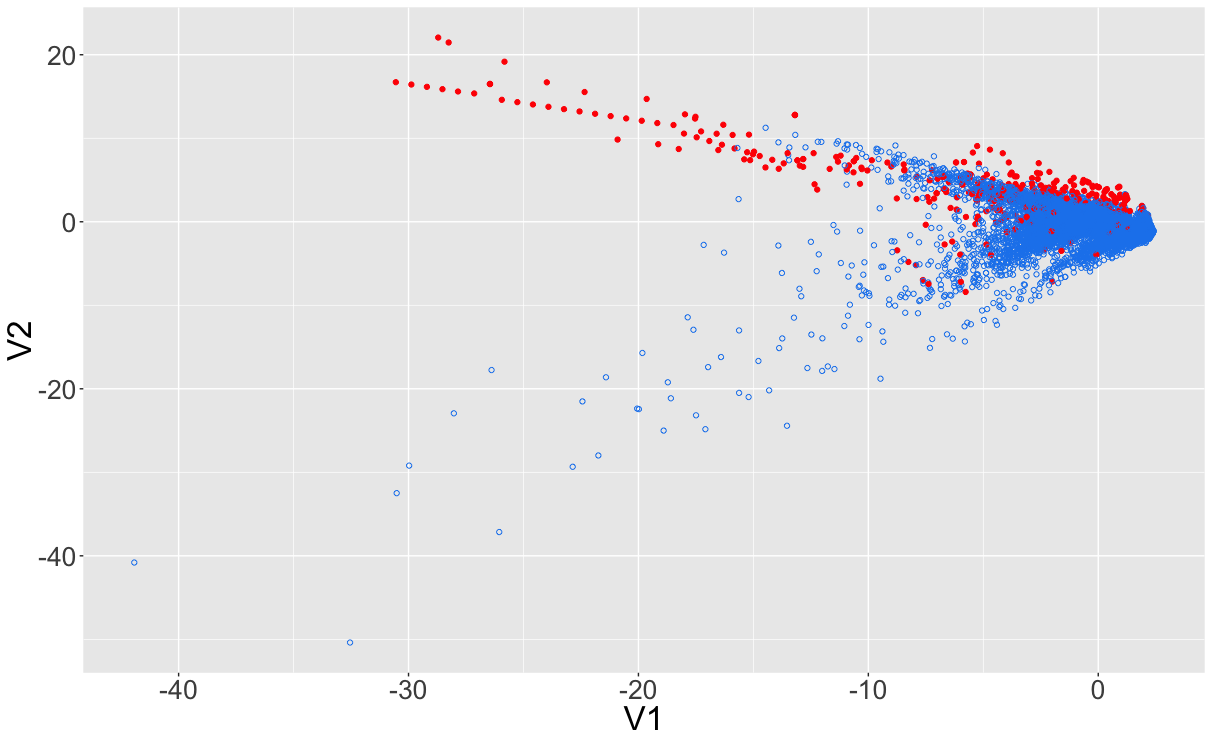
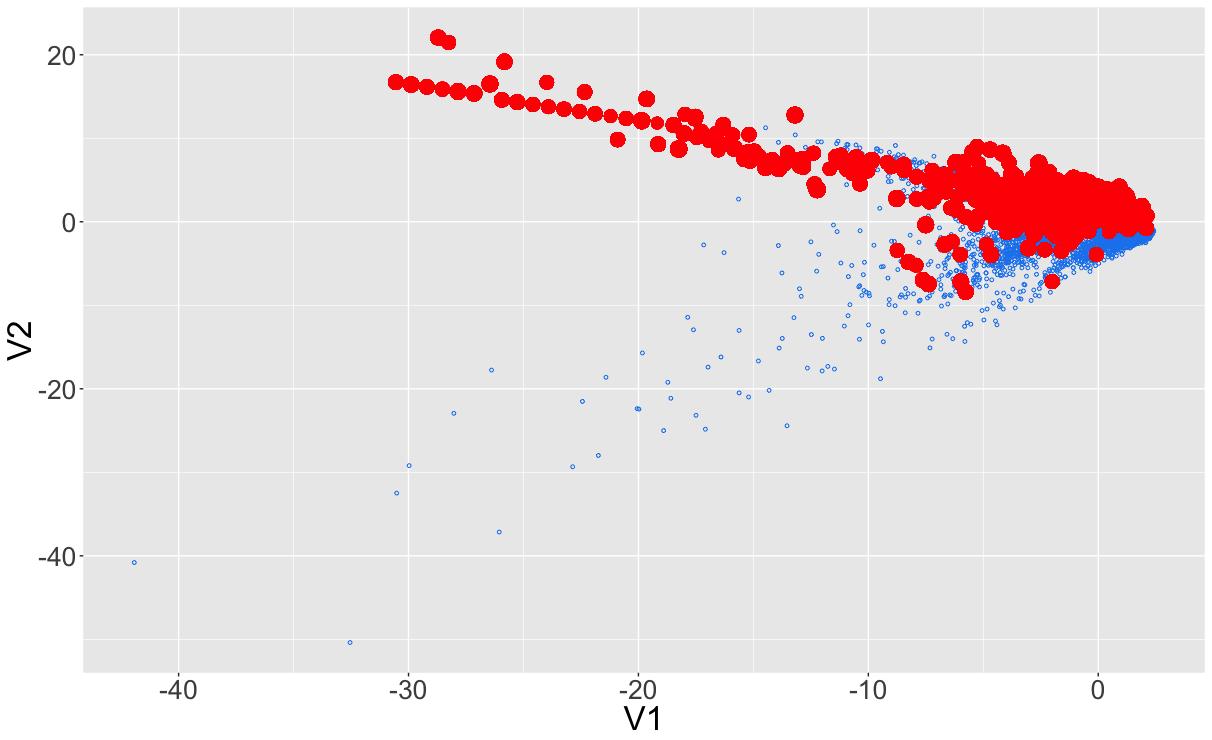
Dealing with imbalanced datasets
Fraud Detection in R

Bart Baesens
Professor Data Science at KU Leuven
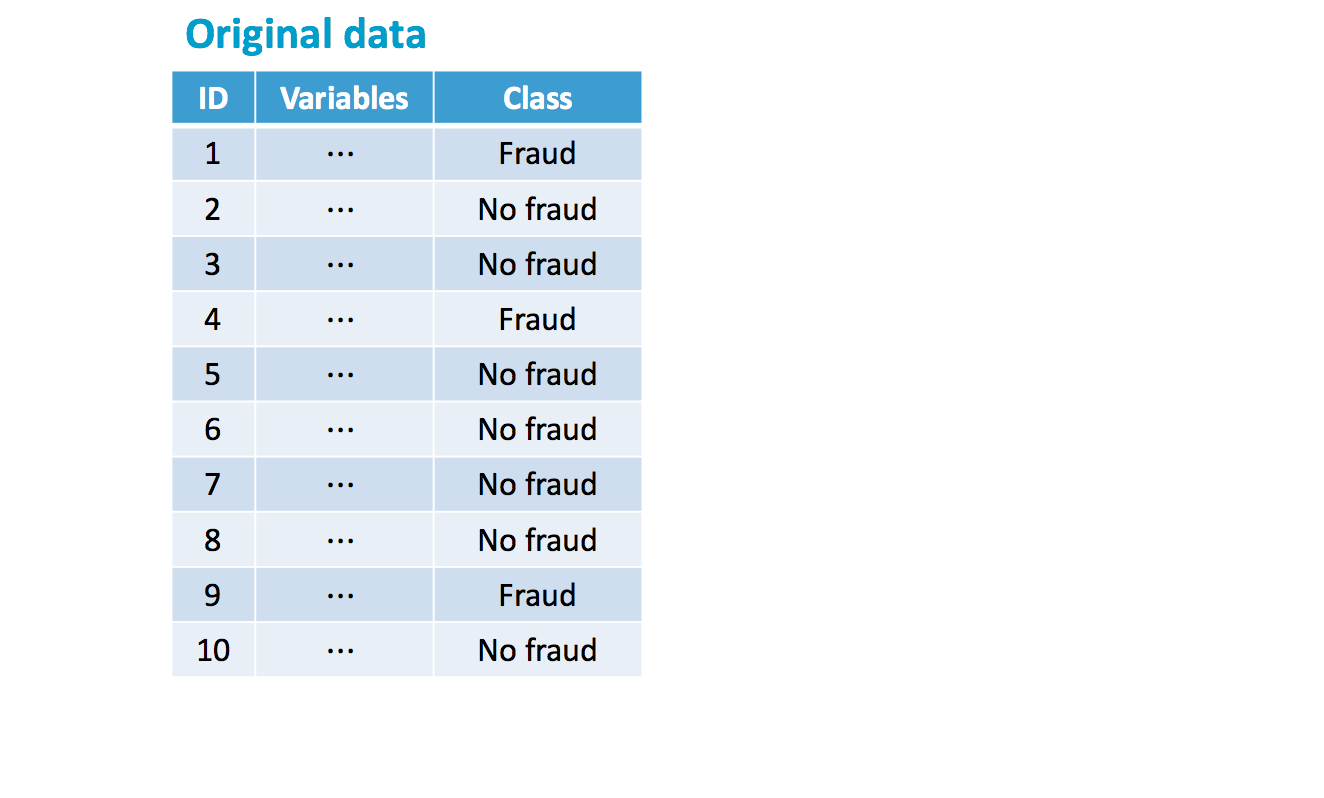
Imbalanced data sets

Imbalanced data sets

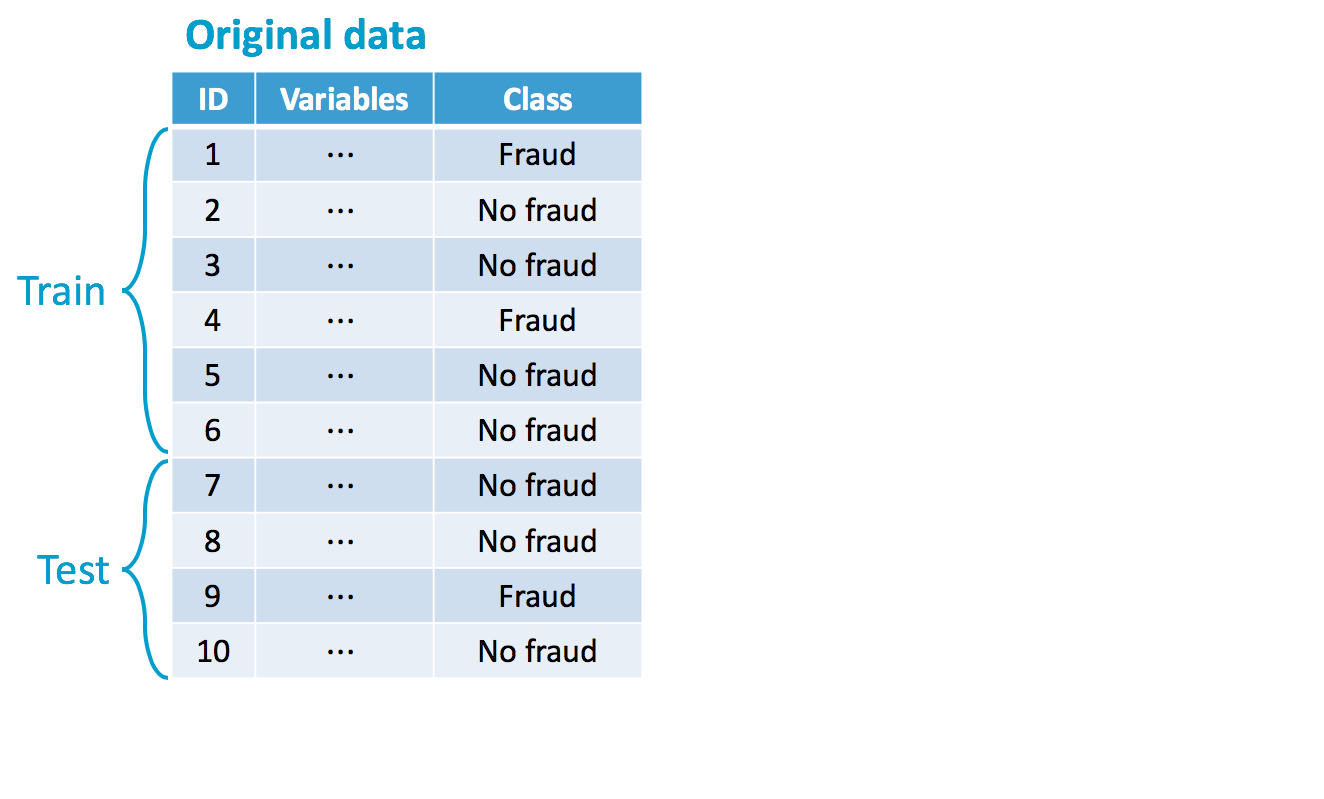
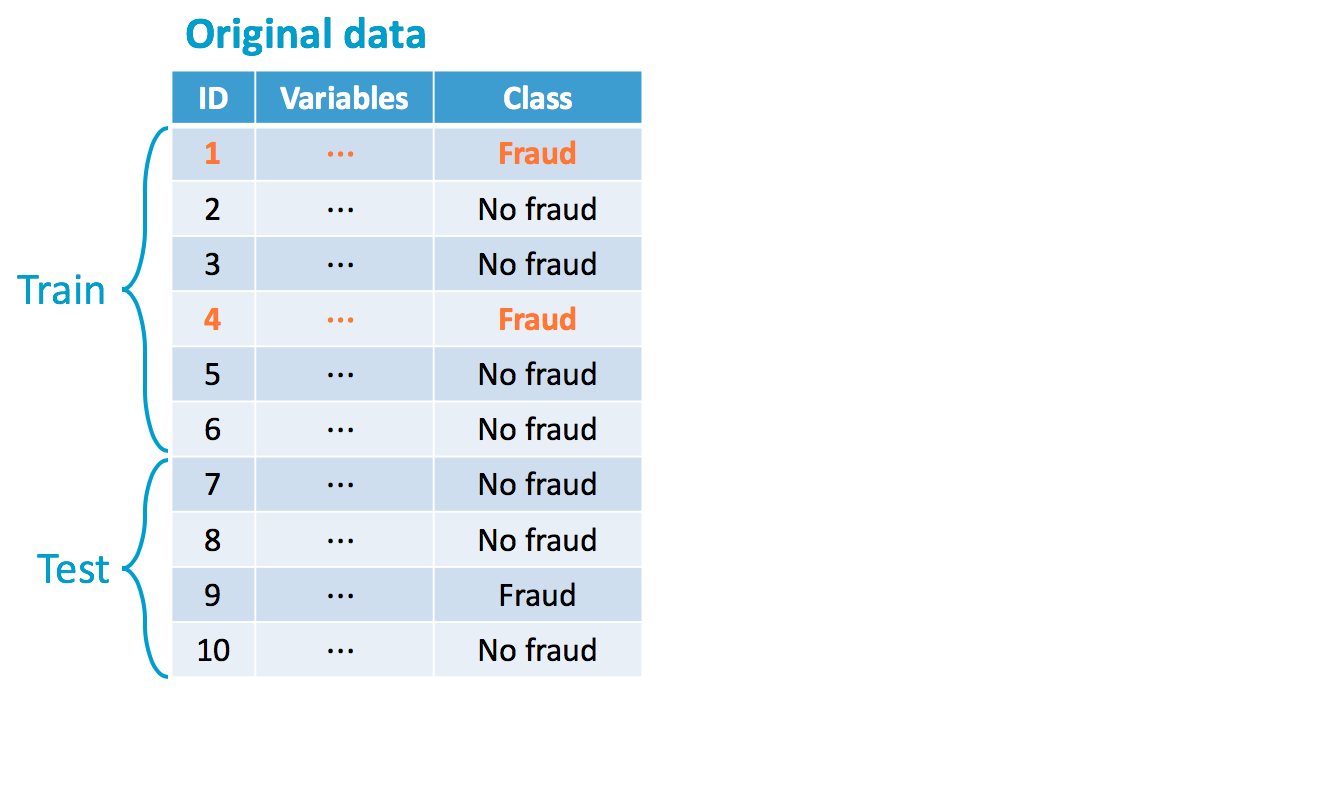
Original imbalance
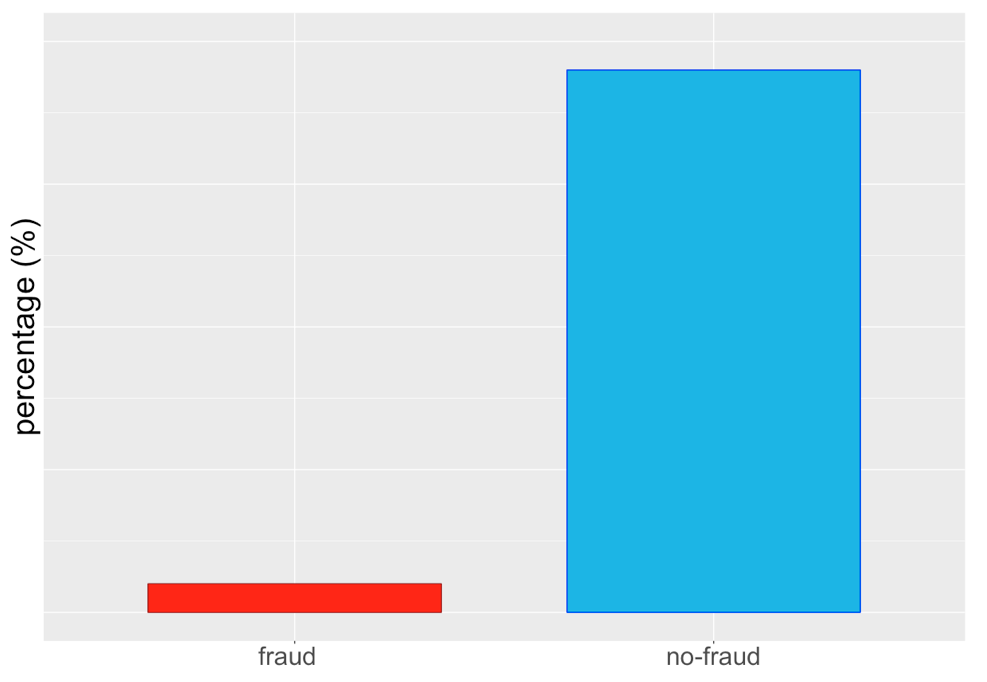
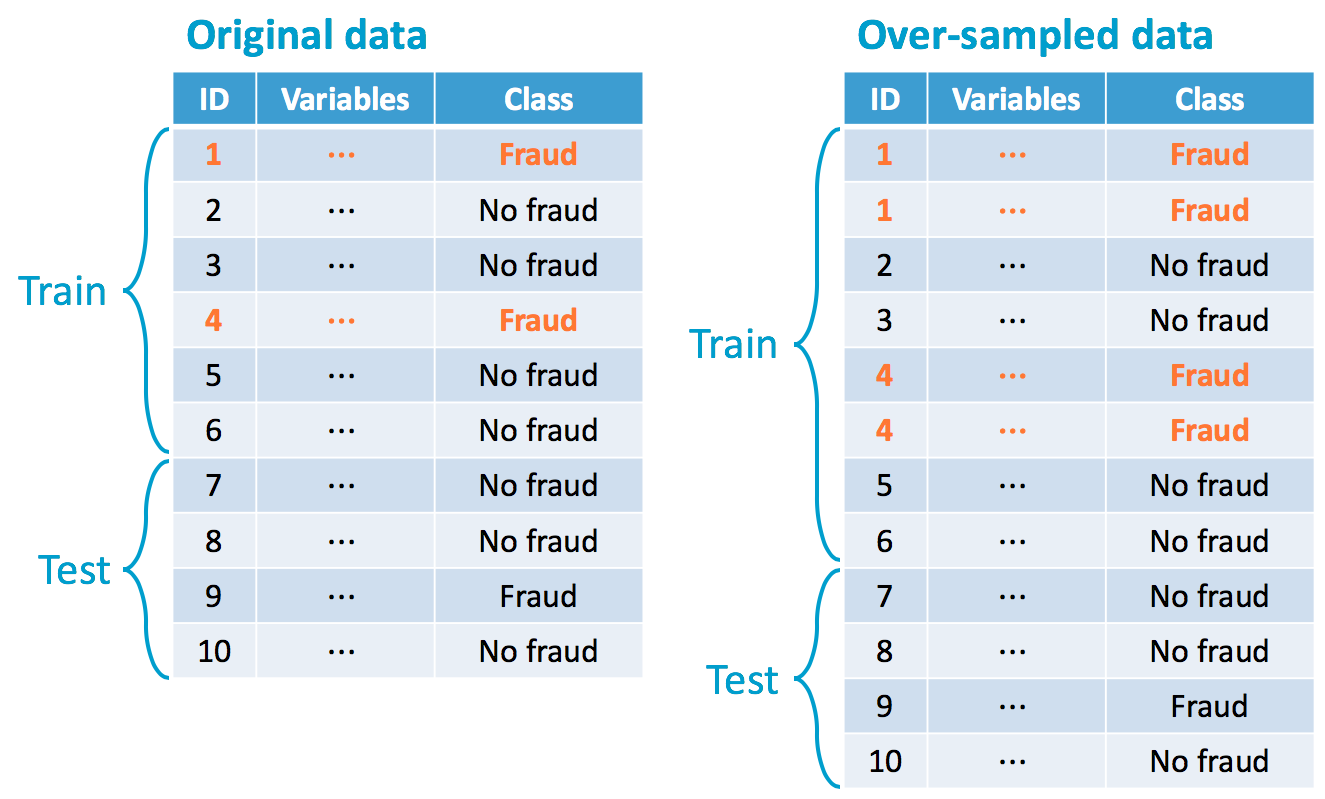
Over-sampling minority class...
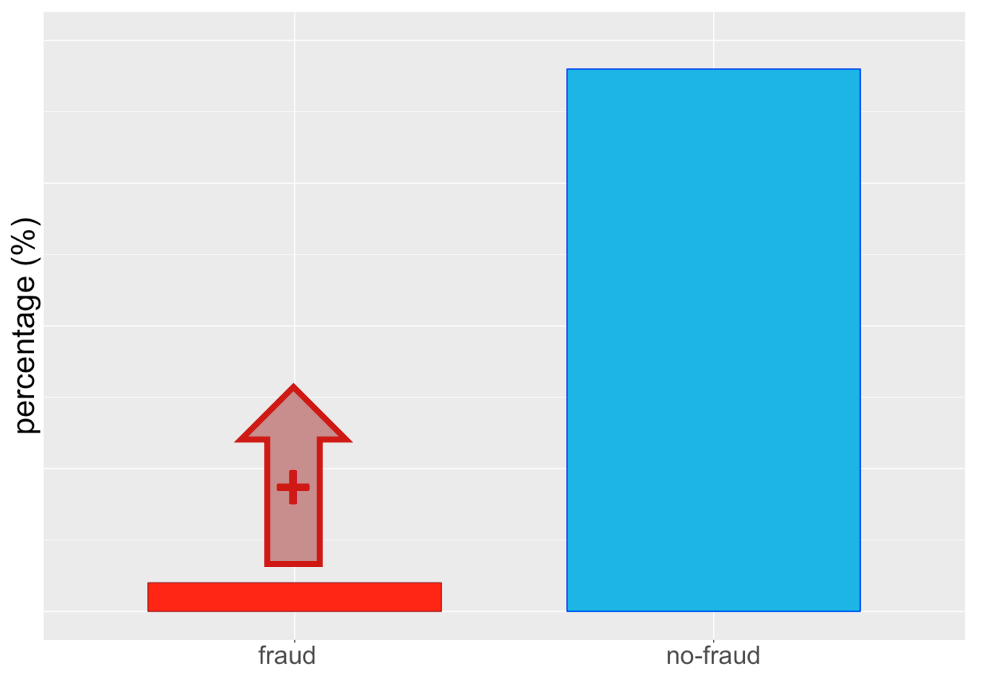
... or under-sampling majority class ...
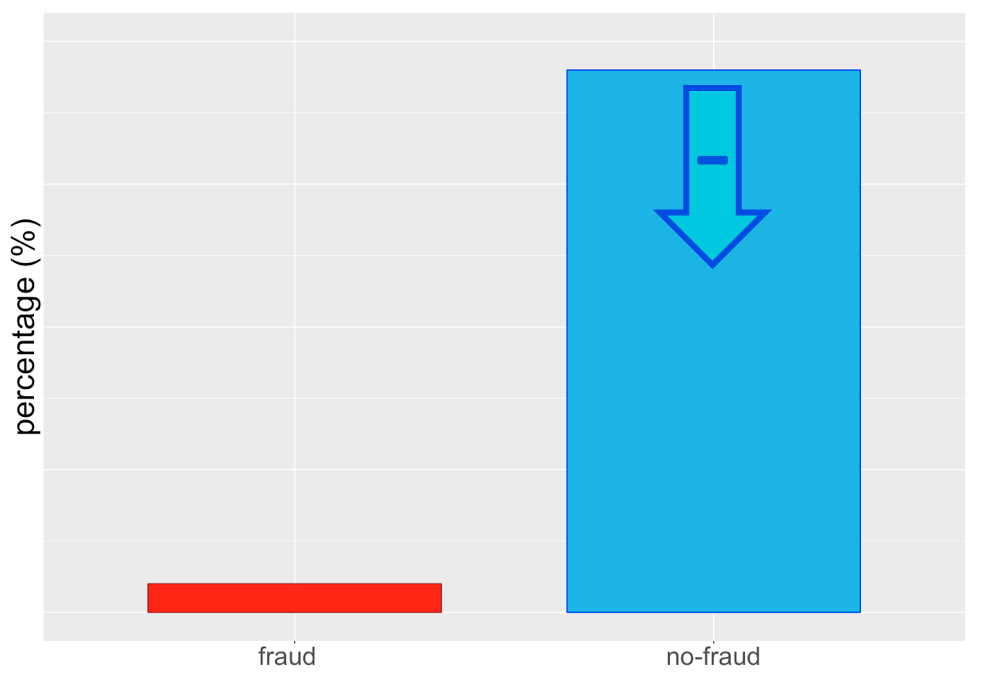
... or both!
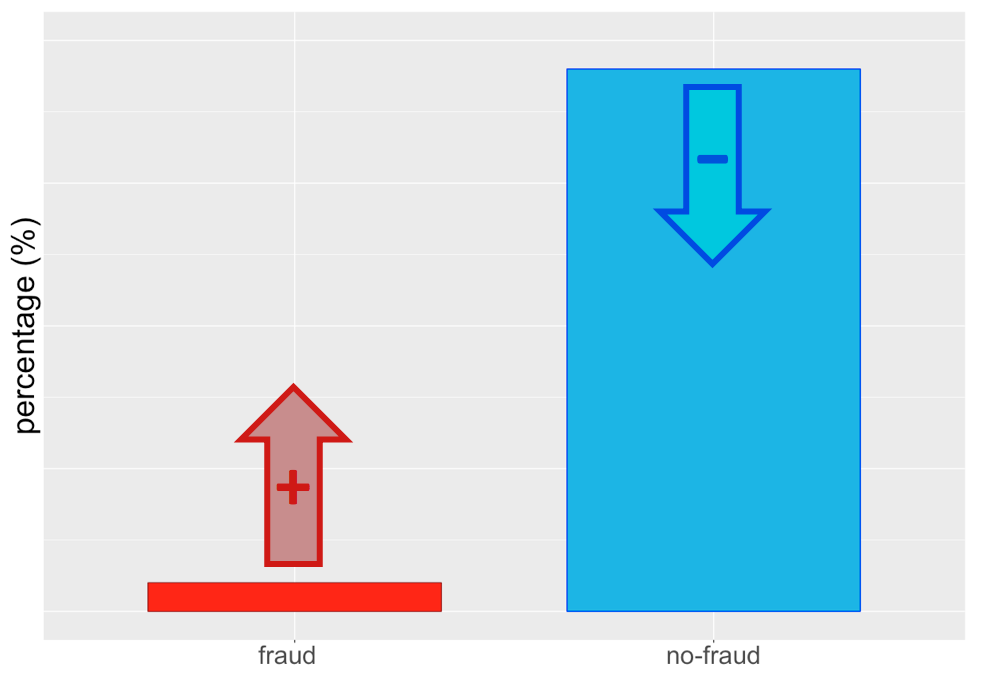
Result after sampling...
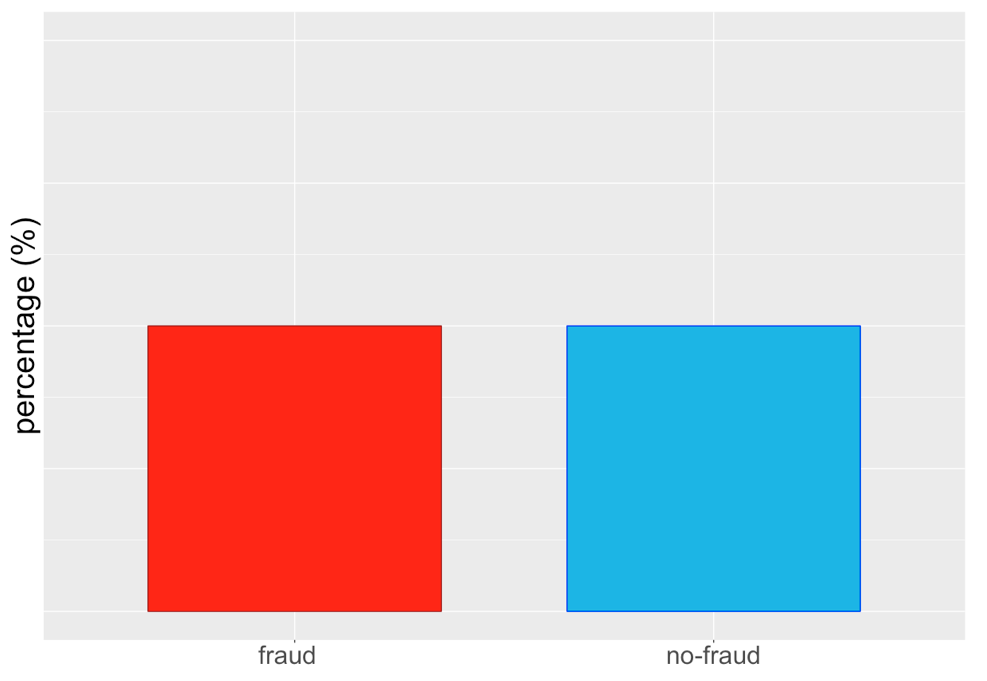
... or like this
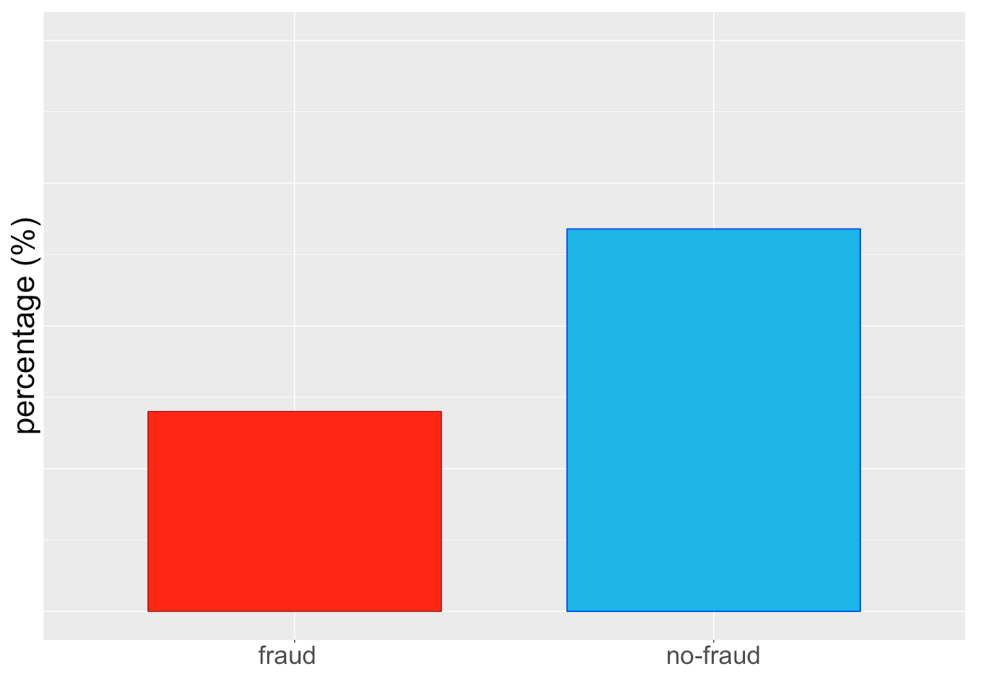
Random over-sampling (ROS)