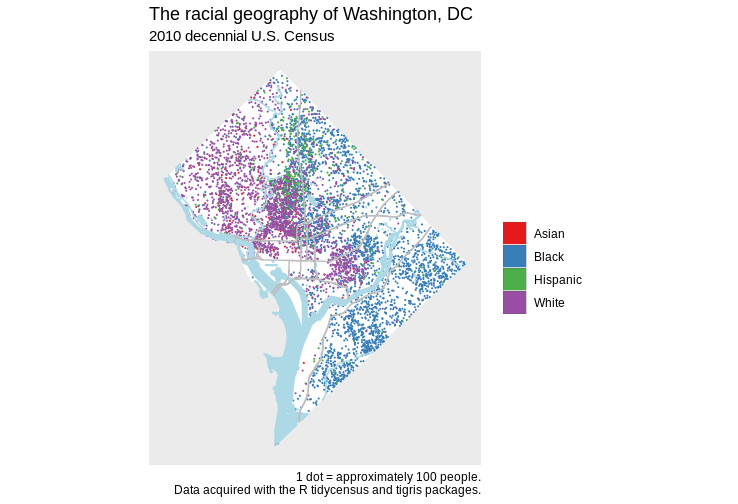
Basic dot-density mapping with sf
plot(dc_dots_shuffle, key.pos = 1)
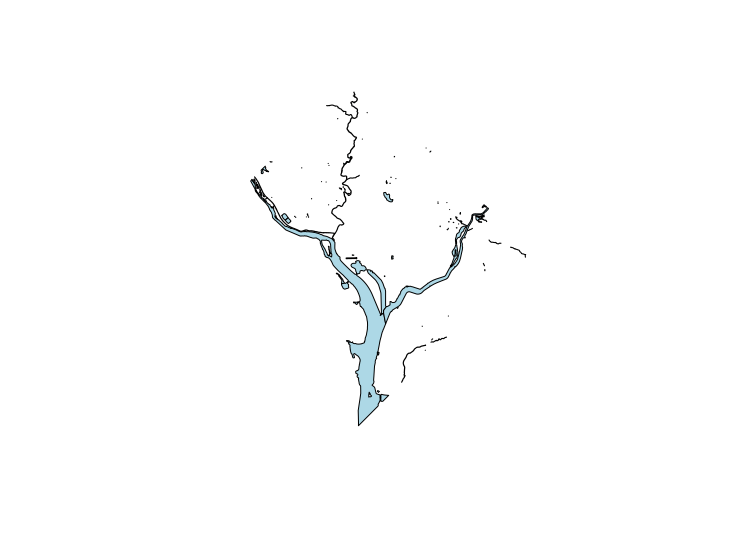
Ancillary data with tigris
plot(dc_water$geometry, col = "lightblue")
Analyzing US Census Data in R
Kyle Walker
Instructor
plot(dc_dots_shuffle, key.pos = 1)
plot(dc_water$geometry, col = "lightblue")

