From dataset to detection model
Fraud Detection in R

Sebastiaan Höppner
PhD researcher in Data Science at KU Leuven
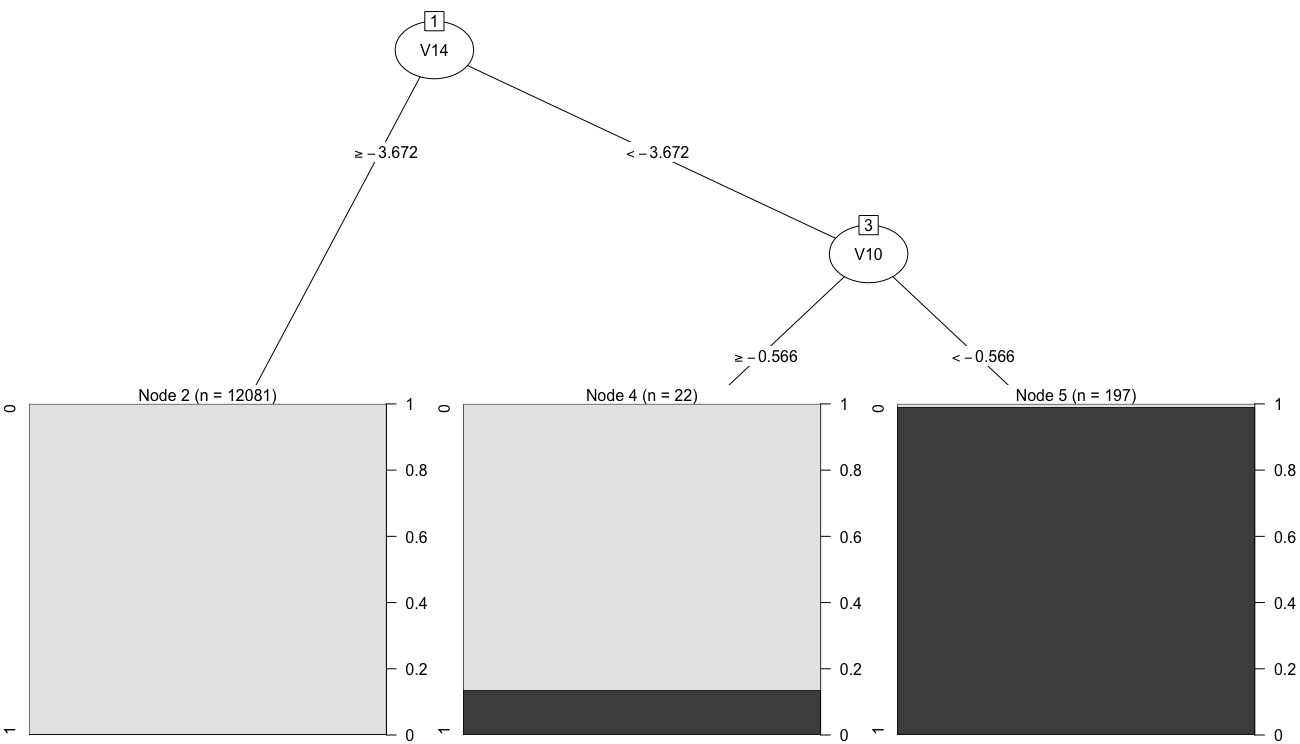
library(partykit)
plot(as.party(model1))
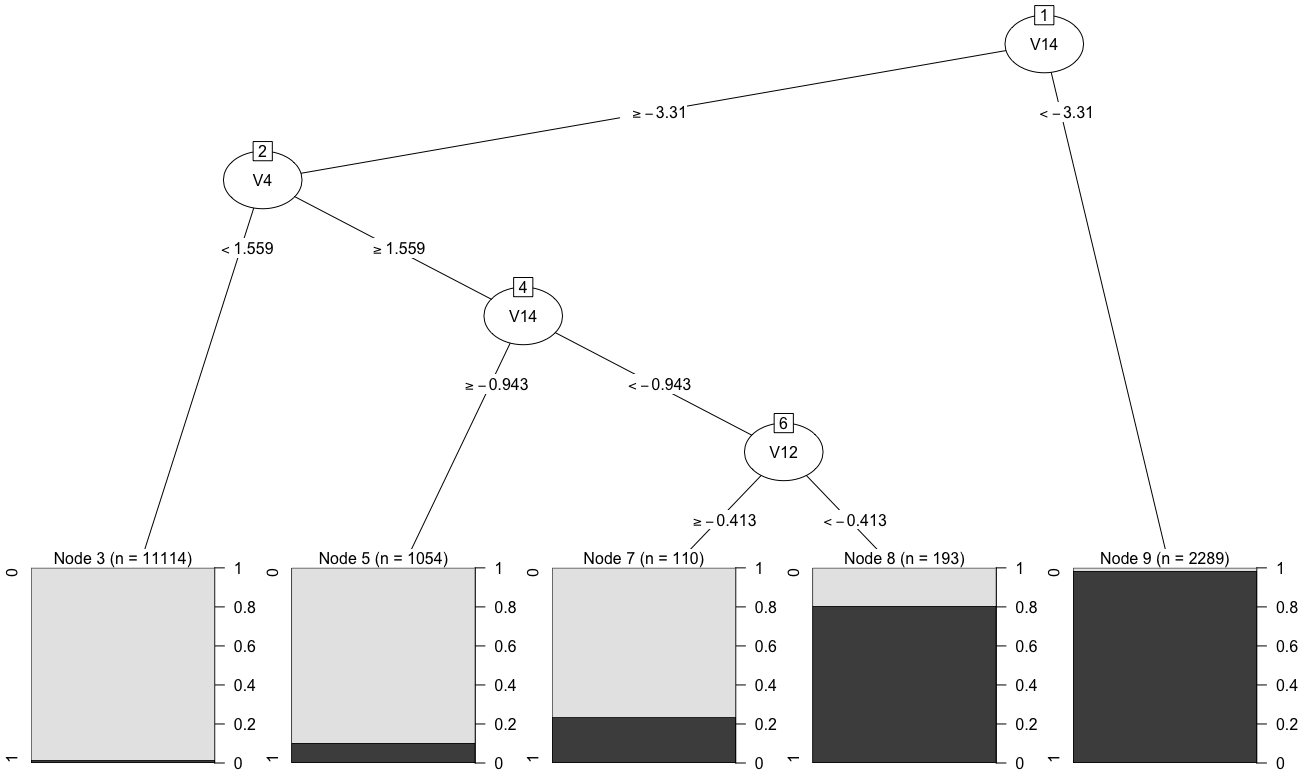
library(rpart)
model2 = rpart(Class ~ ., data = train_oversampled)
Cost matrix
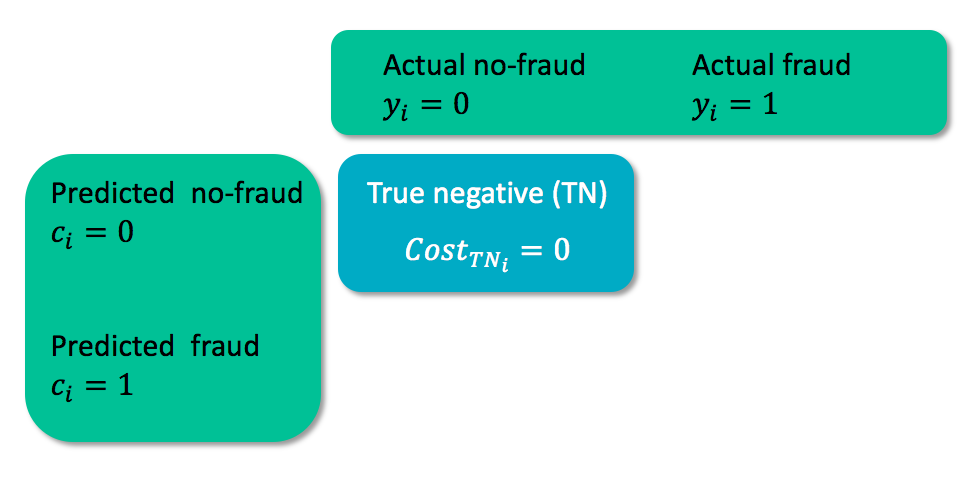
- $y_i$ = true class of case $i$
- $c_i$ = predicted class for case $i$
Cost matrix
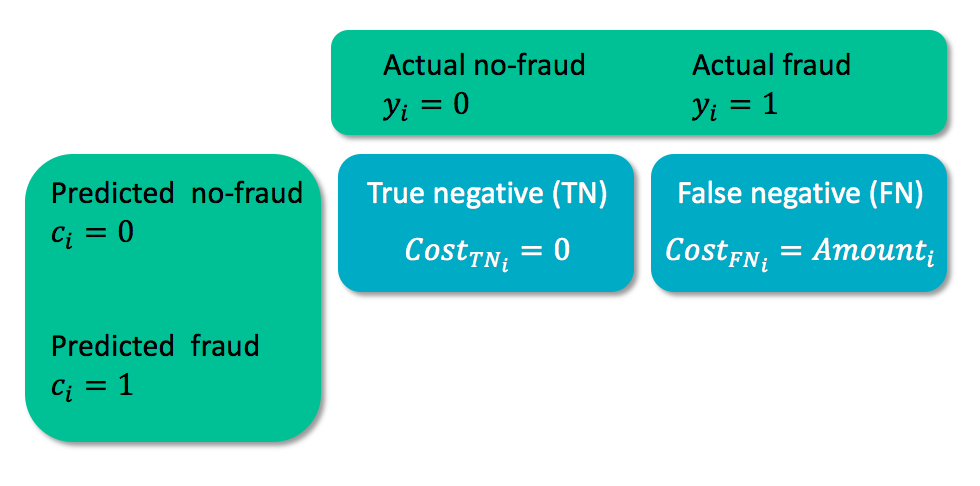
- $y_i$ = true class of case $i$
- $c_i$ = predicted class for case $i$
Cost matrix
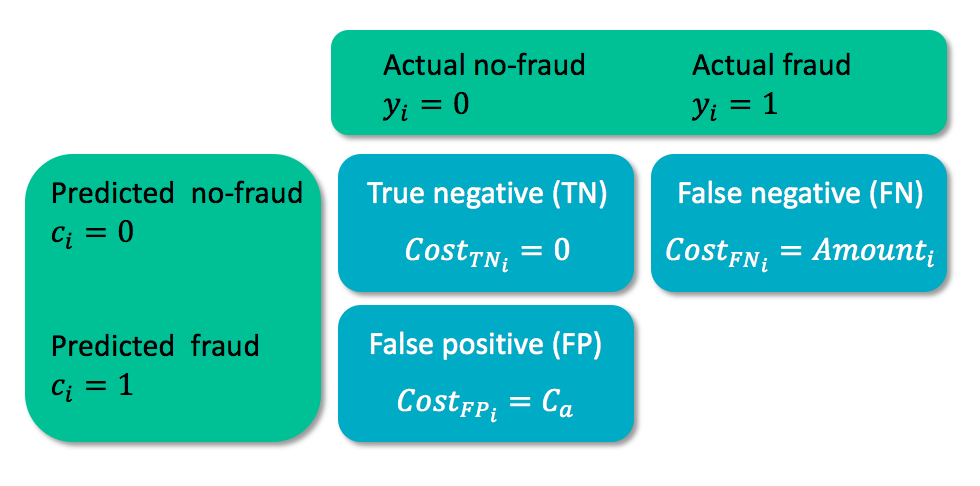
- $C_a$ = cost for analyzing the case
Cost matrix
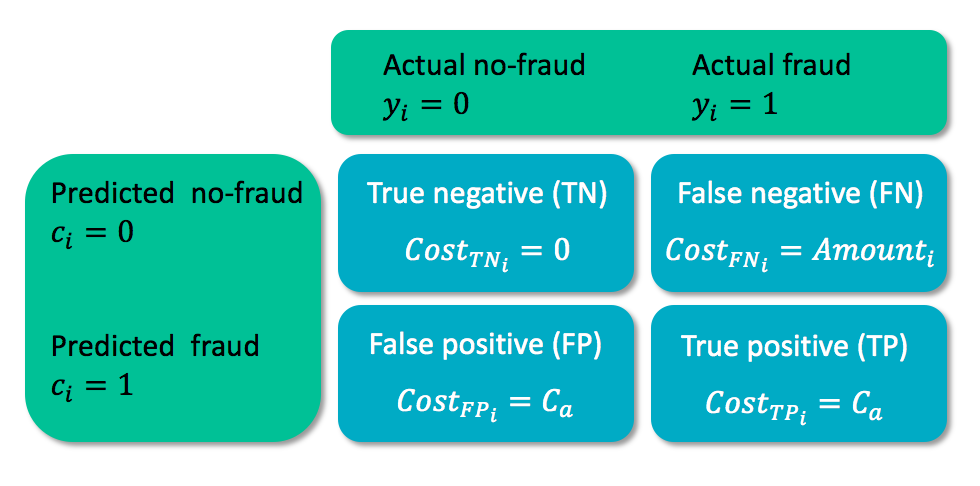
- $C_a$ = cost for analyzing the case

