Model fine-tuning using human feedback
Introduction to LLMs in Python

Iván Palomares Carrascosa, PhD
Senior Data Science & AI Manager
Why human feedback in LLMs
"What makes an LLM good?", "What is the LLM user looking for?"
- Objective, subjective and context-dependent criteria
- Truthfulness, originality, fine-grained detail vs. concise responses, etc.
- Objective metrics cannot fully capture subjective quality in LLM outputs
- Use human feedback as a guide (loss function) to optimize LLM outputs

Reinforcement Learning from Human Feedback (RLHF)
Reinforcement Learning (RL): an agent learns to make decisions upon feedback -rewards-, adapting its behavior to maximize cumulative reward over time
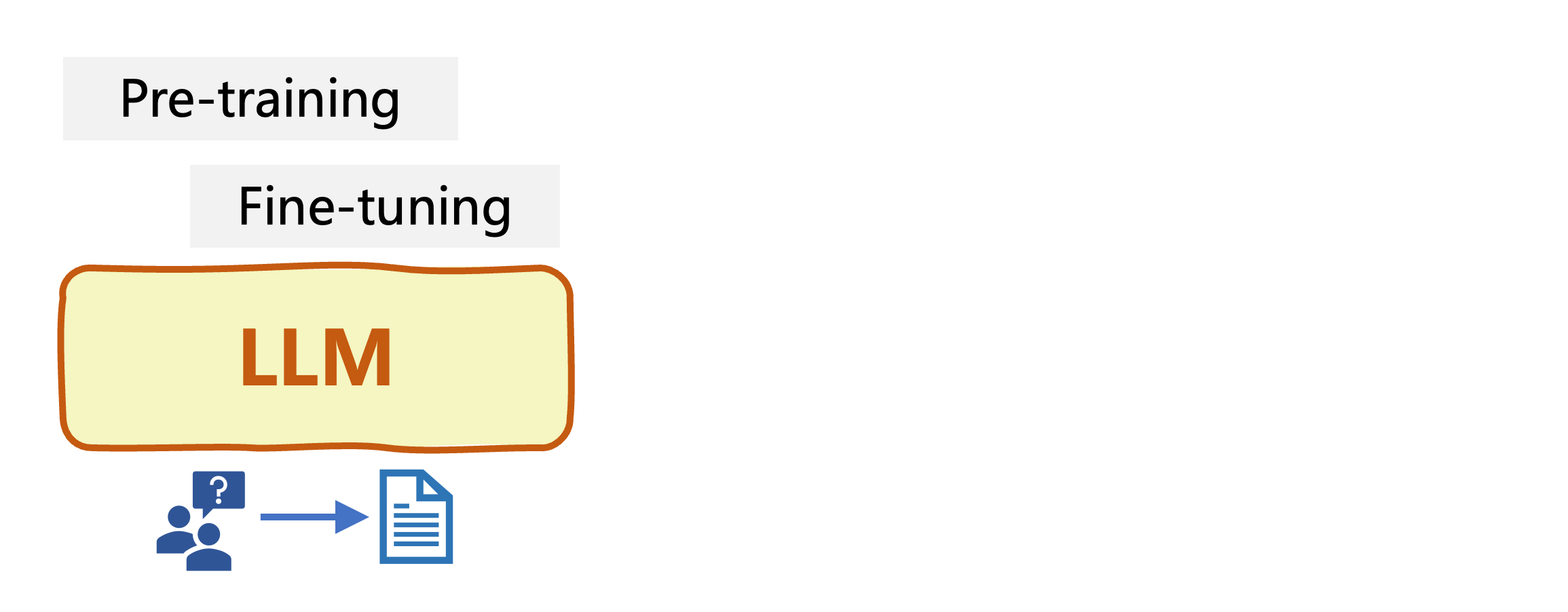
- Initial LLM
Reinforcement Learning from Human Feedback (RLHF)
Reinforcement Learning (RL): an agent learns to make decisions upon feedback -rewards-, adapting its behavior to maximize cumulative reward over time
- Initial LLM
- Train a Reward Model (RM)
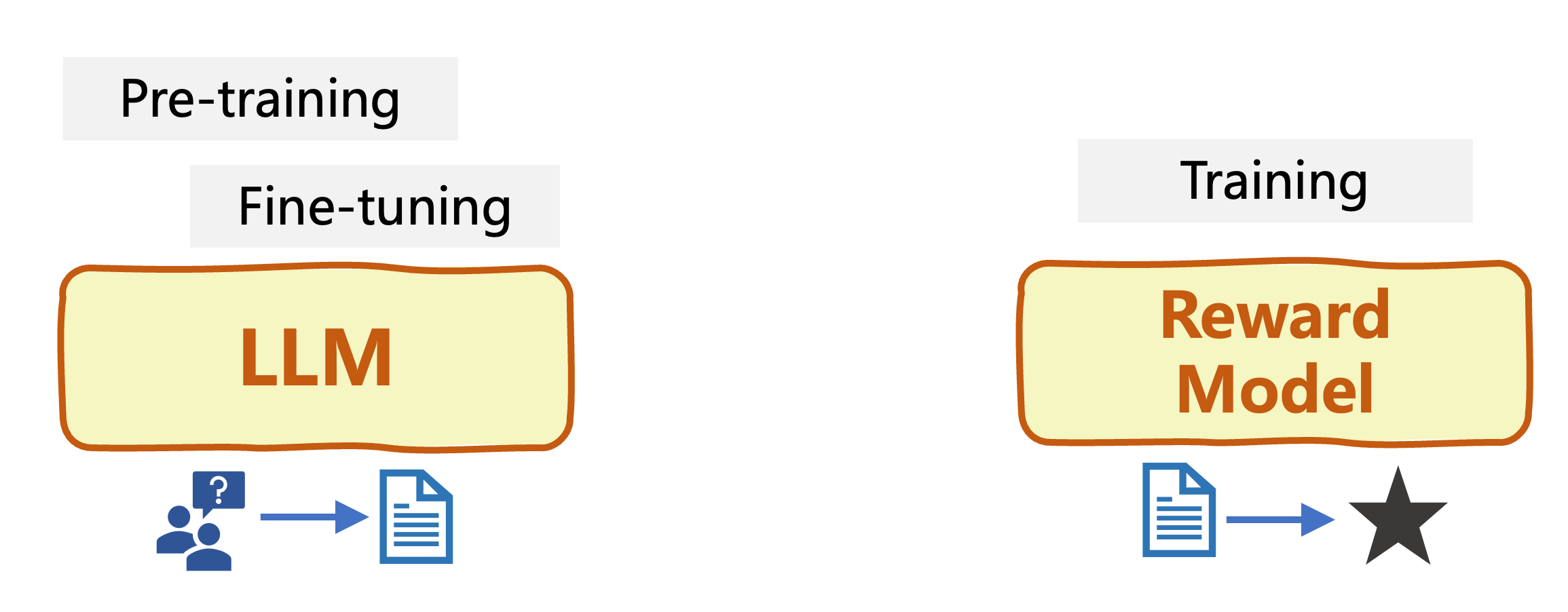
Reinforcement Learning from Human Feedback (RLHF)
Reinforcement Learning (RL): an agent learns to make decisions upon feedback -rewards-, adapting its behavior to maximize cumulative reward over time
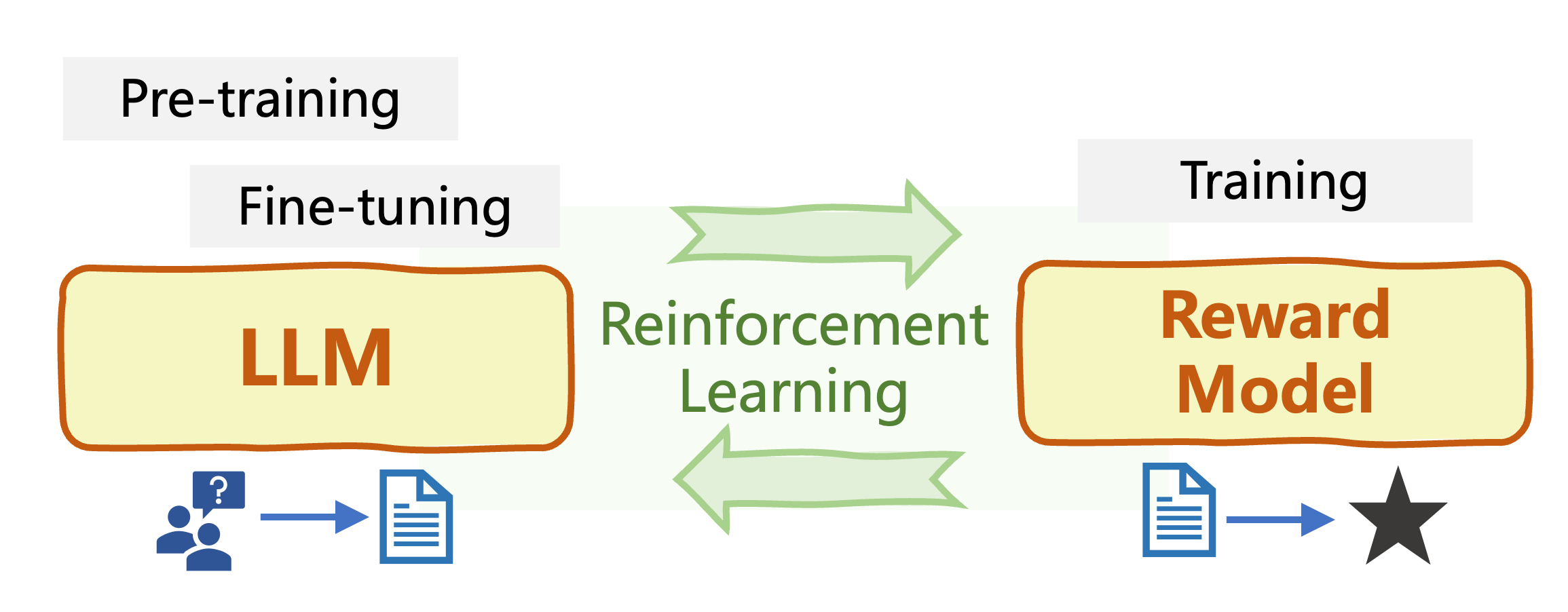
- Initial LLM
- Train a Reward Model (RM)
- Optimize (fine-tune) LLM using RL algorithm (e.g. PPO) based on trained RM
Building a reward model

- Pre-trained LLM that generates text
- Collect samples of LLM inputs-outputs
Building a reward model
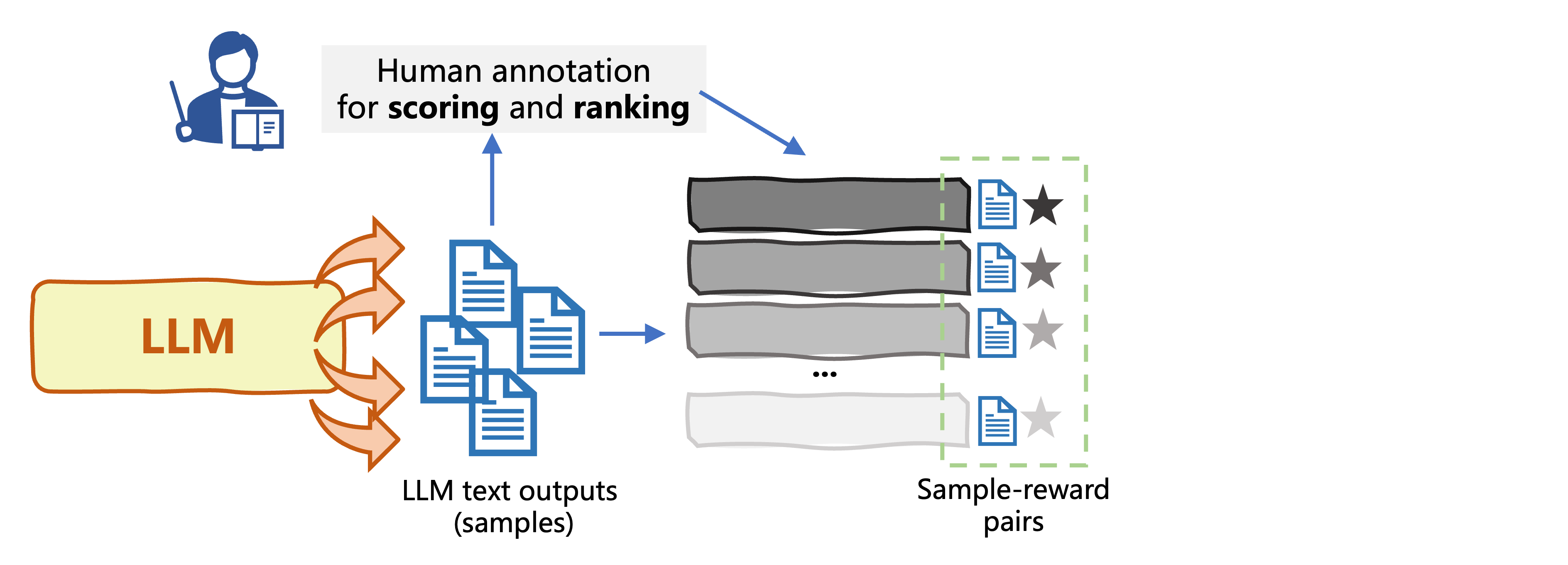
- Generate dataset to train a reward model: human preferences
- Training instances are sample-reward pairs
Building a reward model
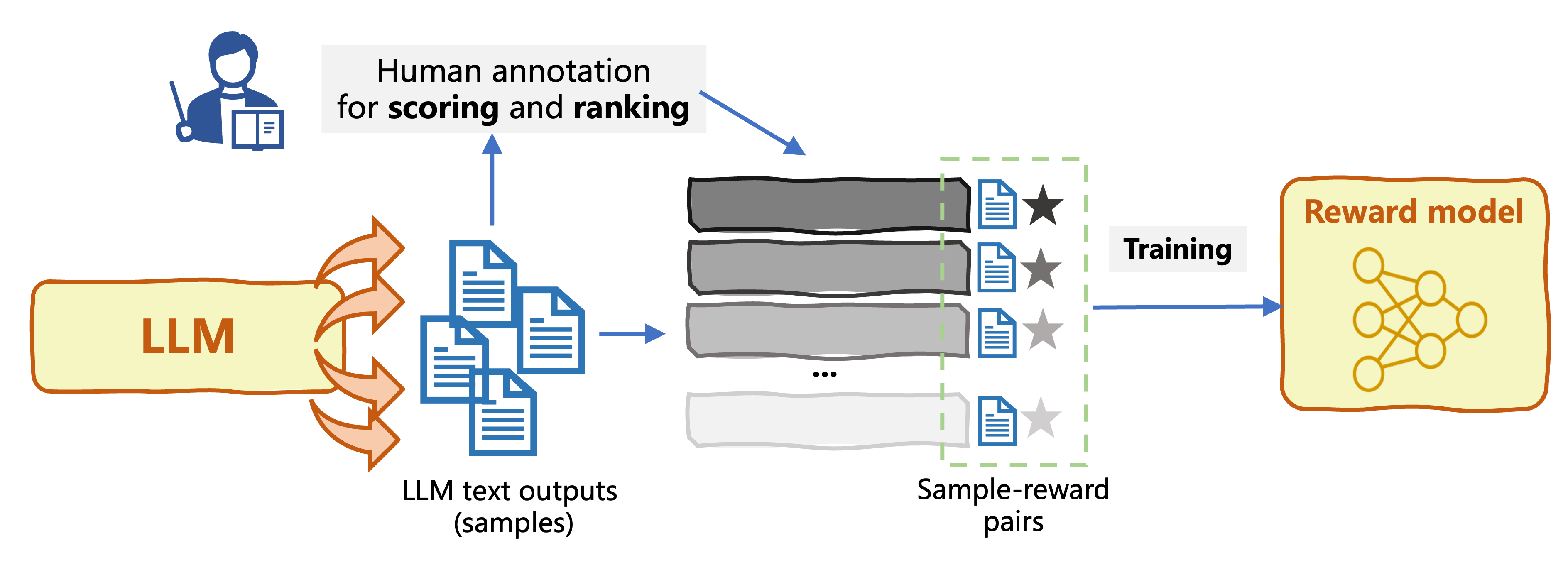
- Train Reward Model (RM) capable of predicting rewards for LLM input-outputs
Building a reward model
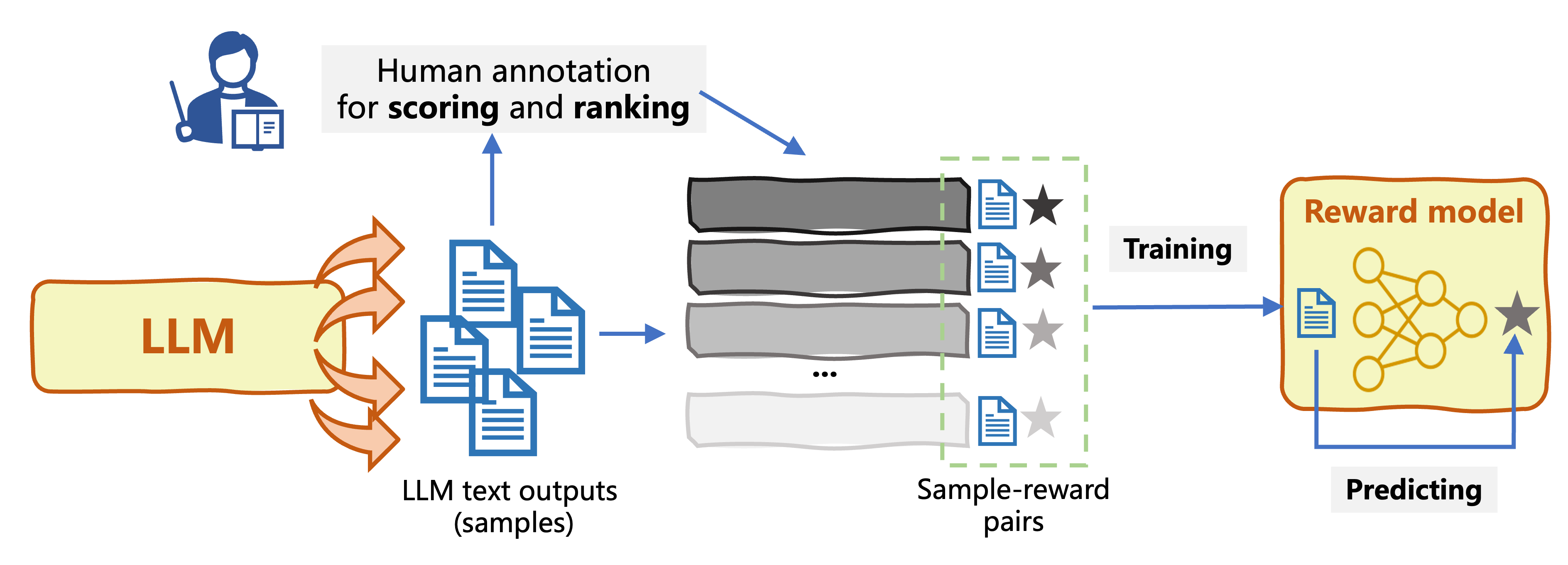
- Train Reward Model (RM) capable of predicting rewards for LLM input-outputs
- The trained RM is used by an RL algorithm to fine-tune the original LLM

