Outlier-robust feature scaling
Anomaly Detection in Python

Bekhruz (Bex) Tuychiev
Kaggle Master, Data Science Content Creator
Euclidean distance
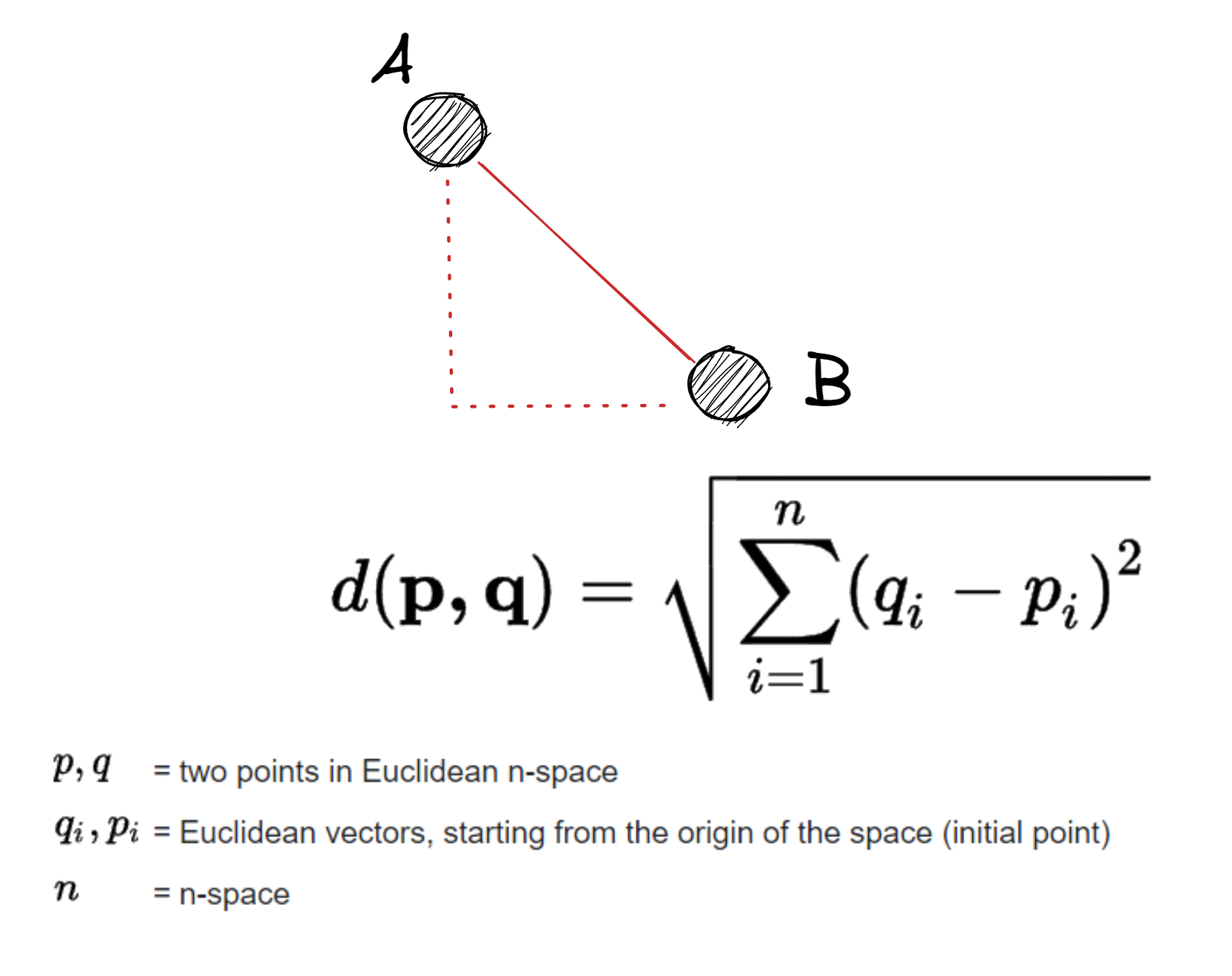
Euclidean in SciPy
Preserving column names
qt = QuantileTransformer()
X.loc[:, :] = qt.fit_transform(X)
X.head()

Uniform histogram

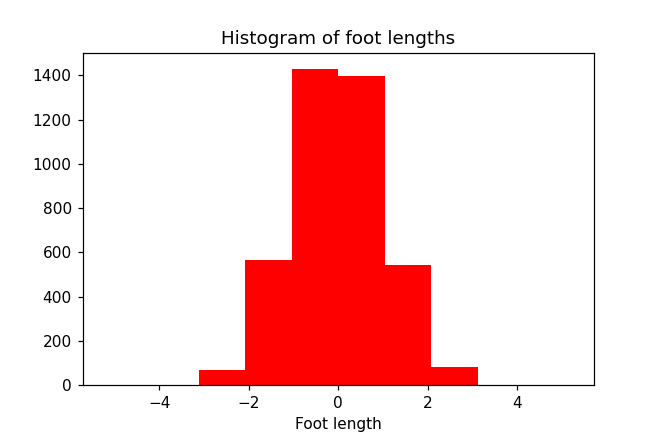
Normal histogram