Automatic speech recognition
Working with Hugging Face

Jacob H. Marquez
Lead Data Engineer
What is automatic speech recognition?

What is automatic speech recognition?
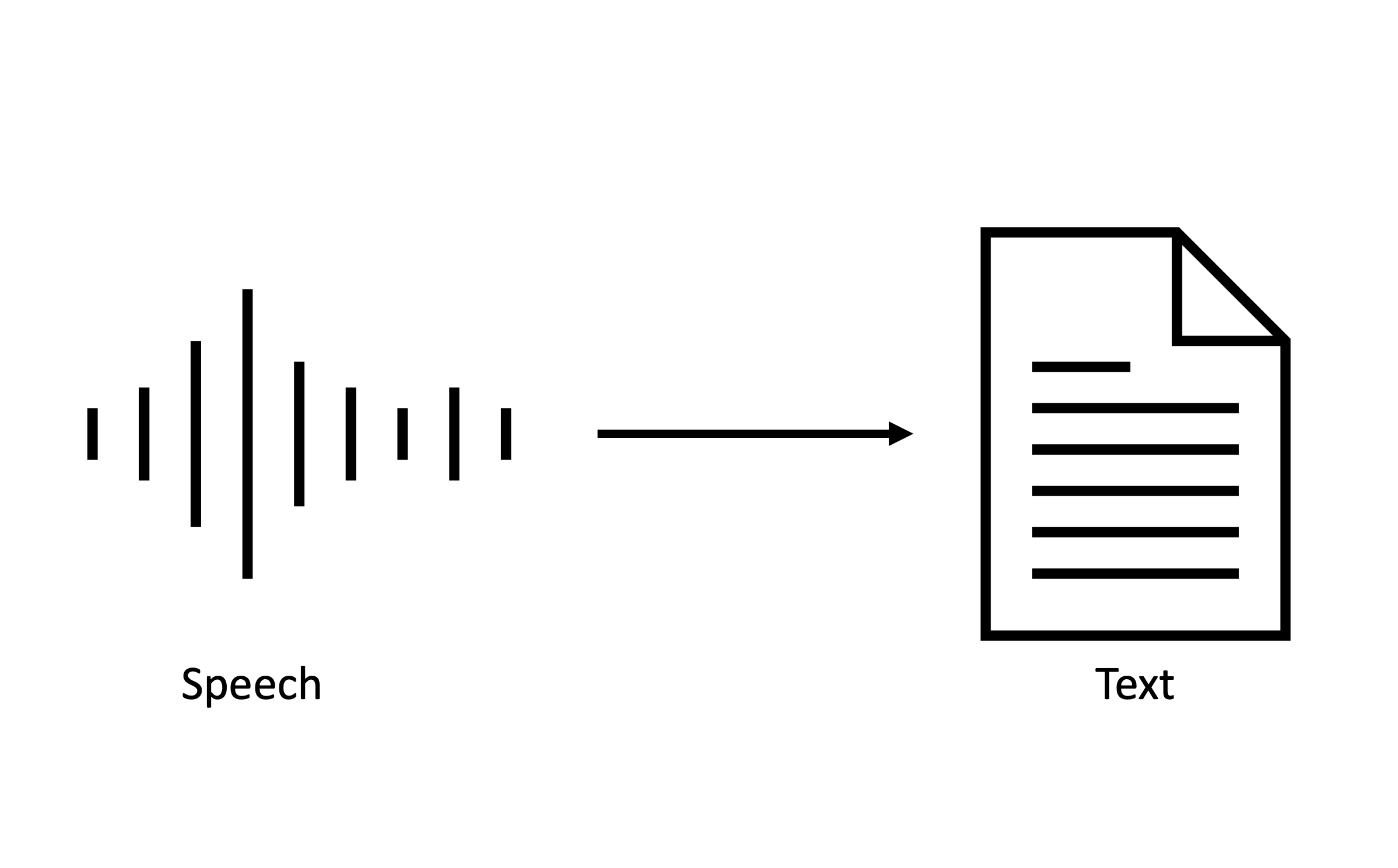
Use cases of ASR
Use cases of ASR

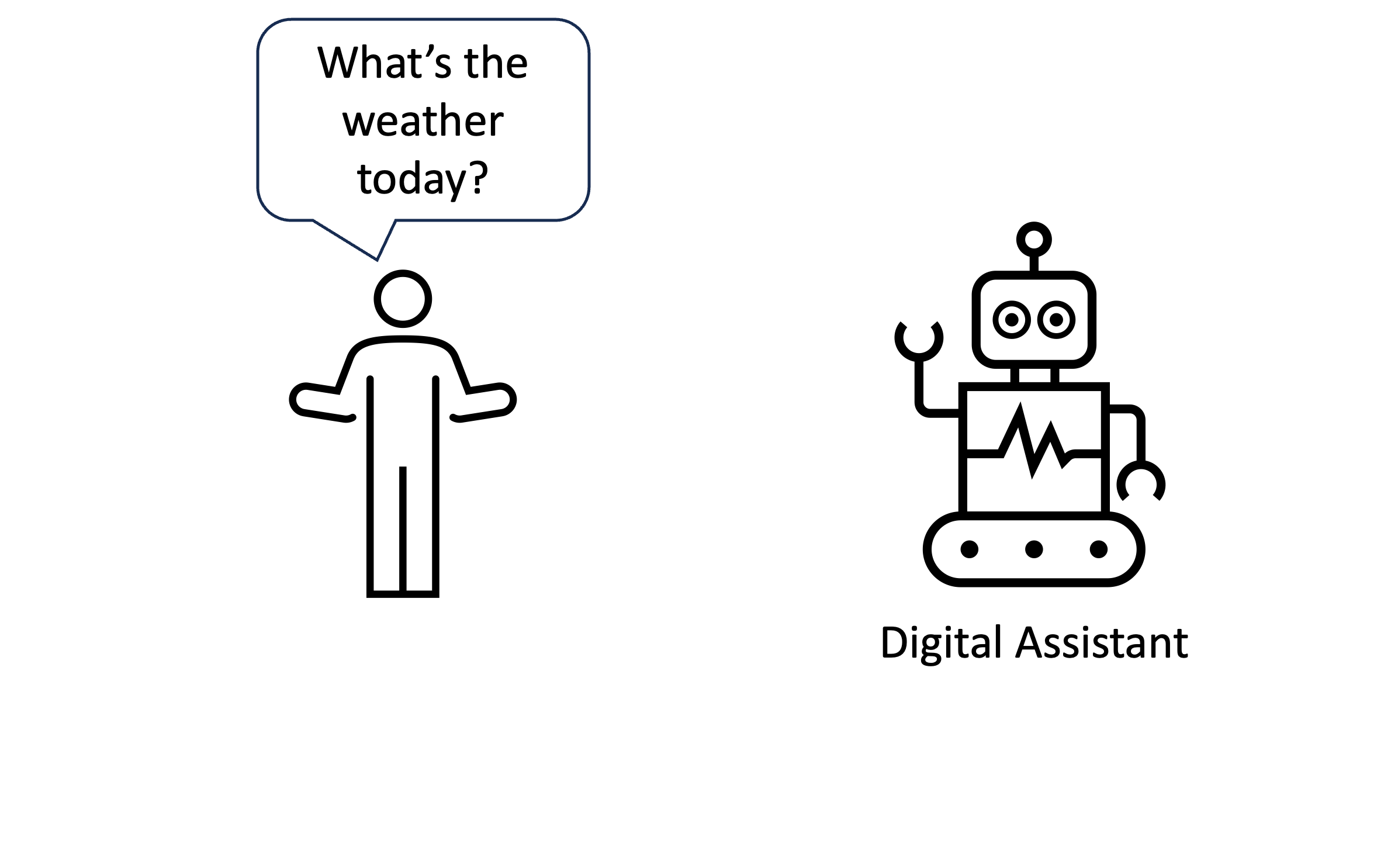
Use cases for ASR

Use cases for ASR
Models for ASR

Models for ASR

- Whisper performs better with punctuation and casing.
Evaluating ASR systems
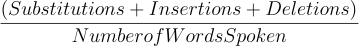
- Range from 0 to 1
- Smaller value indicates closer similarity
1 https://en.wikipedia.org/wiki/Levenshtein_distance
Word Error Rate


