Data validation
Exploratory Data Analysis in Python

Izzy Weber
Curriculum Manager, DataCamp
Validating numerical data
sns.boxplot(data=books, x="year")
plt.show()
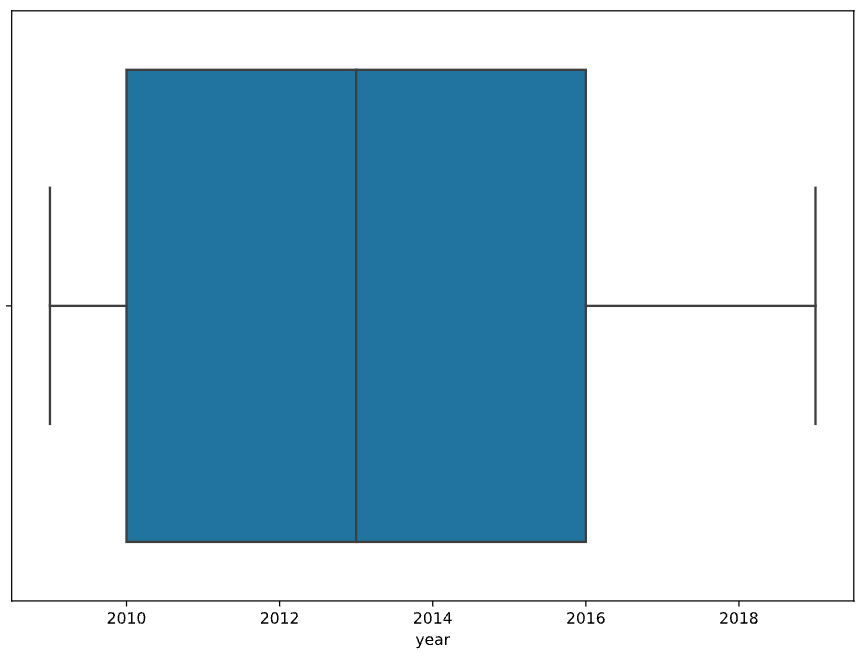
Validating numerical data
sns.boxplot(data=books, x="year", y="genre")
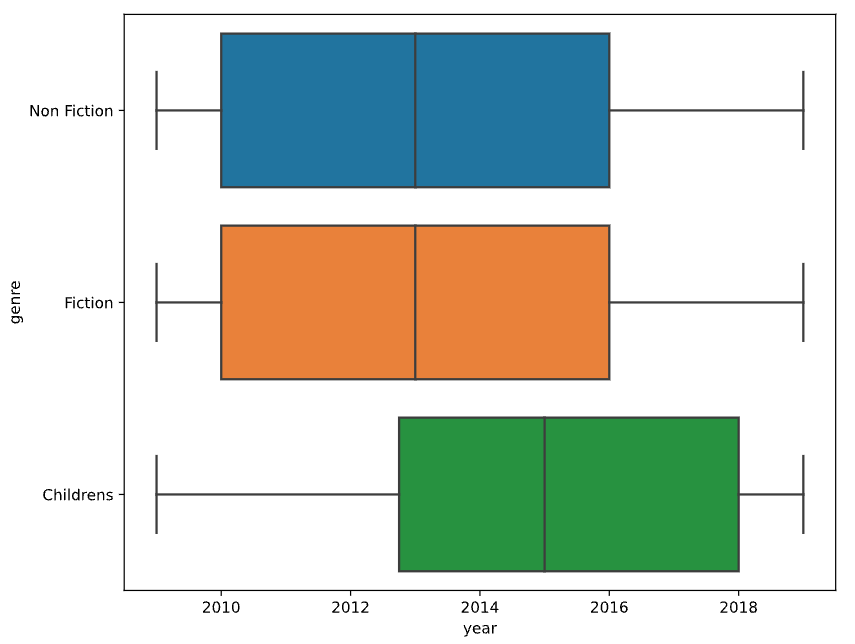
Exploratory Data Analysis in Python
Izzy Weber
Curriculum Manager, DataCamp
sns.boxplot(data=books, x="year")
plt.show()
sns.boxplot(data=books, x="year", y="genre")

