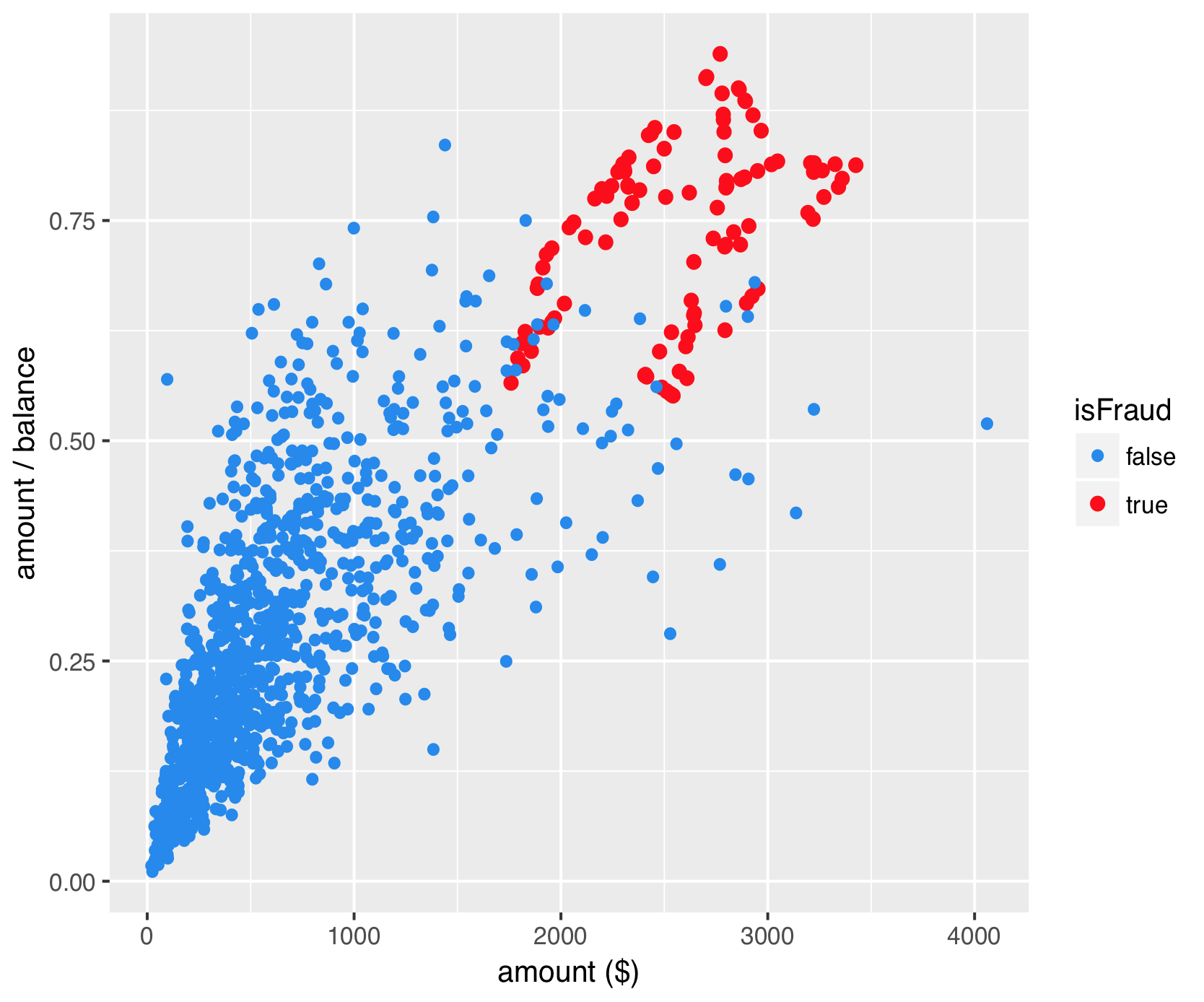
Synthetic Over-sampling
Fraud Detection in R

Sebastiaan Höppner
PhD researcher in Data Science at KU Leuven
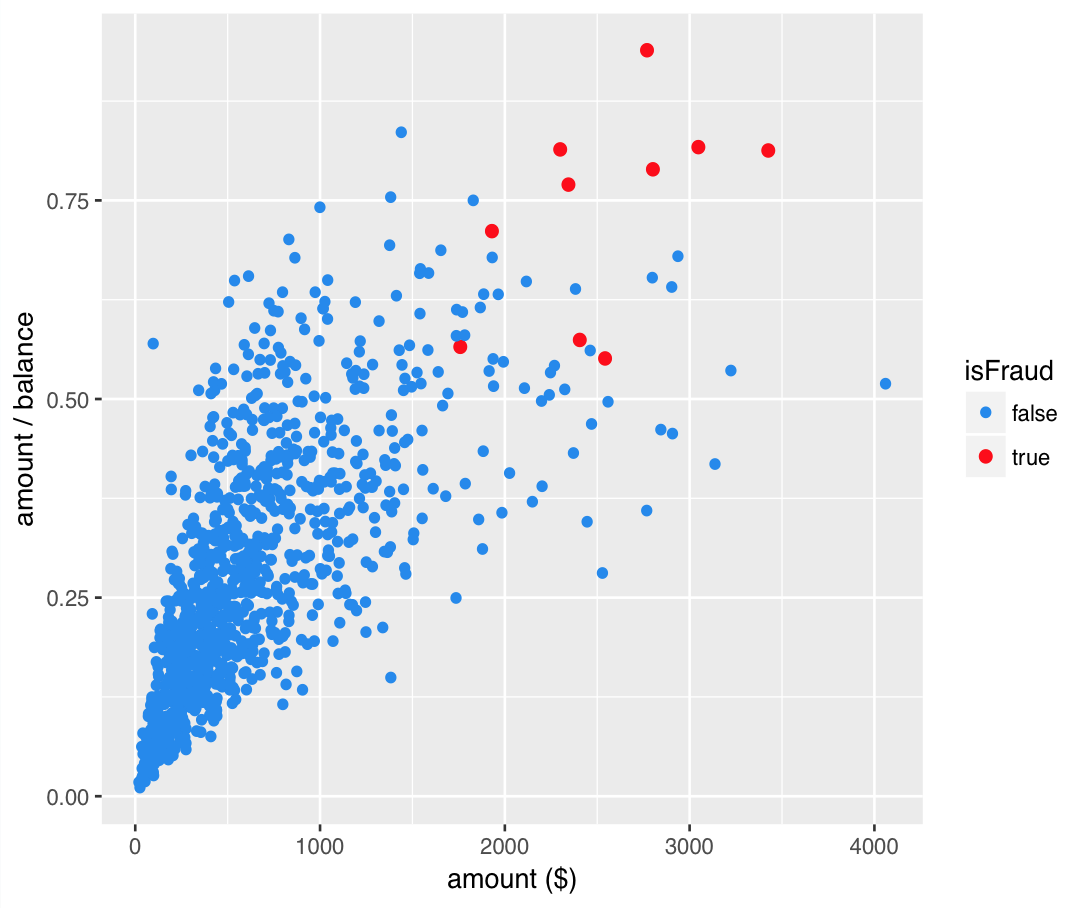
SMOTE
SMOTE - step 1
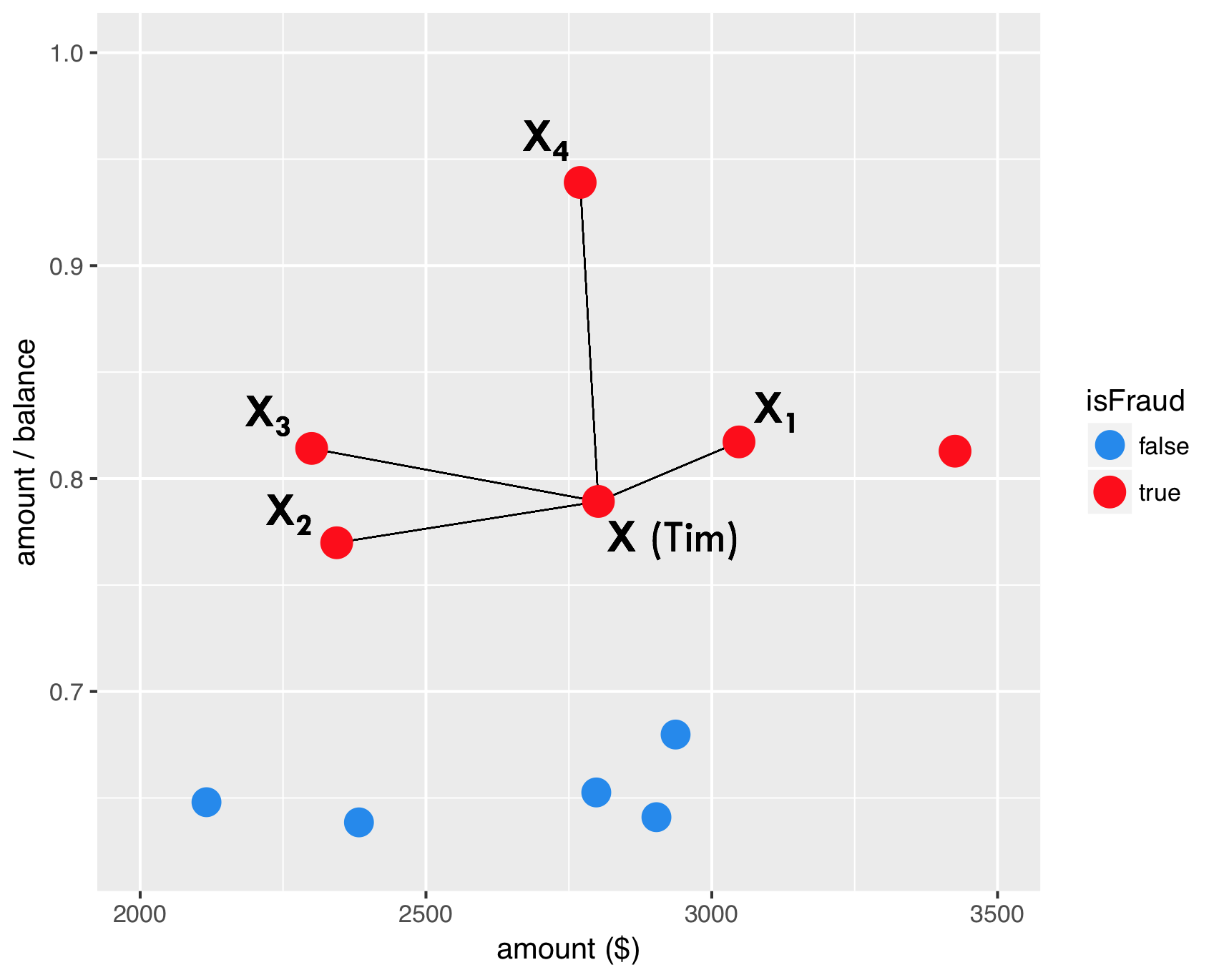
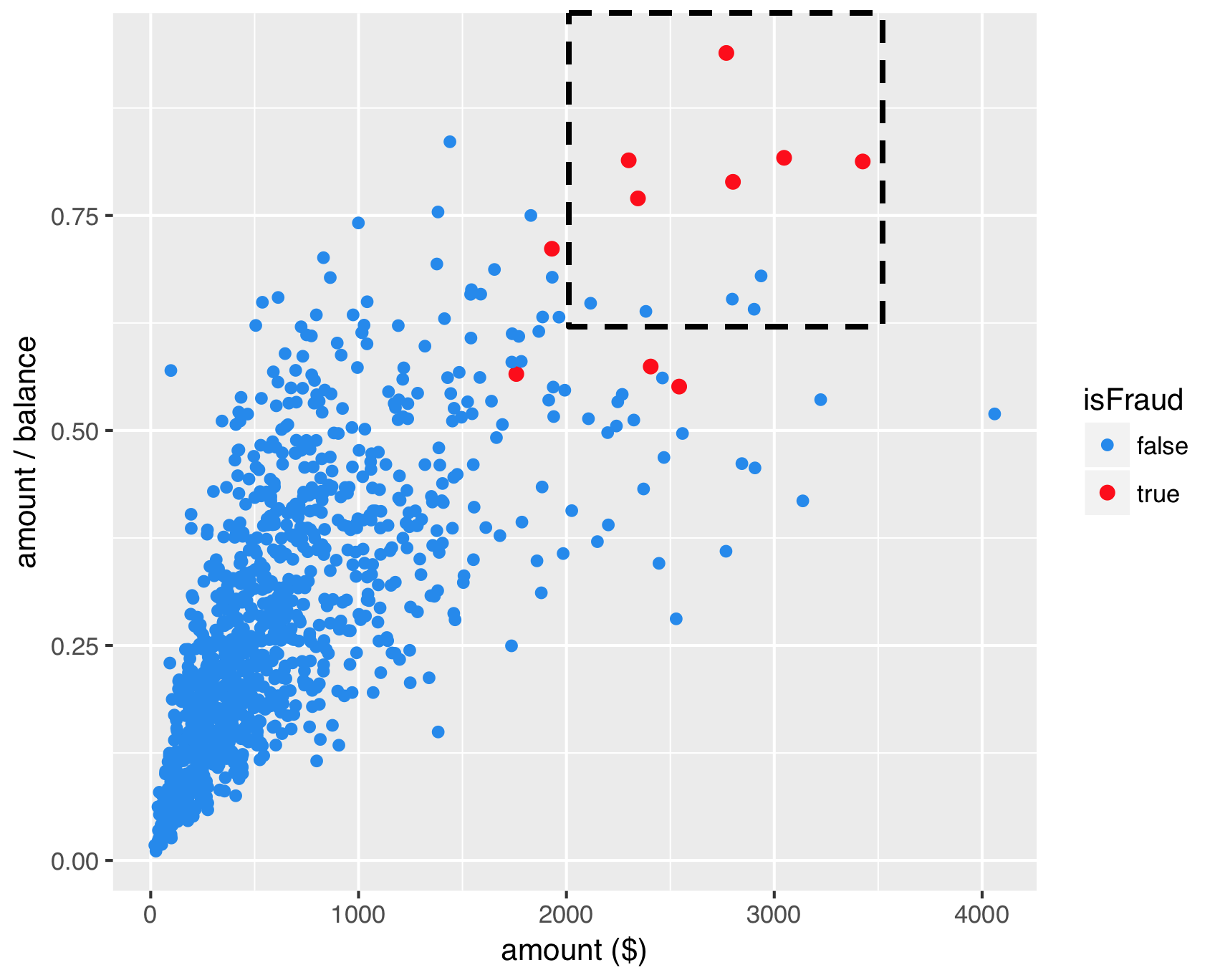
SMOTE - step 2
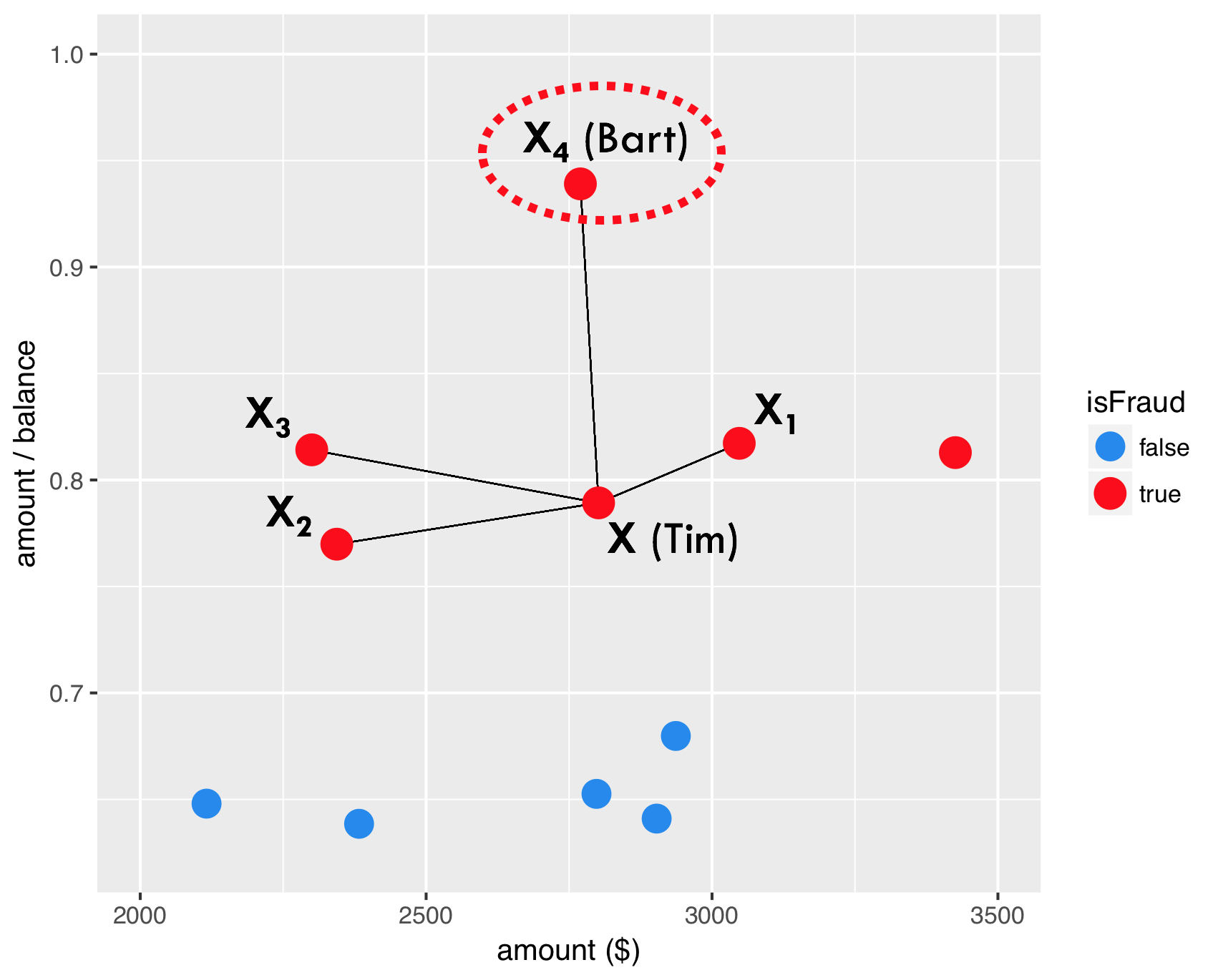
SMOTE - step 3
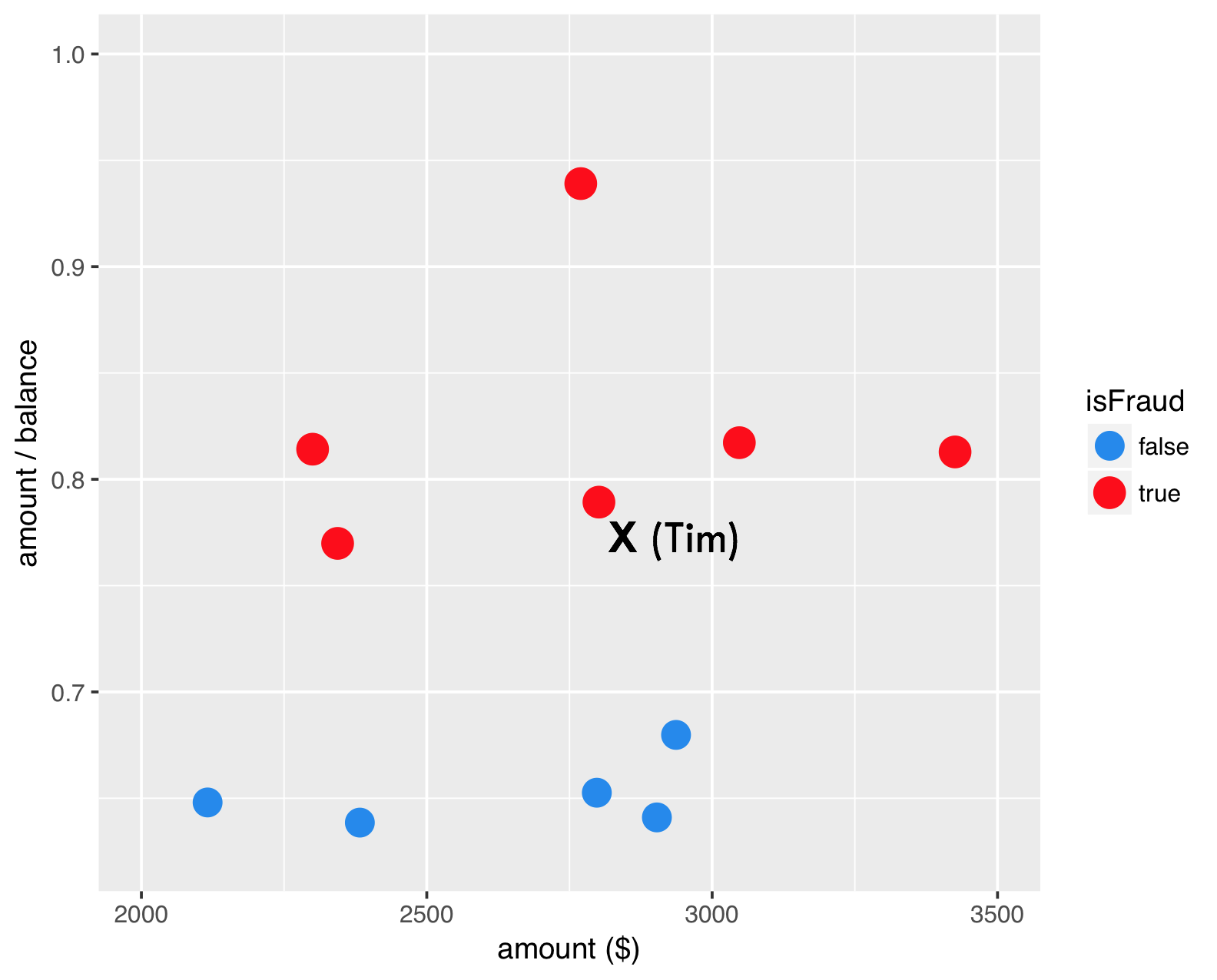
Step 3 : create synthetic sample

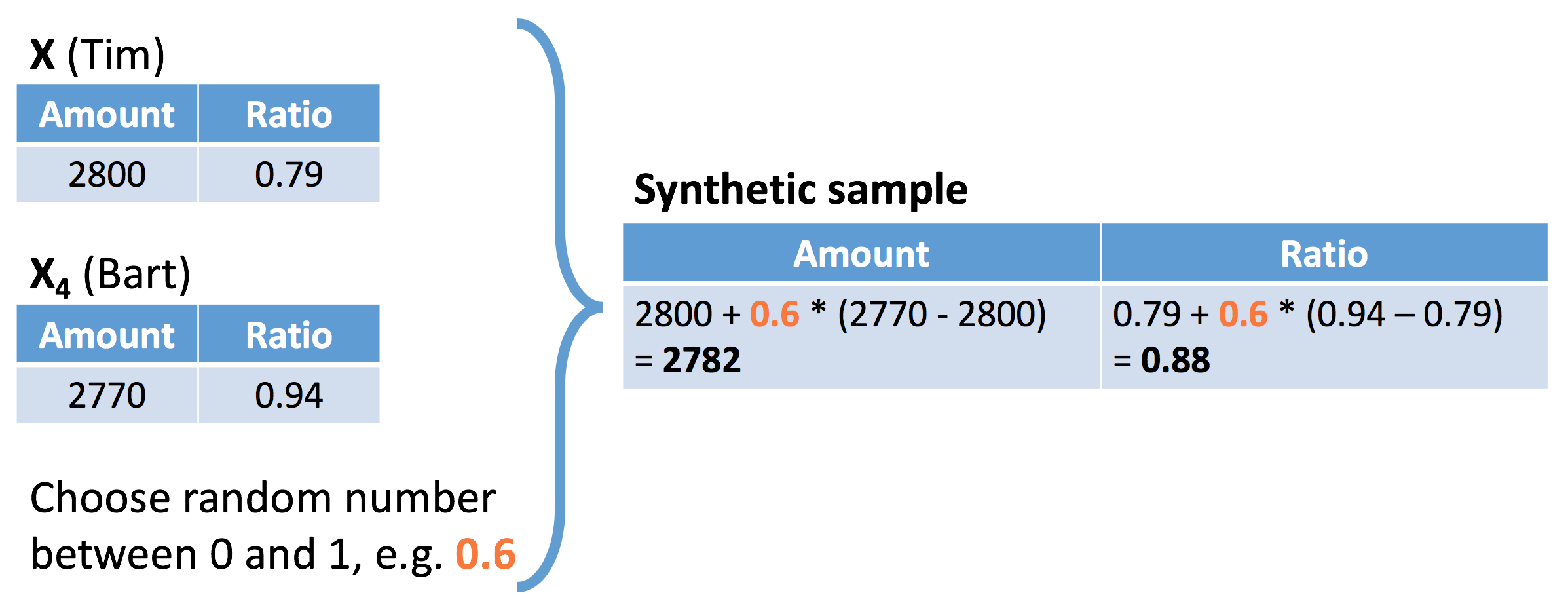
SMOTE - step 3
Step 3 : create synthetic sample

SMOTE - step 3
Step 3 : create synthetic sample
SMOTE - step 3
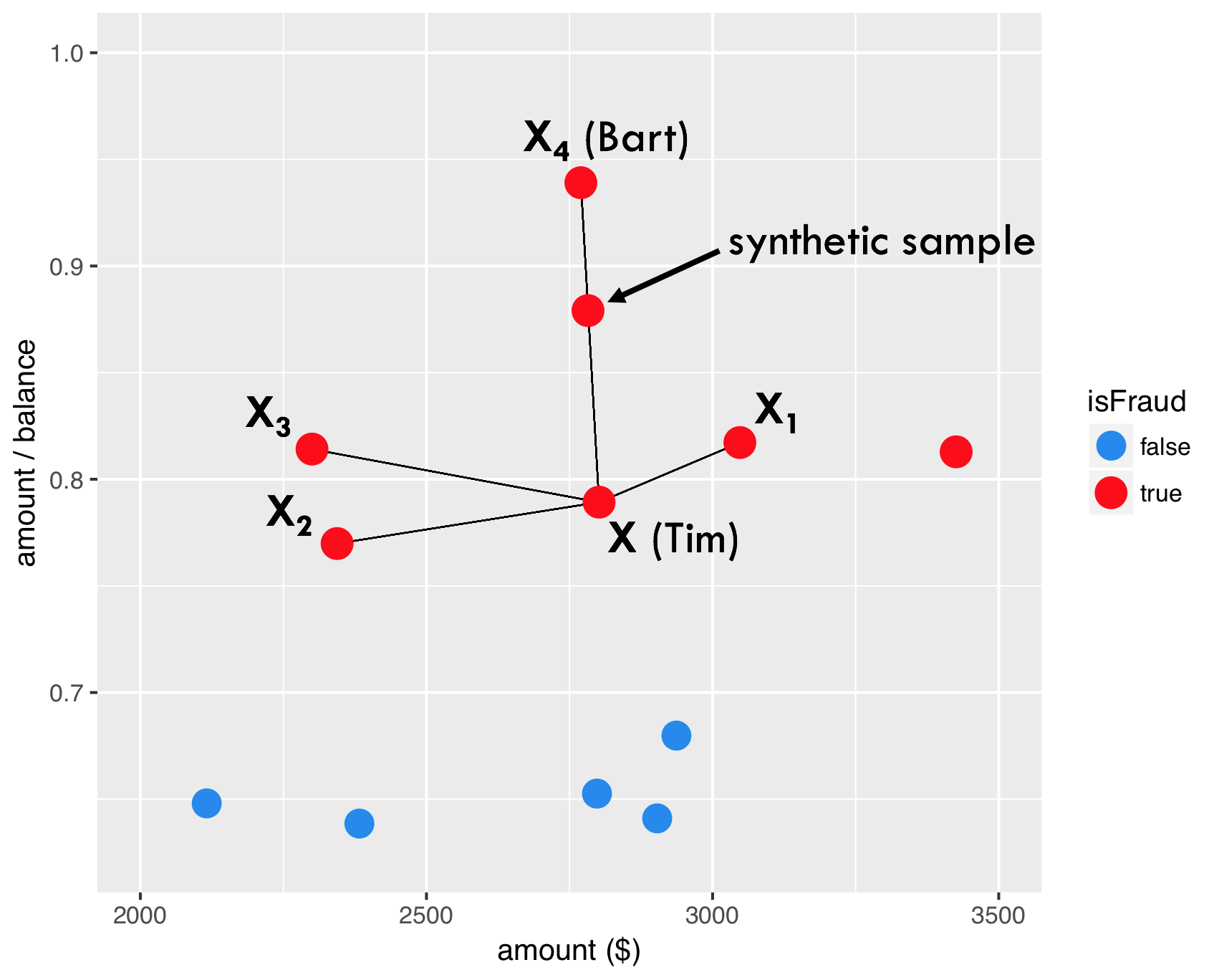
SMOTE - step 4