Evaluating implicit ratings models
Building Recommendation Engines with PySpark

Jamen Long
Data Scientist at Nike
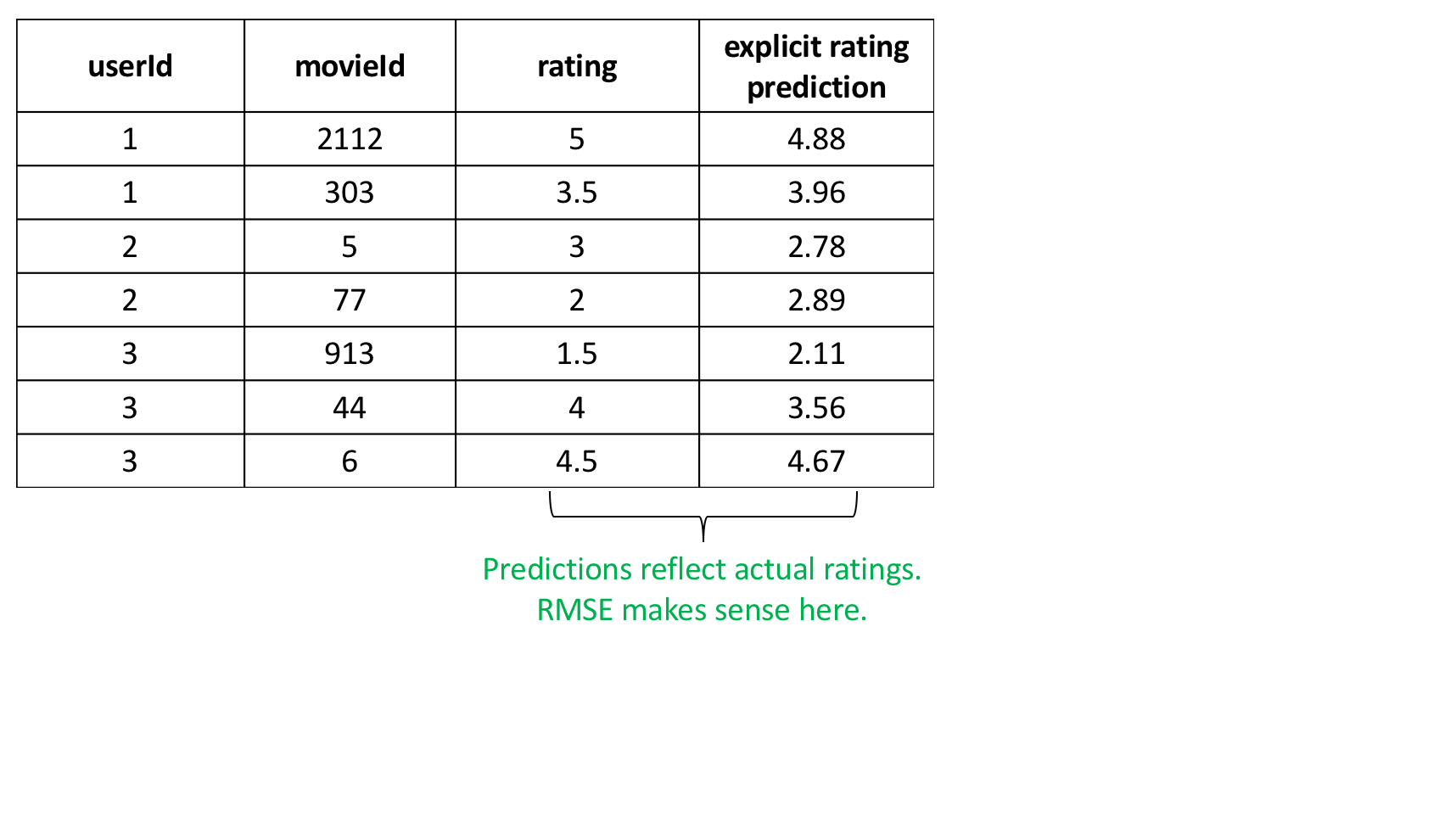
Why RMSE worked before
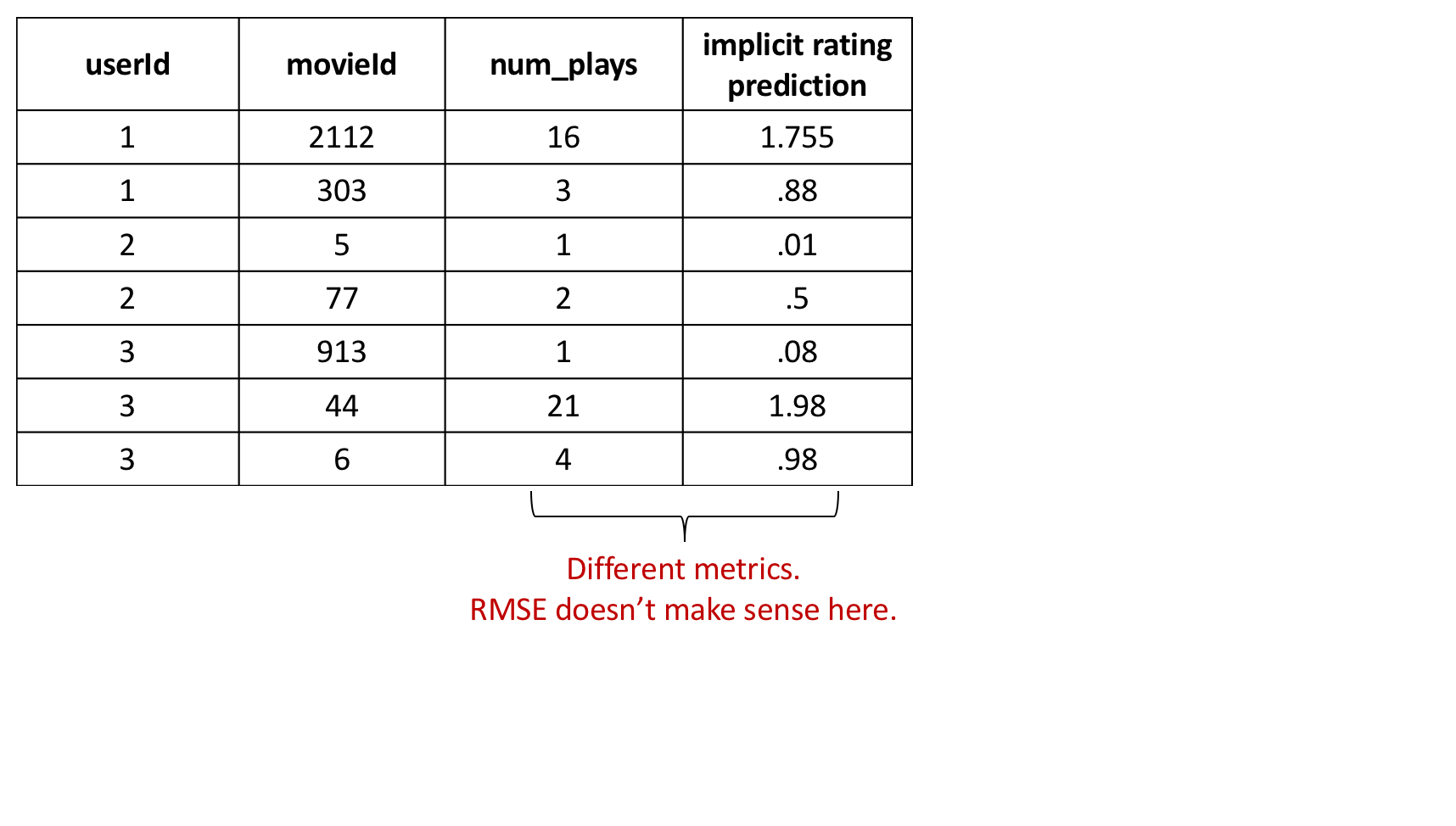
Why RMSE doesn't work now
(ROEM) Rank Ordering Error Metric
$$\text{ROEM} = \frac{\sum_{u,i} r^t_{u,i} \text{rank}_{u,i}}{\sum_{u,i} r^t_{u,i}}$$
ROEM bad predictions
bad_prediction.show()
+-------+------+-----+--------+--------+
|userId |songId|num_plays|badPreds|percRank|
+-------+------+-----+--------+--------+
| 111| 22| 3| 0.0001| 1.000|
| 111| 9| 0| 0.999| 0.000|
| 111| 321| 0| 0.08| 0.500|
| 222| 84| 0|0.000003| 1.000|
| 222| 821| 2| 0.88| 0.000|
| 222| 91| 2| 0.73| 0.500|
| 333| 2112| 0| 0.90| 0.000|
| 333| 42| 2| 0.80| 0.500|
| 333| 6| 0| 0.01| 1.000|
+-------+------+-----+--------+--------+
ROEM: PercRank * plays
bp = bad_predictions.withColumn("np*rank", col("num_plays")*col("percRank"))
bp.show()
+-------+------+---------+--------+--------+-------+
|userId |songId|num_plays|badPreds|percRank|np*rank|
+-------+------+---------+--------+--------+-------+
| 111| 22| 3| 0.0001| 1.000| 3.00|
| 111| 9| 0| 0.999| 0.000| 0.00|
| 111| 321| 0| 0.08| 0.500| 0.00|
| 222| 84| 0|0.000003| 1.000| 0.00|
| 222| 821| 2| 0.88| 0.000| 0.00|
| 222| 91| 2| 0.73| 0.500| 1.00|
| 333| 2112| 0| 0.90| 0.000| 0.00|
| 333| 42| 2| 0.80| 0.500| 1.00|
| 333| 6| 0| 0.01| 1.000| 0.00|
+-------+------+---------+--------+--------+-------+
ROEM: bad predictions
+-------+------+---------+--------+--------+-------+
|userId |songId|num_plays|badPreds|percRank|np*rank|
+-------+------+---------+--------+--------+-------+
| 111| 22| 3| 0.0001| 1.000| 3.00|
| 111| 9| 0| 0.999| 0.000| 0.00|
| 111| 321| 0| 0.08| 0.500| 0.00|
| 222| 84| 0|0.000003| 1.000| 0.00|
| 222| 821| 2| 0.88| 0.000| 0.00|
| 222| 91| 2| 0.73| 0.500| 1.00|
| 333| 2112| 0| 0.90| 0.000| 0.00|
| 333| 42| 2| 0.80| 0.500| 1.00|
| 333| 6| 0| 0.01| 1.000| 0.00|
+-------+------+---------+--------+--------+-------+
numerator = bp.groupBy().sum("np*rank").collect()[0][0]
denominator = bp.groupBy().sum("num_plays").collect()[0][0]
print ("ROEM: "), numerator * 1.0/ denominator
ROEM: 5.0 / 9 = 0.556
Good predictions
gp = good_predictions.withColumn("np*rank", col("num_plays")*col("percRank"))
gp.show()
+-------+------+---------+---------+--------+-------+
|userId |songId|num_plays|goodPreds|percRank|np*rank|
+-------+------+---------+---------+--------+-------+
| 111| 22| 3| 1.1| 0.000| 0.000|
| 111| 77| 0| 0.01| 0.500| 0.000|
| 111| 99| 0| 0.008| 1.000| 0.000|
| 222| 22| 0| 0.0003| 1.000| 0.000|
| 222| 77| 2| 1.5| 0.000| 0.000|
| 222| 99| 2| 1.4| 0.500| 1.000|
| 333| 22| 0| 0.90| 0.500| 0.000|
| 333| 77| 2| 1.6| 0.000| 0.000|
| 333| 99| 0| 0.01| 1.000| 0.000|
+-------+------+---------+---------+--------+-------+
ROEM: good predictions
+-------+------+---------+---------+--------+-------+
|userId |songId|num_plays|goodPreds|percRank|np*rank|
+-------+------+---------+---------+--------+-------+
| 111| 22| 3| 1.1| 0.000| 0.000|
| 111| 77| 0| 0.01| 0.500| 0.000|
| 111| 99| 0| 0.008| 1.000| 0.000|
| 222| 22| 0| 0.0003| 1.000| 0.000|
| 222| 77| 2| 1.5| 0.000| 0.000|
| 222| 99| 2| 1.4| 0.500| 1.000|
| 333| 22| 0| 0.90| 0.500| 0.000|
| 333| 77| 2| 1.6| 0.000| 0.000|
| 333| 99| 0| 0.01| 1.000| 0.000|
+-------+------+---------+---------+--------+-------+
numerator = gp.groupBy().sum("np*rank").collect()[0][0]
denominator = gp.groupBy().sum("num_plays").collect()[0][0]
print ("ROEM: "), numerator * 1.0/ denominator
ROEM: 1.0 / 9 = 0.1111
ROEM: link to function on GitHub
+-------+------+---------+---------+--------+-------+
|userId |songId|num_plays|goodPreds|percRank|np*rank|
+-------+------+---------+---------+--------+-------+
| 111| 22| 3| 1.1| 0.000| 0.000|
| 111| 77| 0| 0.01| 0.500| 0.000|
| 111| 99| 0| 0.008| 1.000| 0.000|
| 222| 22| 0| 0.0003| 1.000| 0.000|
| 222| 77| 2| 1.5| 0.000| 0.000|
| 222| 99| 2| 1.4| 0.500| 1.000|
| 333| 22| 0| 0.90| 0.500| 0.000|
| 333| 77| 2| 1.6| 0.000| 0.000|
| 333| 99| 0| 0.01| 1.000| 0.000|
+-------+------+---------+---------+--------+-------+
numerator = gp.groupBy().sum("np*rank").collect()[0][0]
denominator = gp.groupBy().sum("num_plays").collect()[0][0]
print ("ROEM: "), numerator * 1.0/ denominator
ROEM: 1.0 / 9 = 0.1111
Building several ROEM models
(train, test) = implicit_ratings.randomSplit([.8, .2])
# Empty list to be filled with models
model_list = []
# Complete each of the hyperparameter value lists
ranks = [10, 20, 30, 40]
maxIters = [10, 20, 30, 40]
regParams = [.05, .1, .15]
alphas = [20, 40, 60, 80]
# For loop will automatically create and store ALS models
for r in ranks:
for mi in maxIters:
for rp in regParams:
for a in alphas:
model_list.append(ALS(userCol= "userId", itemCol= "songId",
ratingCol= "num_plays", rank = r, maxIter = mi, regParam = rp,
alpha = a, coldStartStrategy="drop",nonnegative = True,
implicitPrefs = True))
Error output
for model in model_list:
# Fits each model to the training data
trained_model = model.fit(train)
# Generates test predictions
predictions = trained_model.transform(test)
# Evaluates each model's performance
ROEM(predictions)
Let's practice!
Building Recommendation Engines with PySpark

