Columns with multiple values
Reshaping Data with tidyr

Jeroen Boeye
Head of Machine Learning, Faktion
Separating variables over columns


Multiple values in a single cell
Netflix data
Drinks data
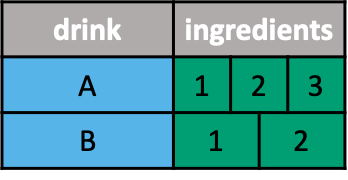
Multiple values in a single cell
Netflix data
Drinks data
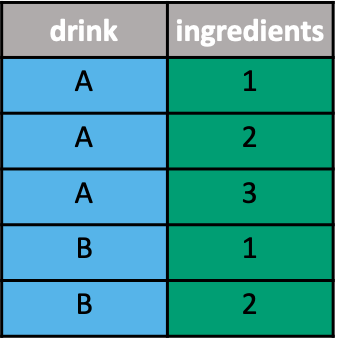
Values to variables
Multiple values in a single cell
Netflix data
Drinks data
Values to variables
Values to observations
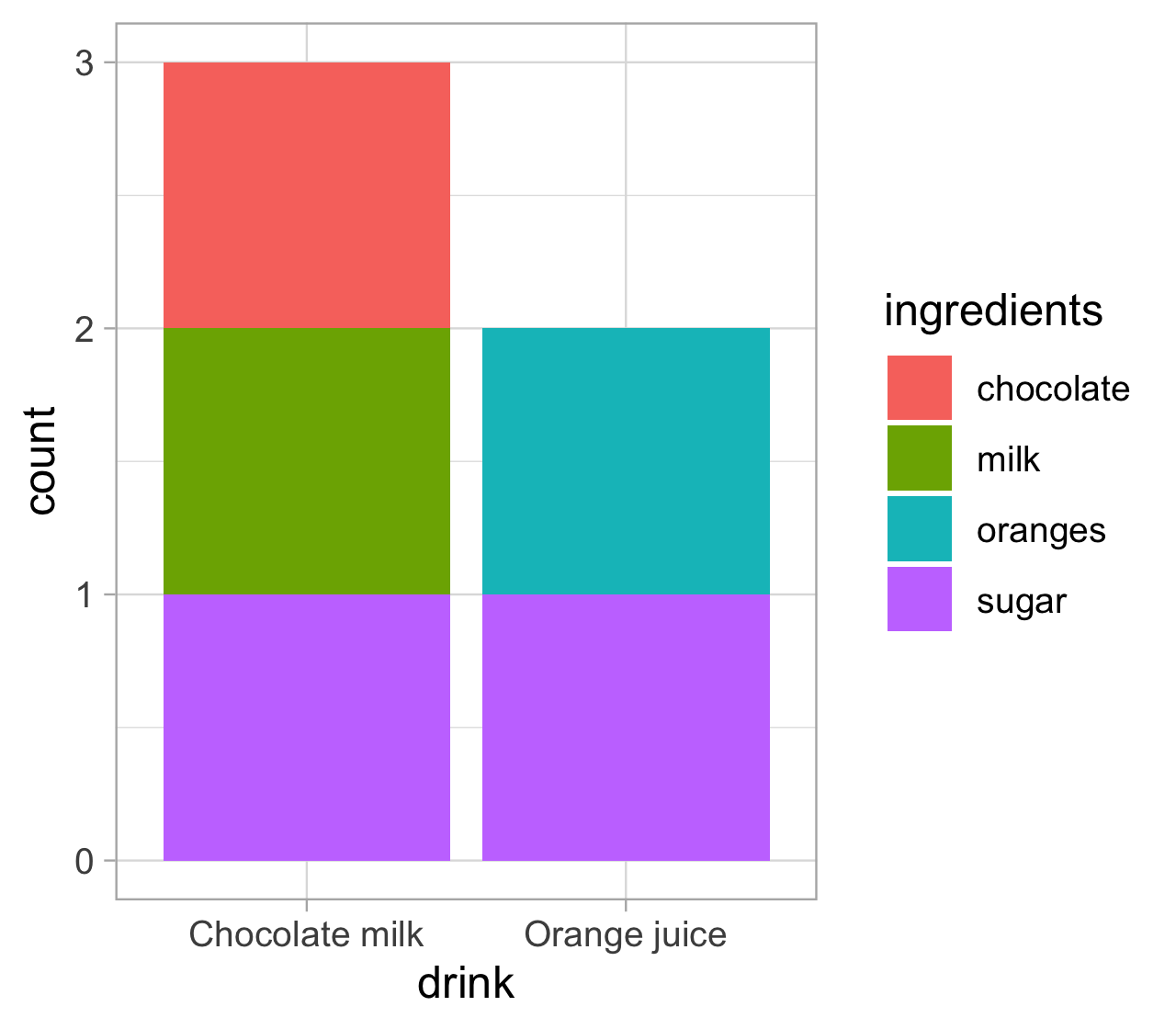
Visualizing ingredients