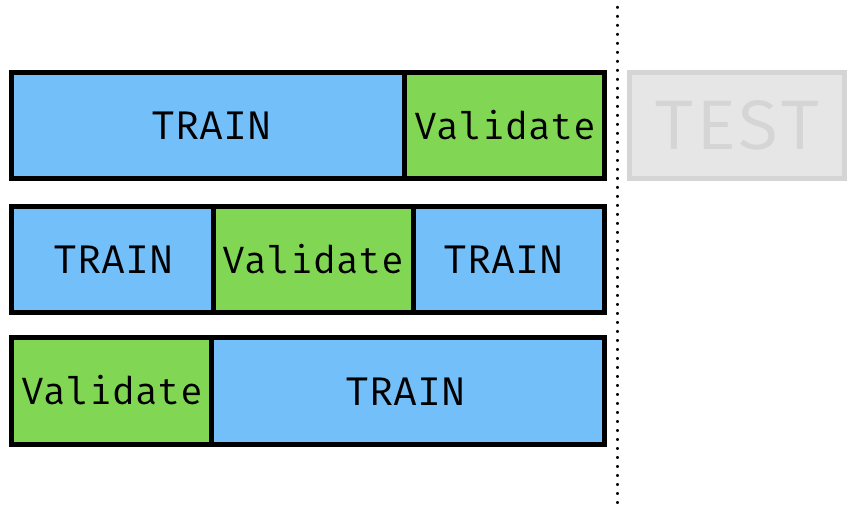
Training, test and validation splits
Machine Learning in the Tidyverse

Dmitriy (Dima) Gorenshteyn
Lead Data Scientist, Memorial Sloan Kettering Cancer Center
Train-Test Split
Train-Test Split
Train-Test Split
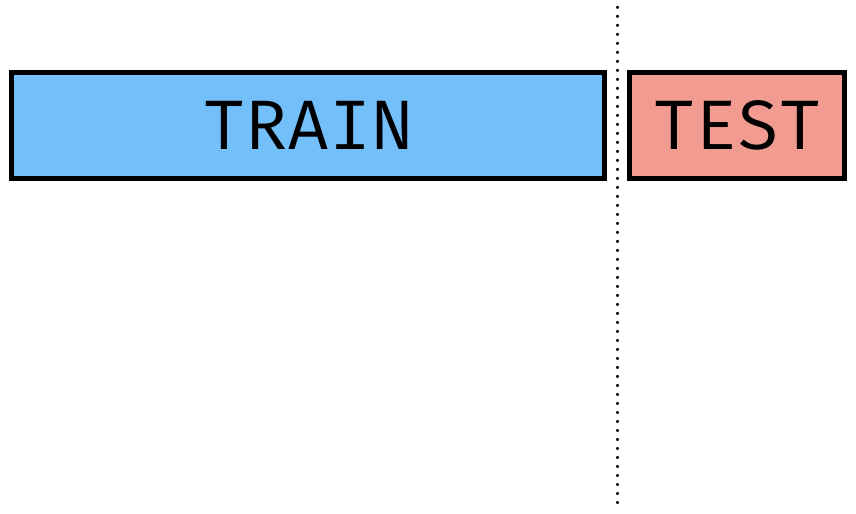
Train-Validate Split
Train-Validate Split
Cross Validation