LLMs for text classification and generation
Introduction to LLMs in Python

Iván Palomares Carrascosa, PhD
Senior Data Science & AI Manager
Loading a pre-trained LLM
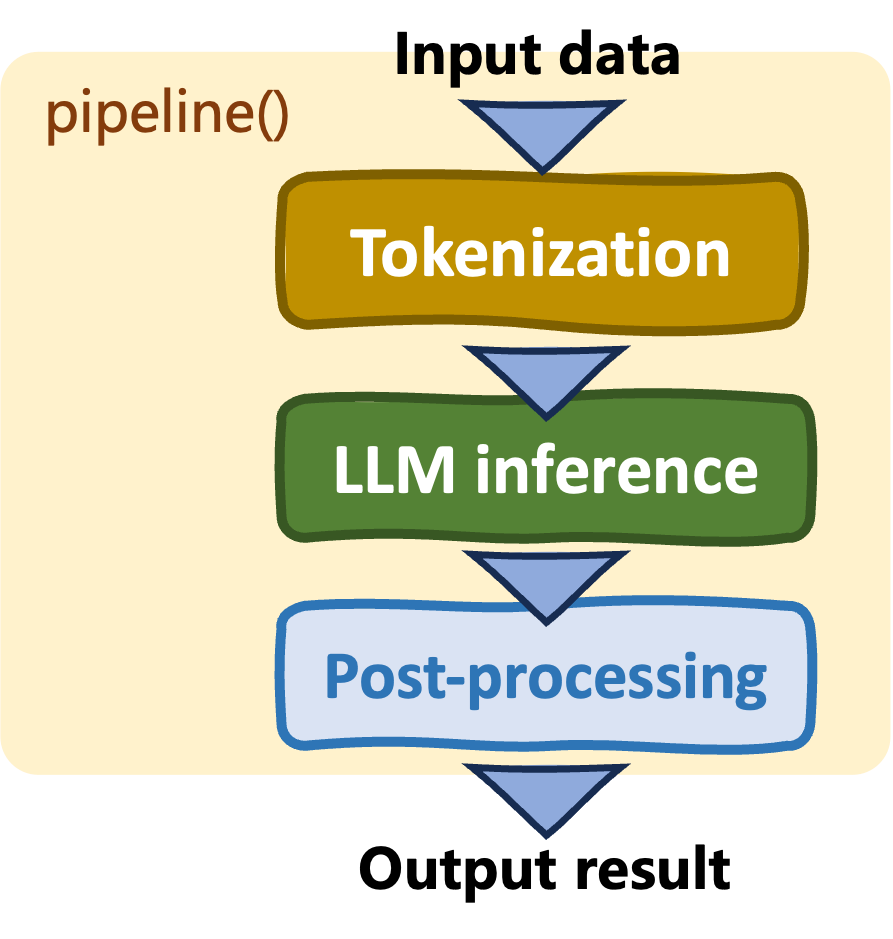
Pipelines: pipeline()
- Simple, high-level interface
- Automatic model and tokenizer selection
- More abstraction = less control
- Limited task flexibility
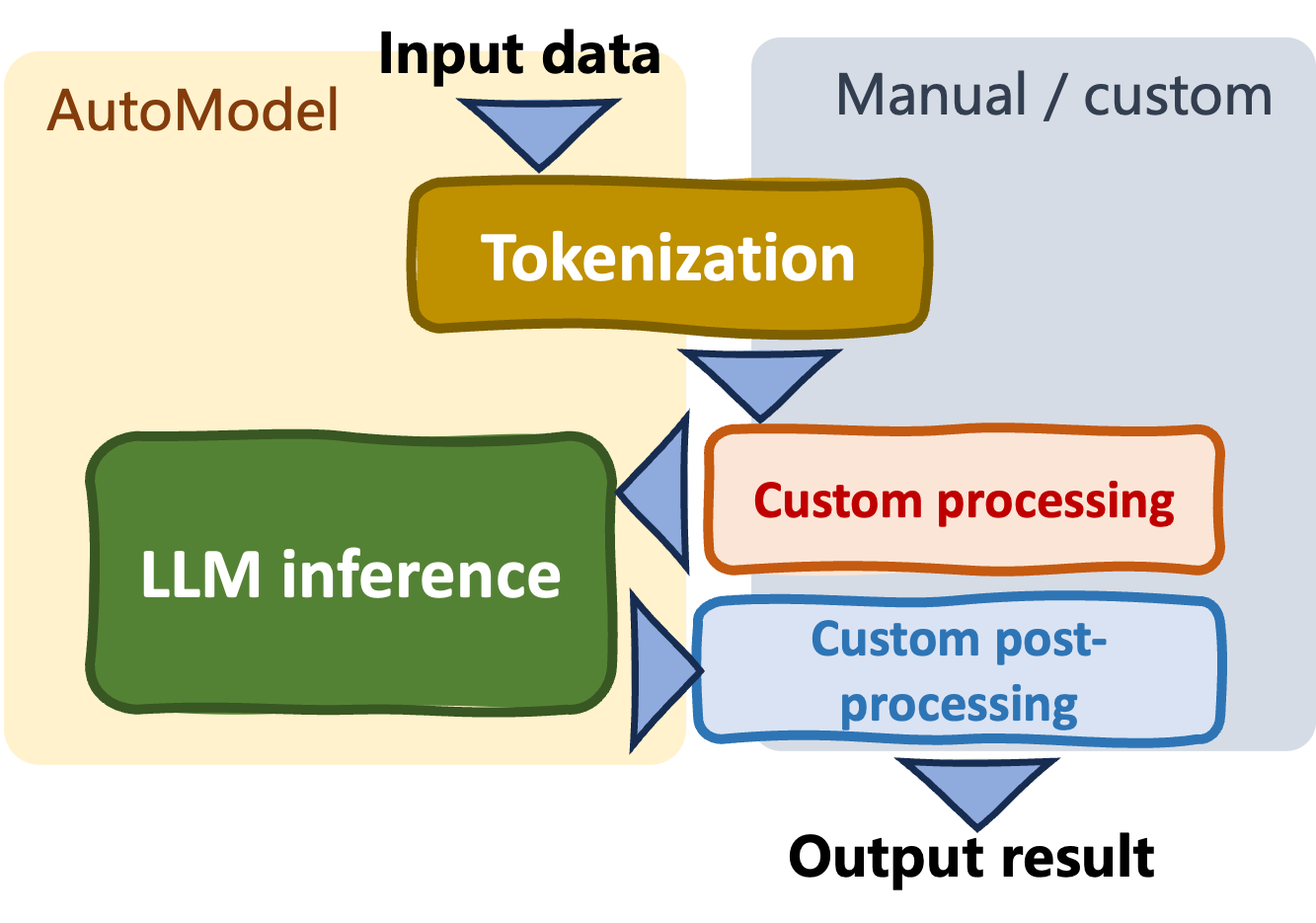
Auto classes (AutoModel class)
- Flexibility, control and customization
- Complexity: manual set-ups
- Support very diverse language tasks
- Enable model fine-tuning
How text generation LLM training works
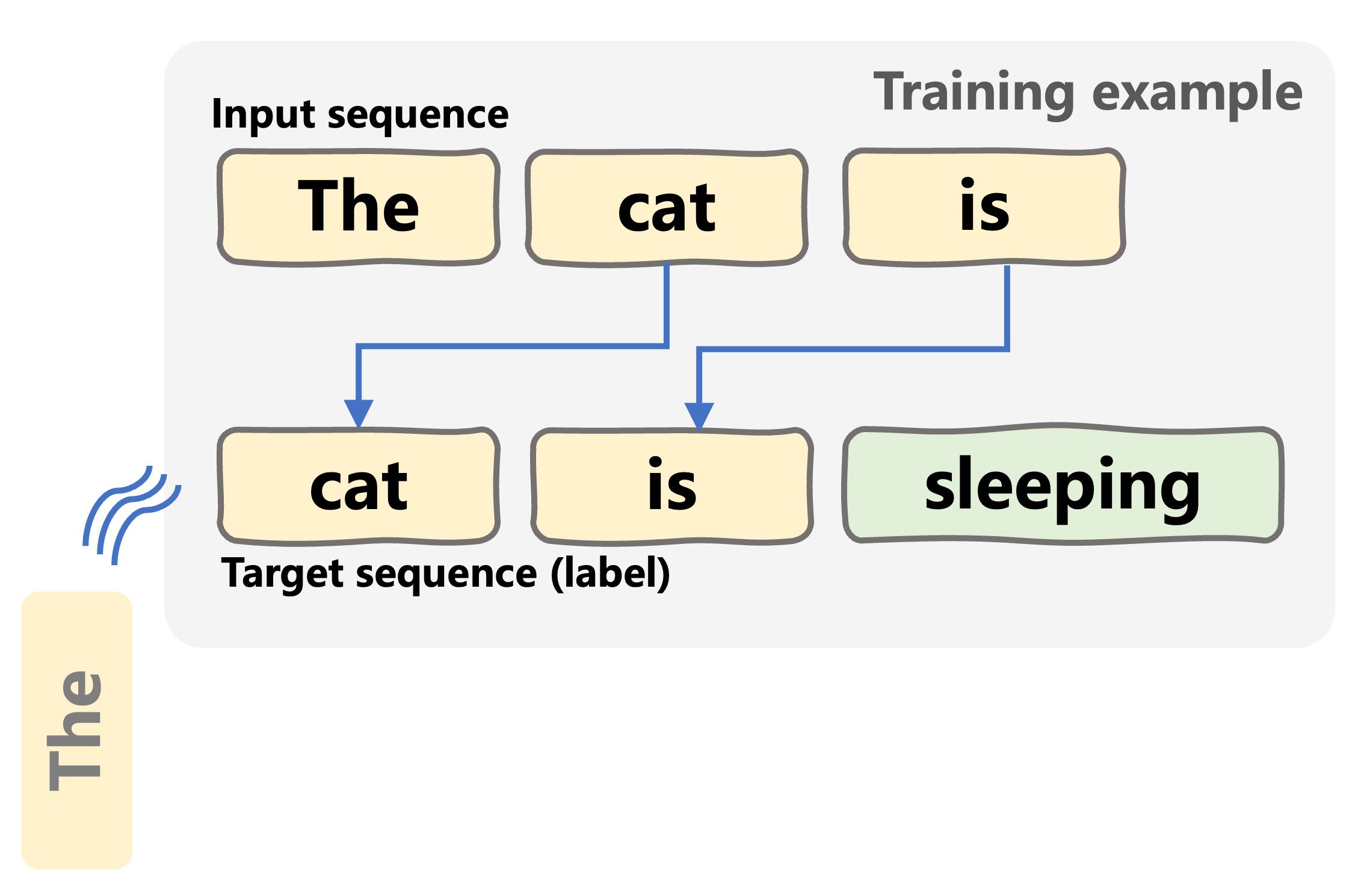
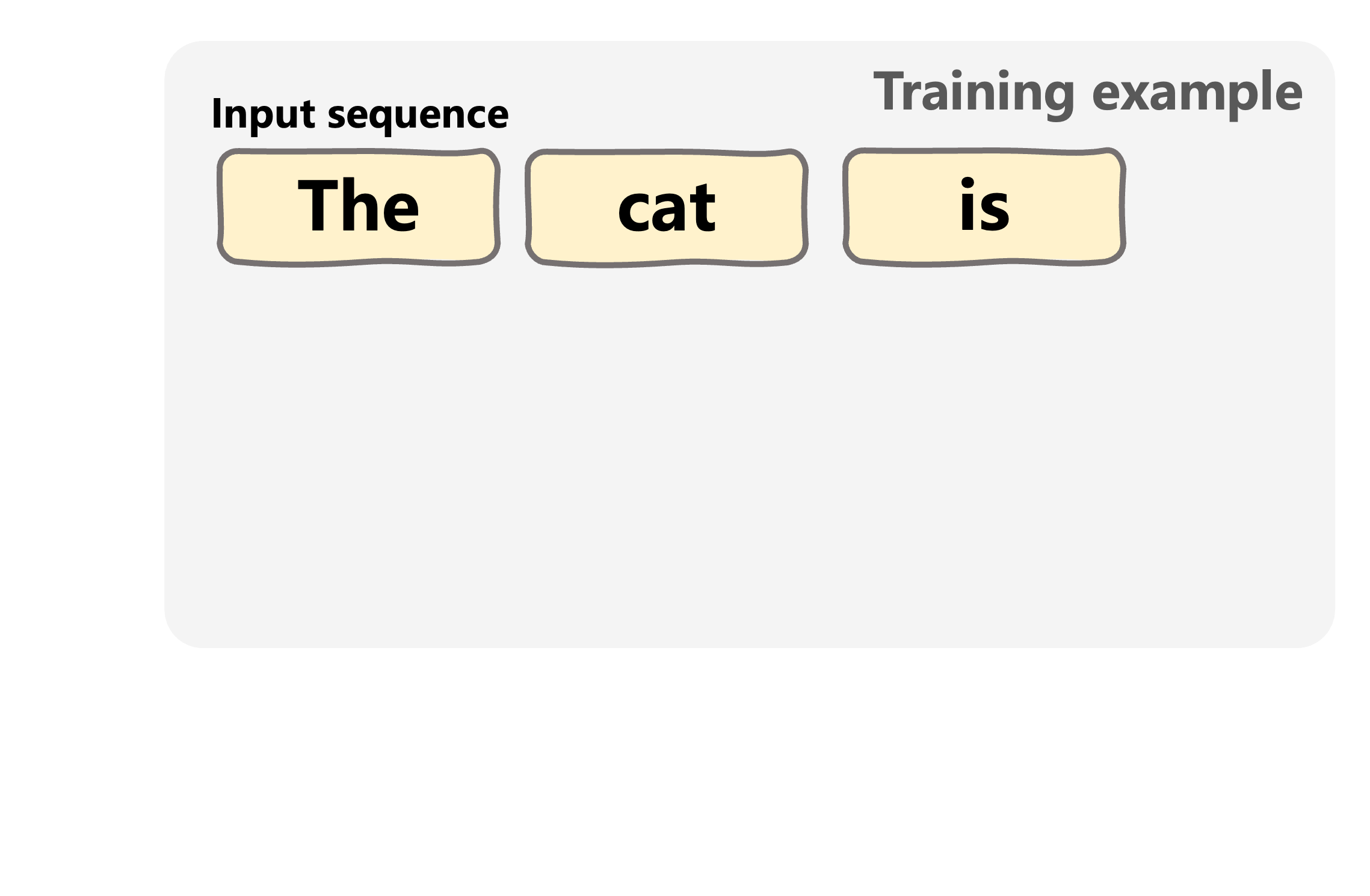
Input + target (labels) pairs
- Input sequences: a segment of the text, e.g. "the cat is" from "the cat is sleeping on the mat"
How text generation LLM training works
Input + target (labels) pairs
- Input sequences: a segment of the text, e.g. "the cat is" from "the cat is sleeping on the mat"
- Target sequences: tokens shifted one position to the left, e.g. "cat is sleeping"