Tokenizing and cleaning
Introduction to Text Analysis in R

Maham Faisal Khan
Senior Data Science Content Developer
Using tidytext

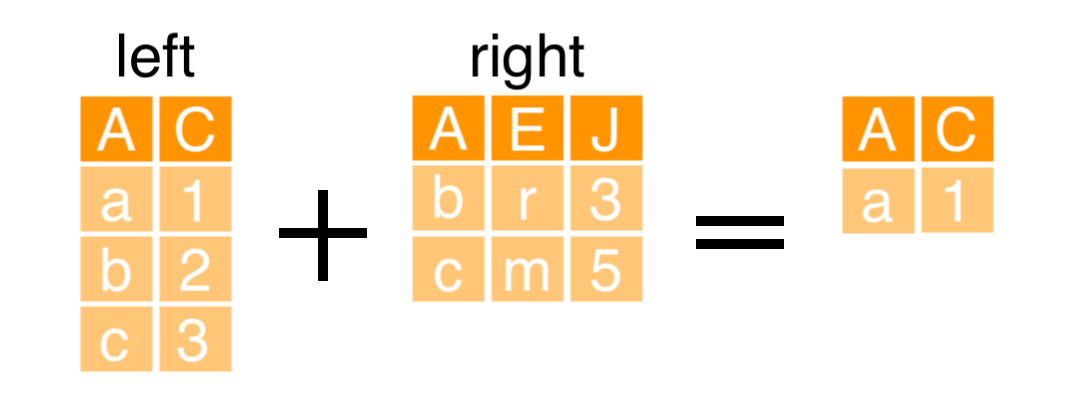
Using anti_join()
- We'd like to remove stop words from our tidied data frame
- We'll use joins to do this
Introduction to Text Analysis in R
Maham Faisal Khan
Senior Data Science Content Developer

