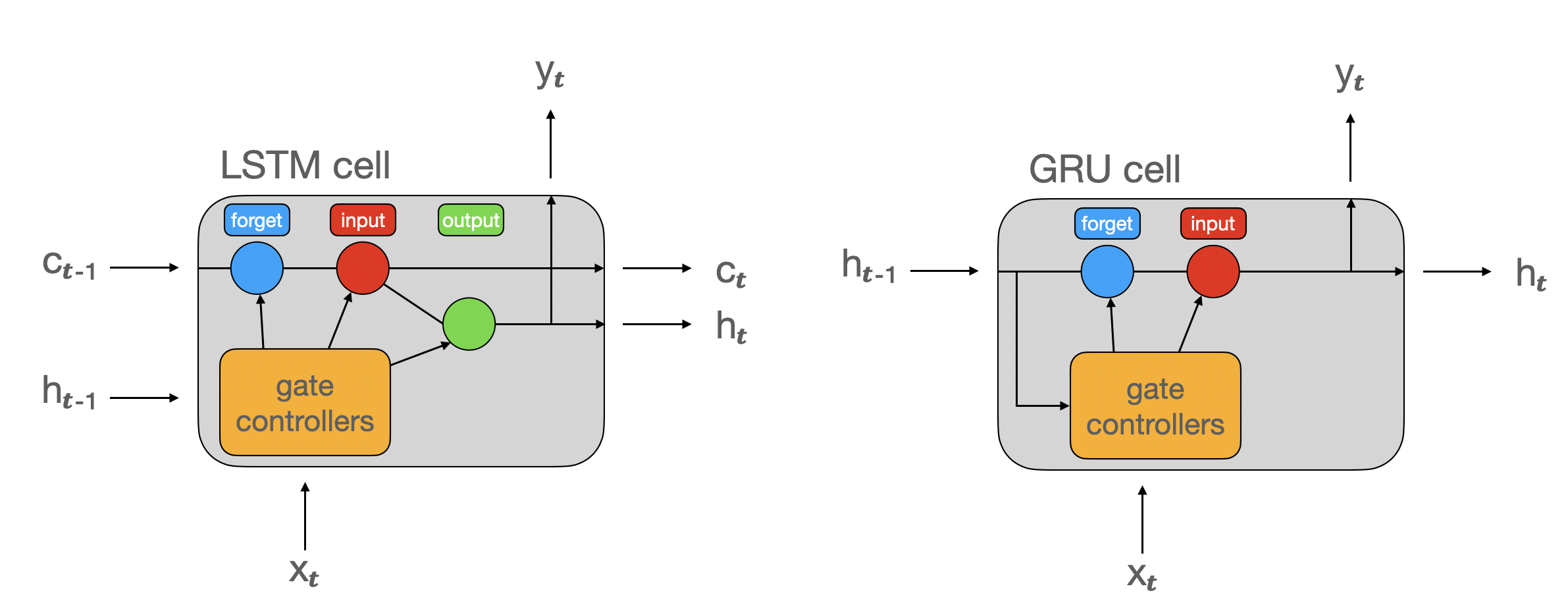
LSTM and GRU cells
Intermediate Deep Learning with PyTorch

Michal Oleszak
Machine Learning Engineer
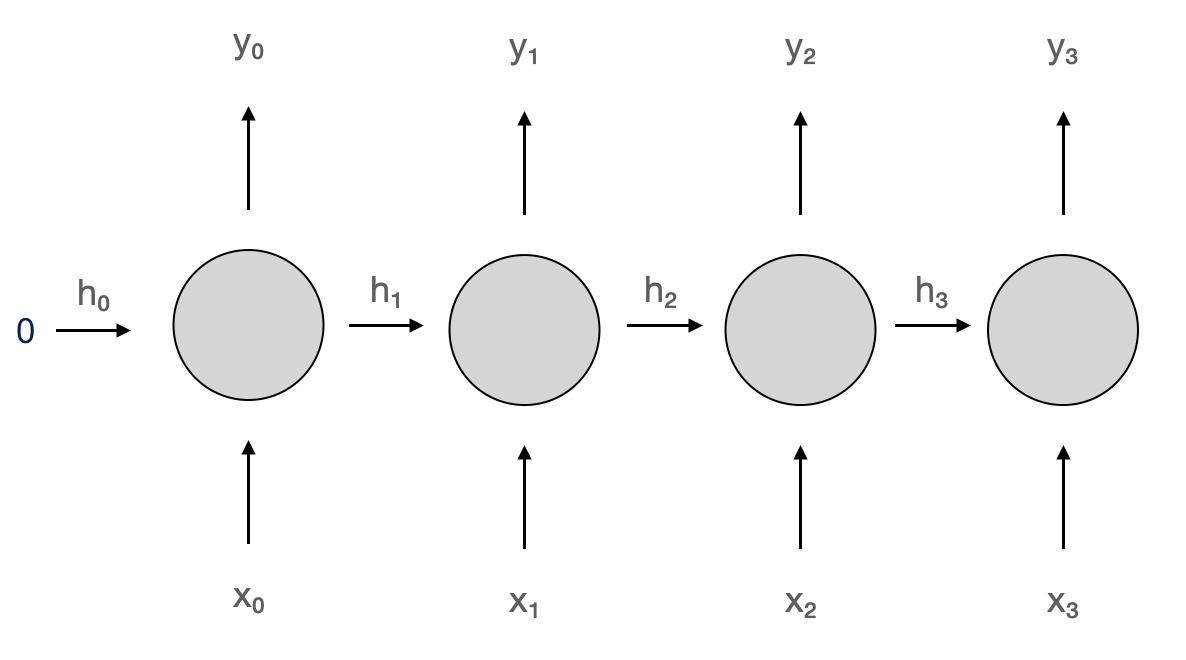
Short-term memory problem
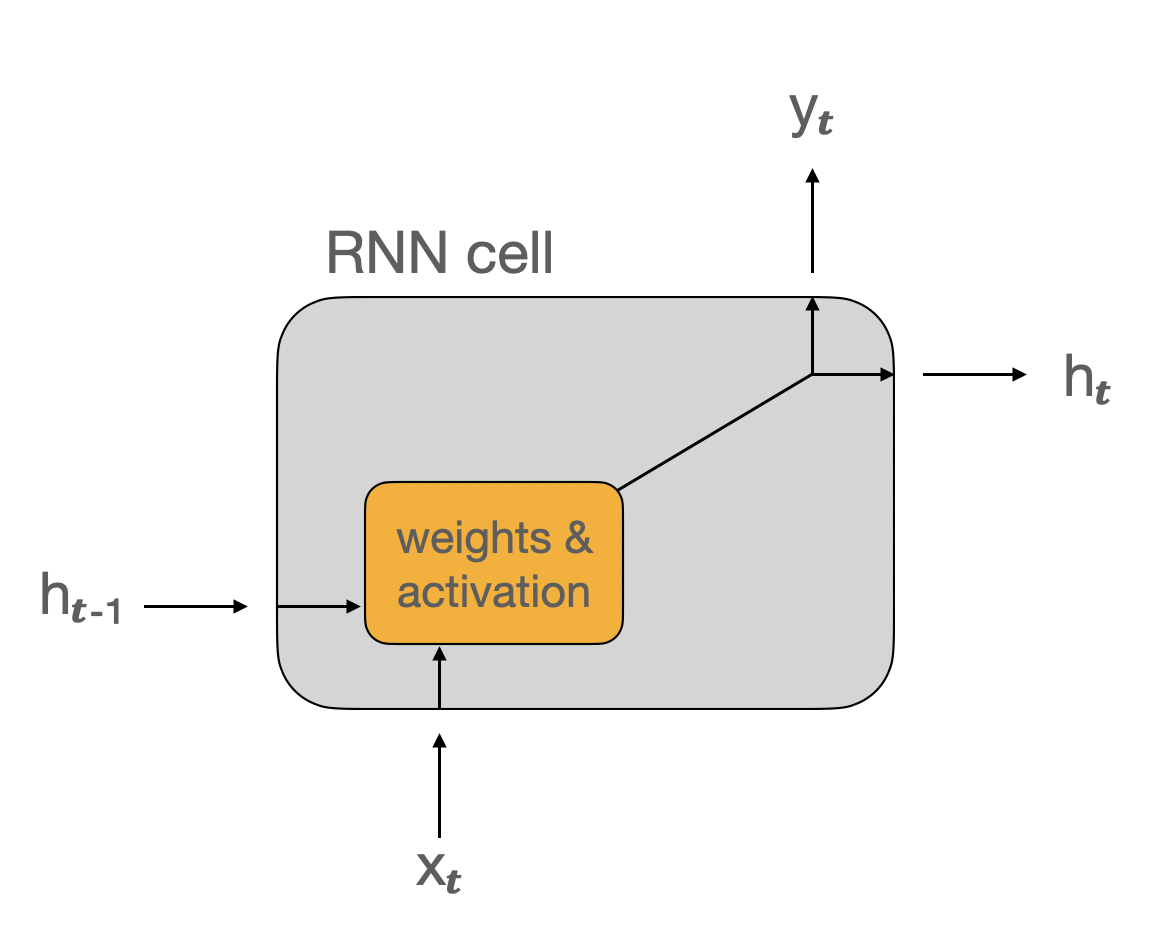
RNN cell
LSTM cell
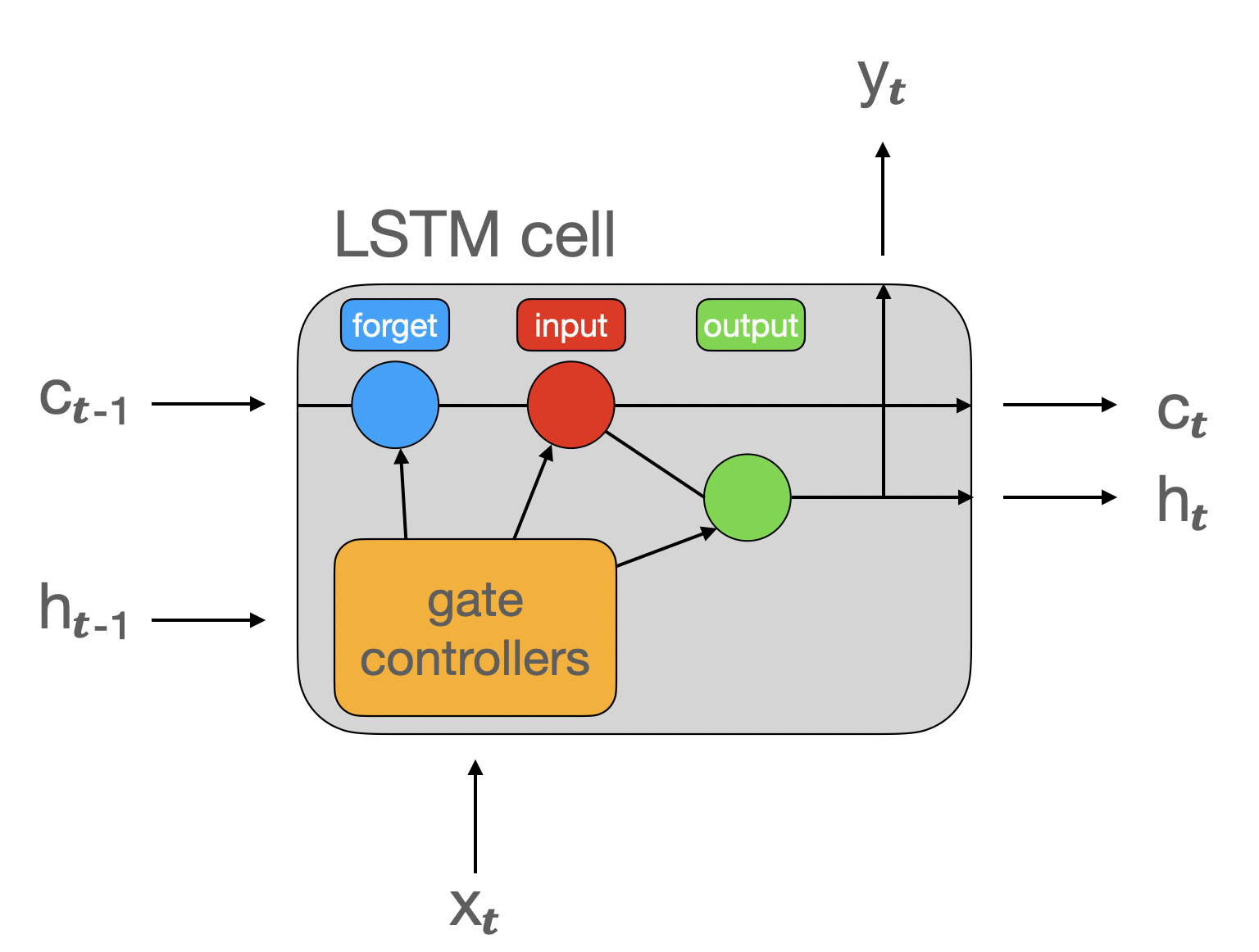
- Outputs
handyare the same
GRU cell

Should I use RNN, LSTM, or GRU?
- RNN is not used much anymore
- GRU is simpler than LSTM = less computation
- Relative performance varies per use-case
- Try both and compare