Other word clouds and word networks
Text Mining with Bag-of-Words in R

Ted Kwartler
Instructor
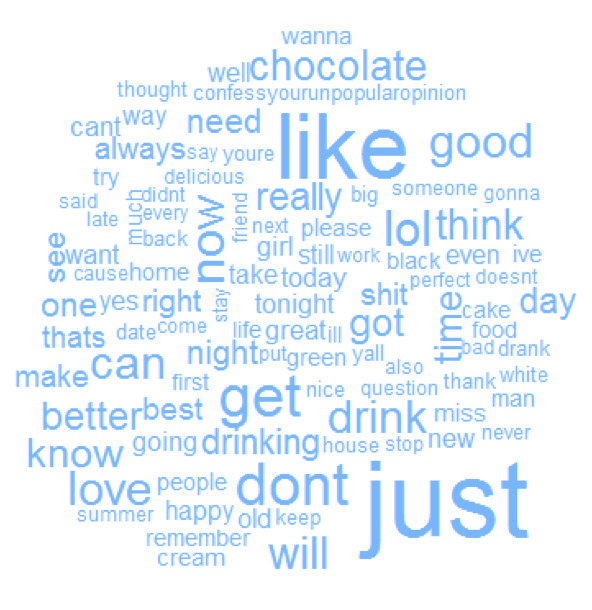
Commonality clouds
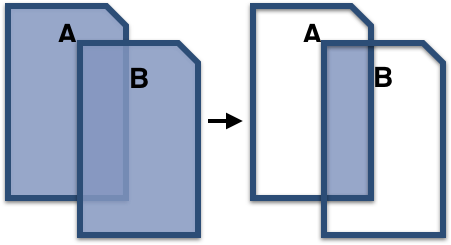
Commonality clouds
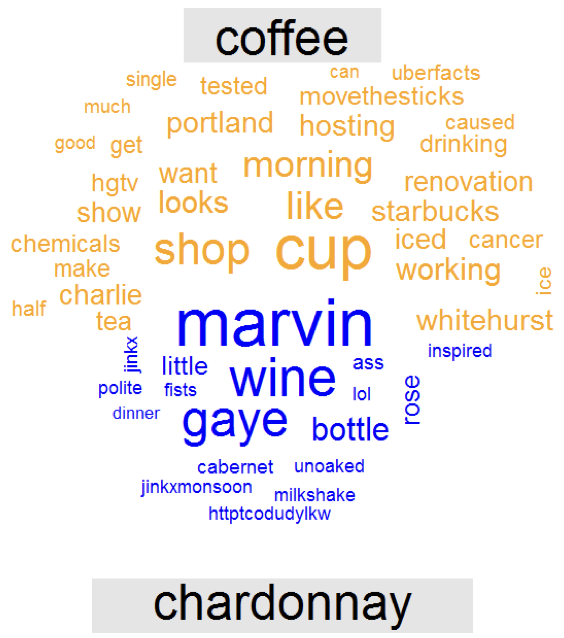
Comparison clouds
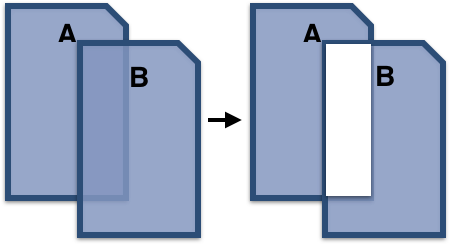
Comparison clouds
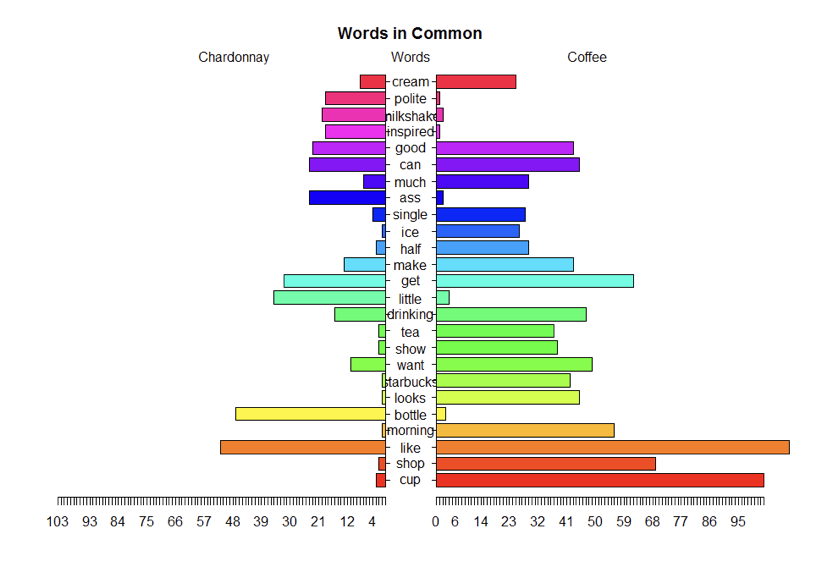
Pyramid plots
Word networks

Text Mining with Bag-of-Words in R
Ted Kwartler
Instructor

