Text splitting, embeddings, and vector storage
Retrieval Augmented Generation (RAG) with LangChain

Meri Nova
Machine Learning Engineer
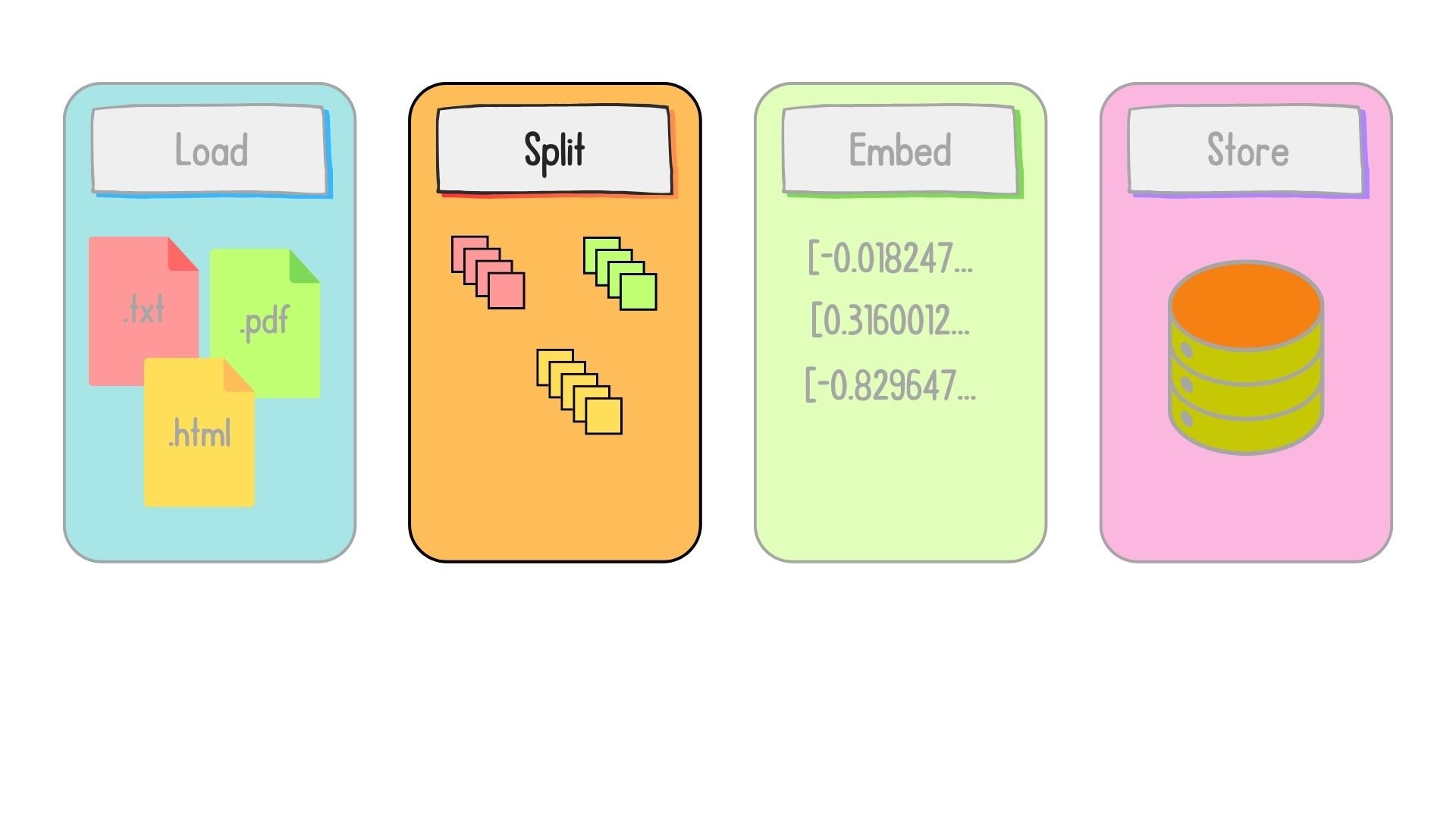
Preparing data for retrieval

Preparing data for retrieval
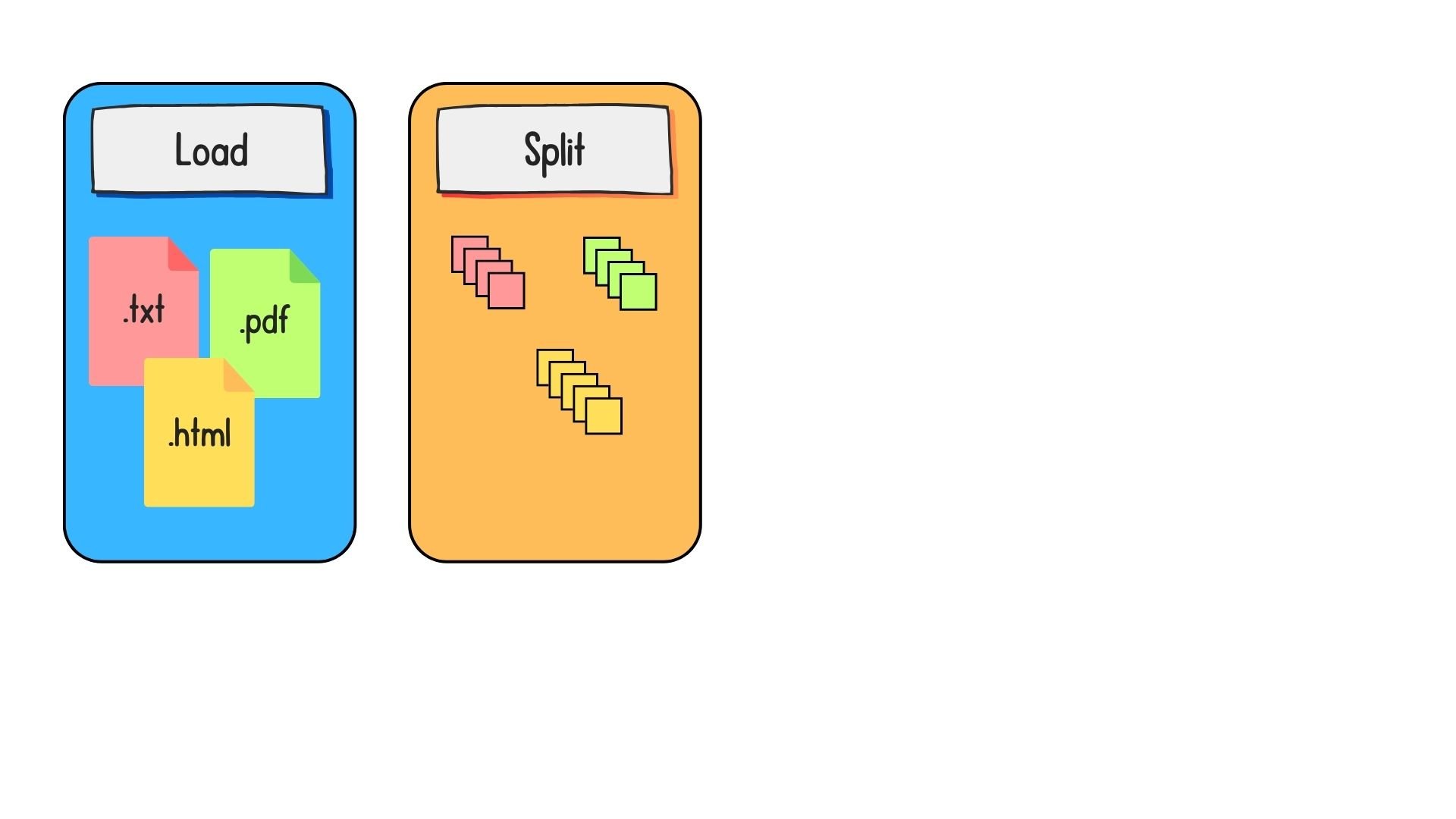
Preparing data for retrieval
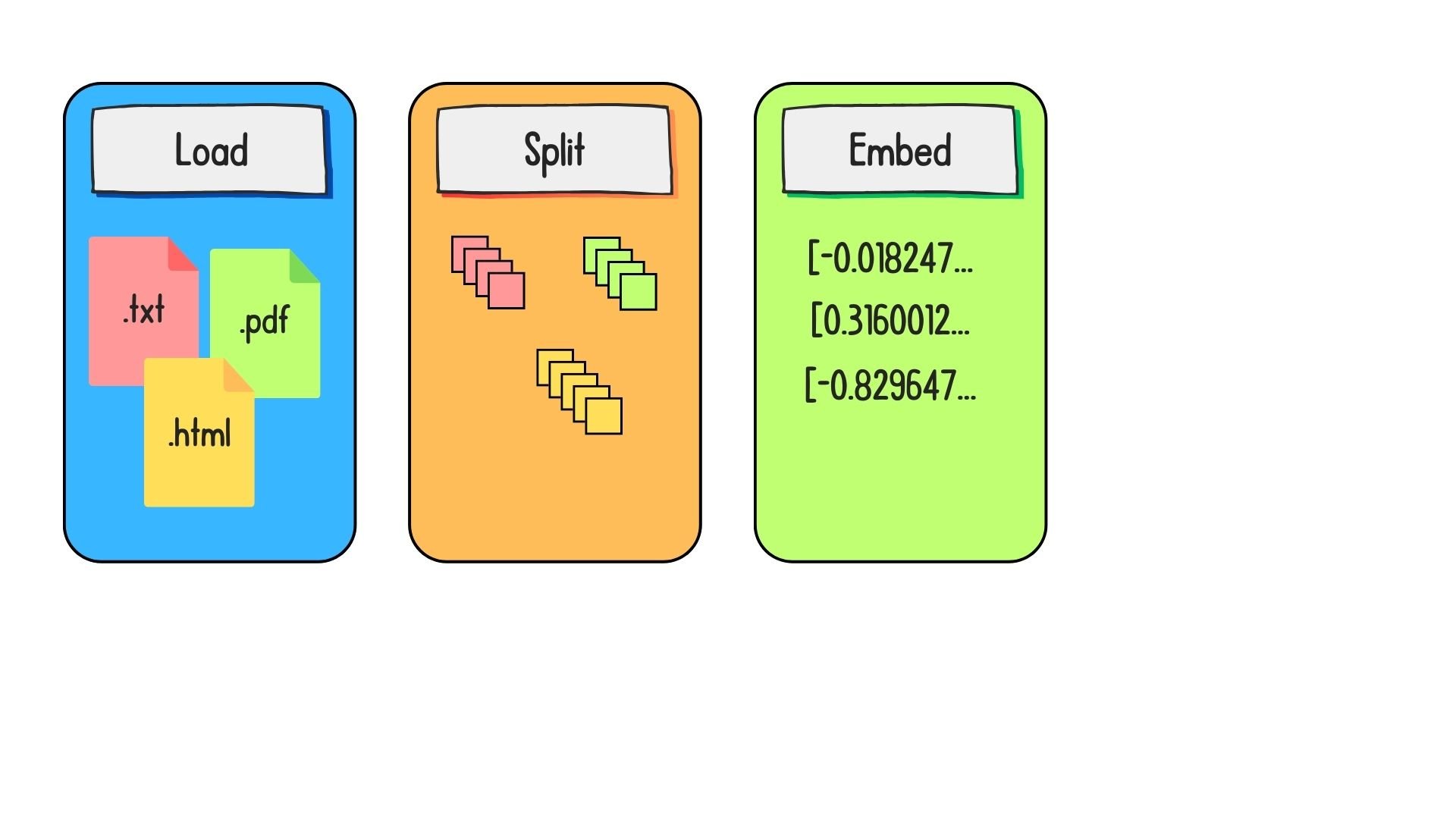
Preparing data for retrieval
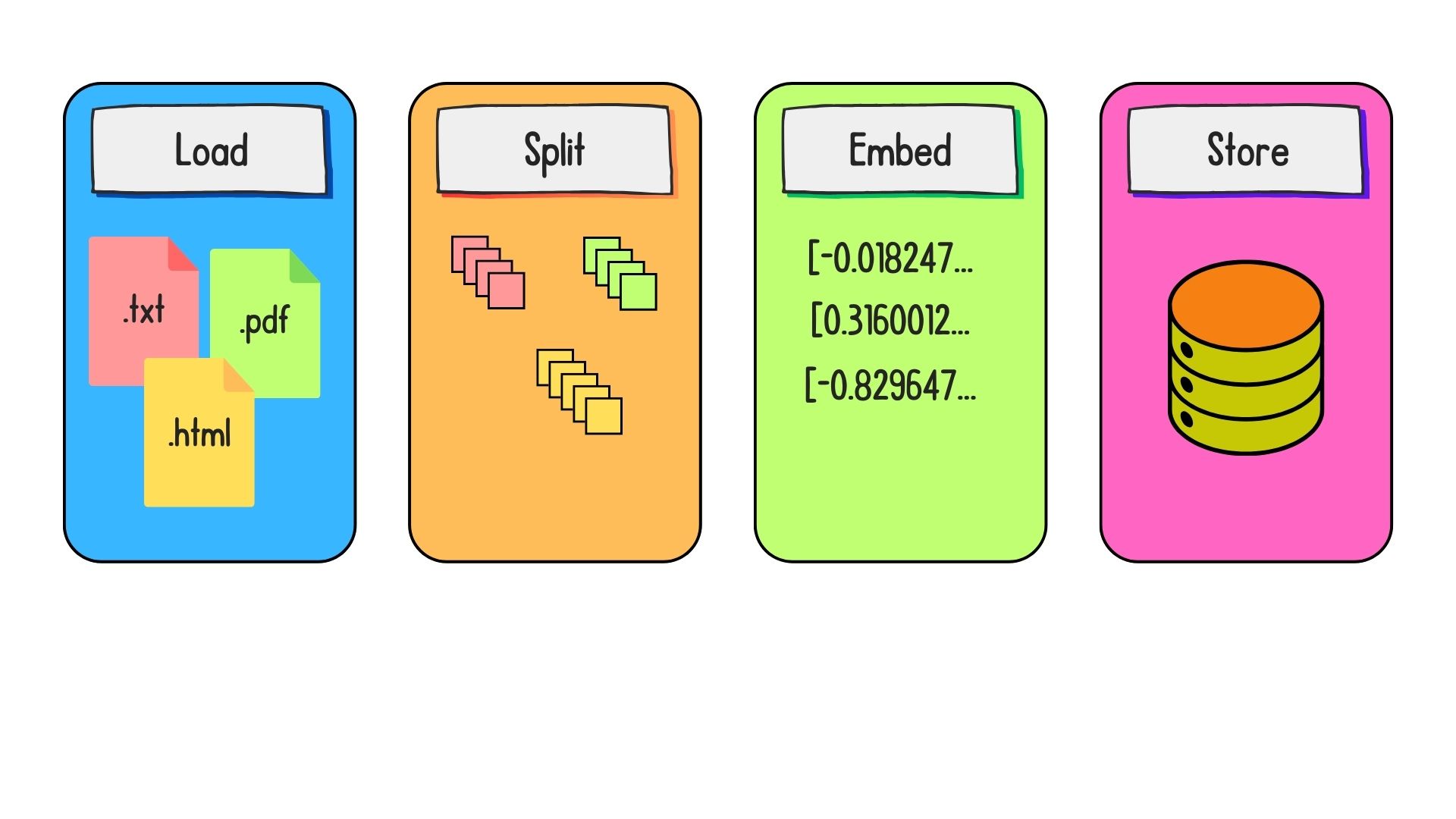
Preparing data for retrieval
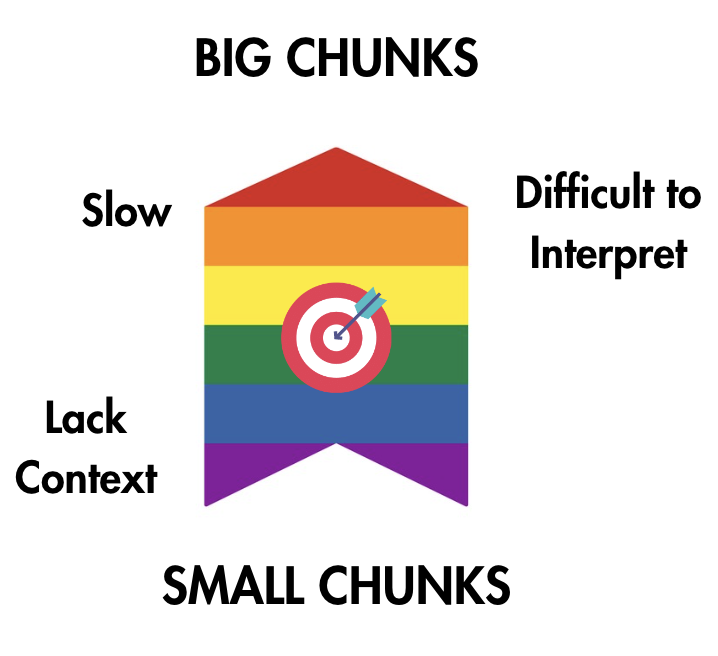
chunk_size
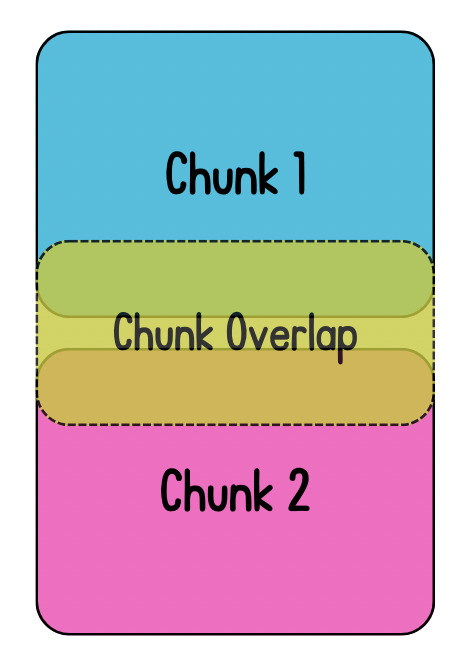
chunk_overlap
- Include information beyond the boundary
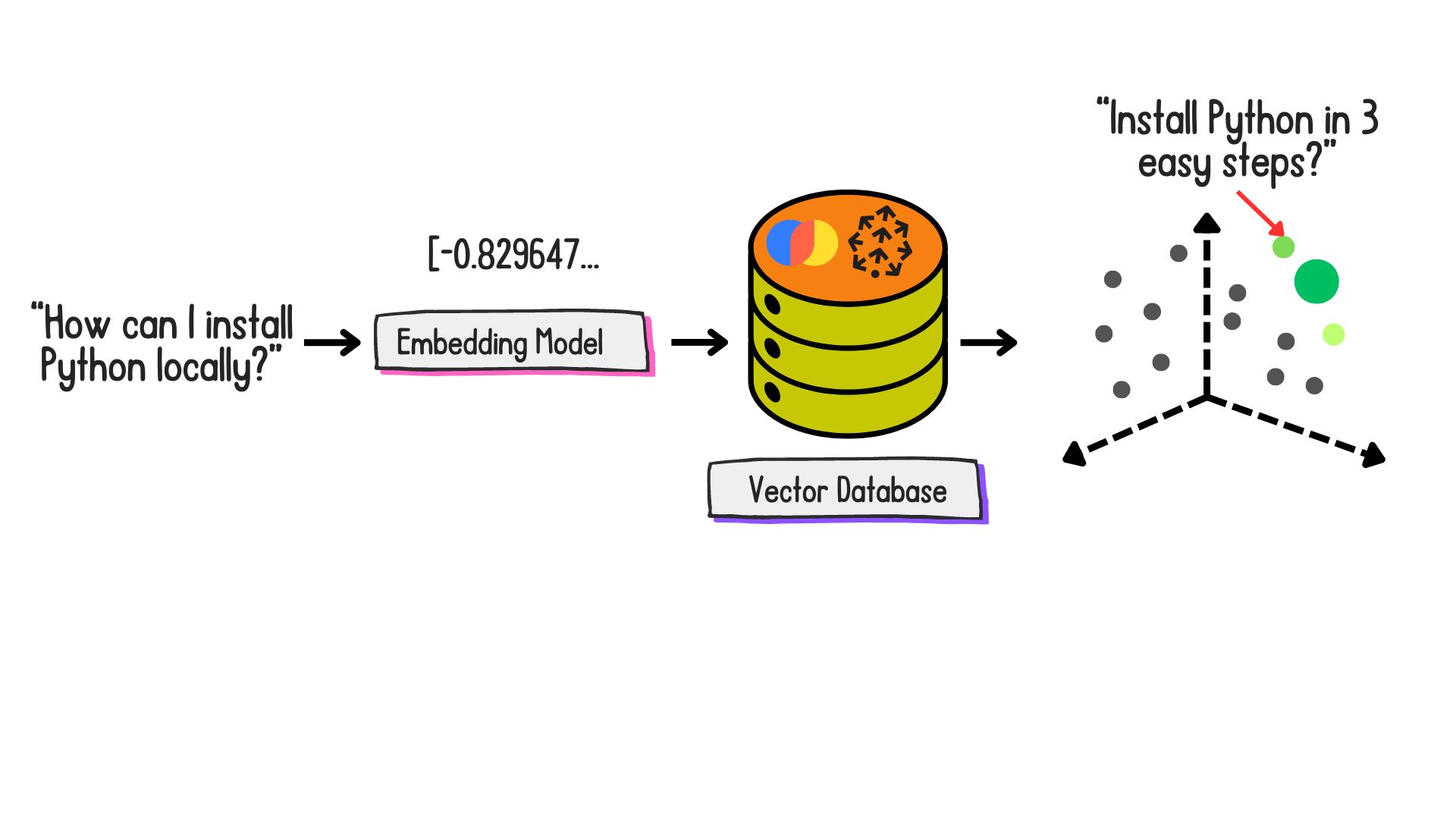
Embedding and storage
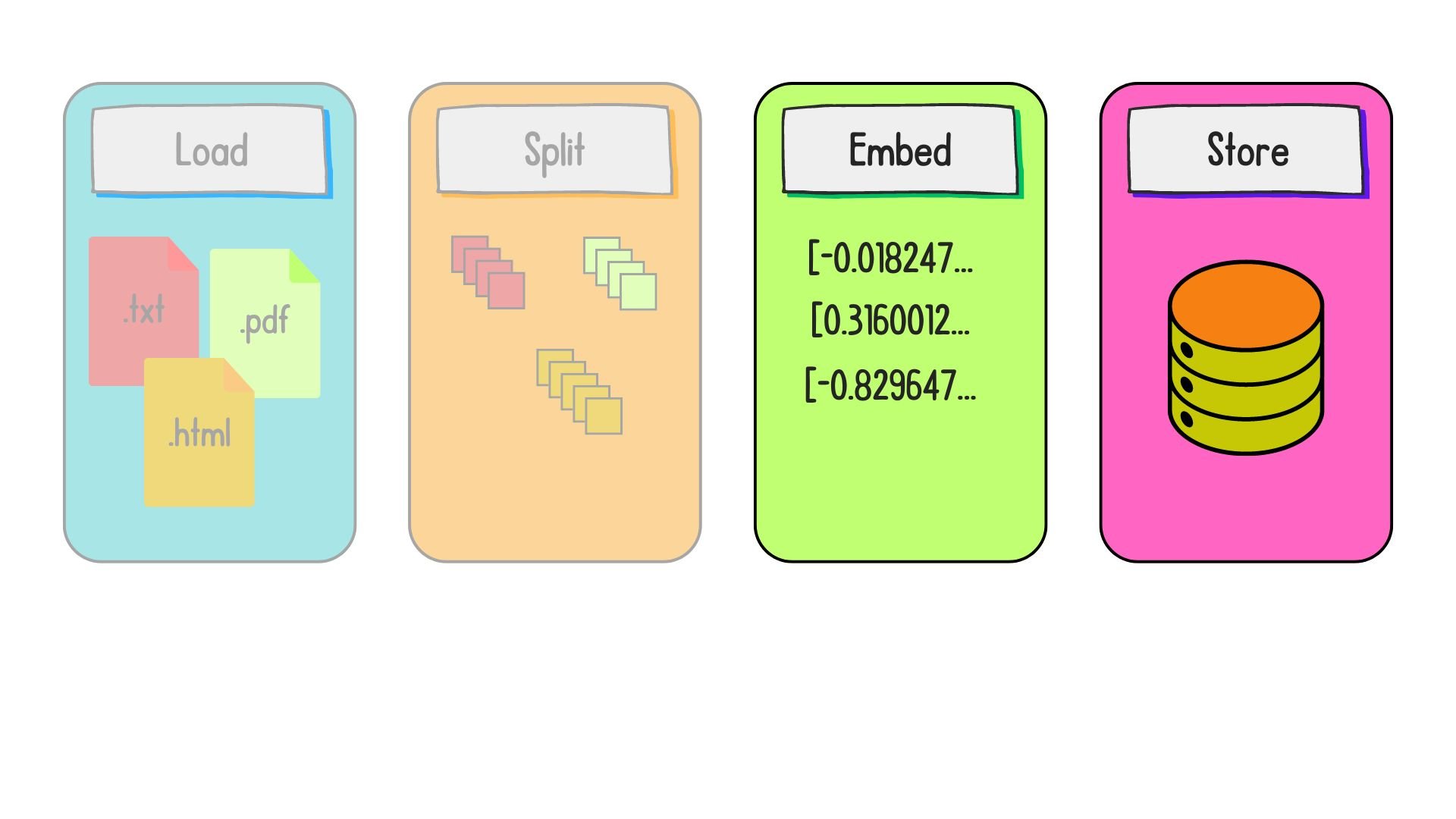
What are embeddings?
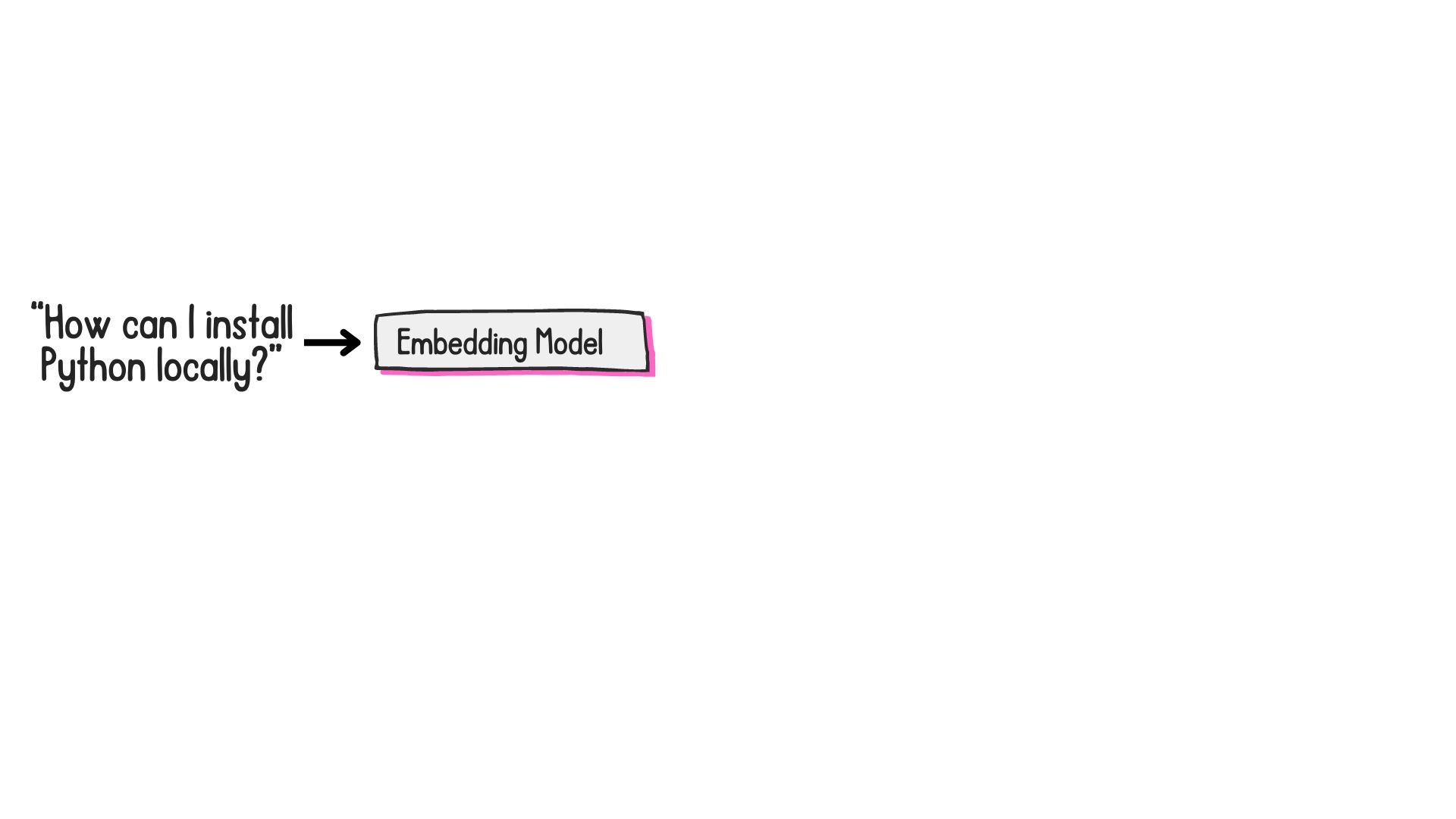
What are embeddings?
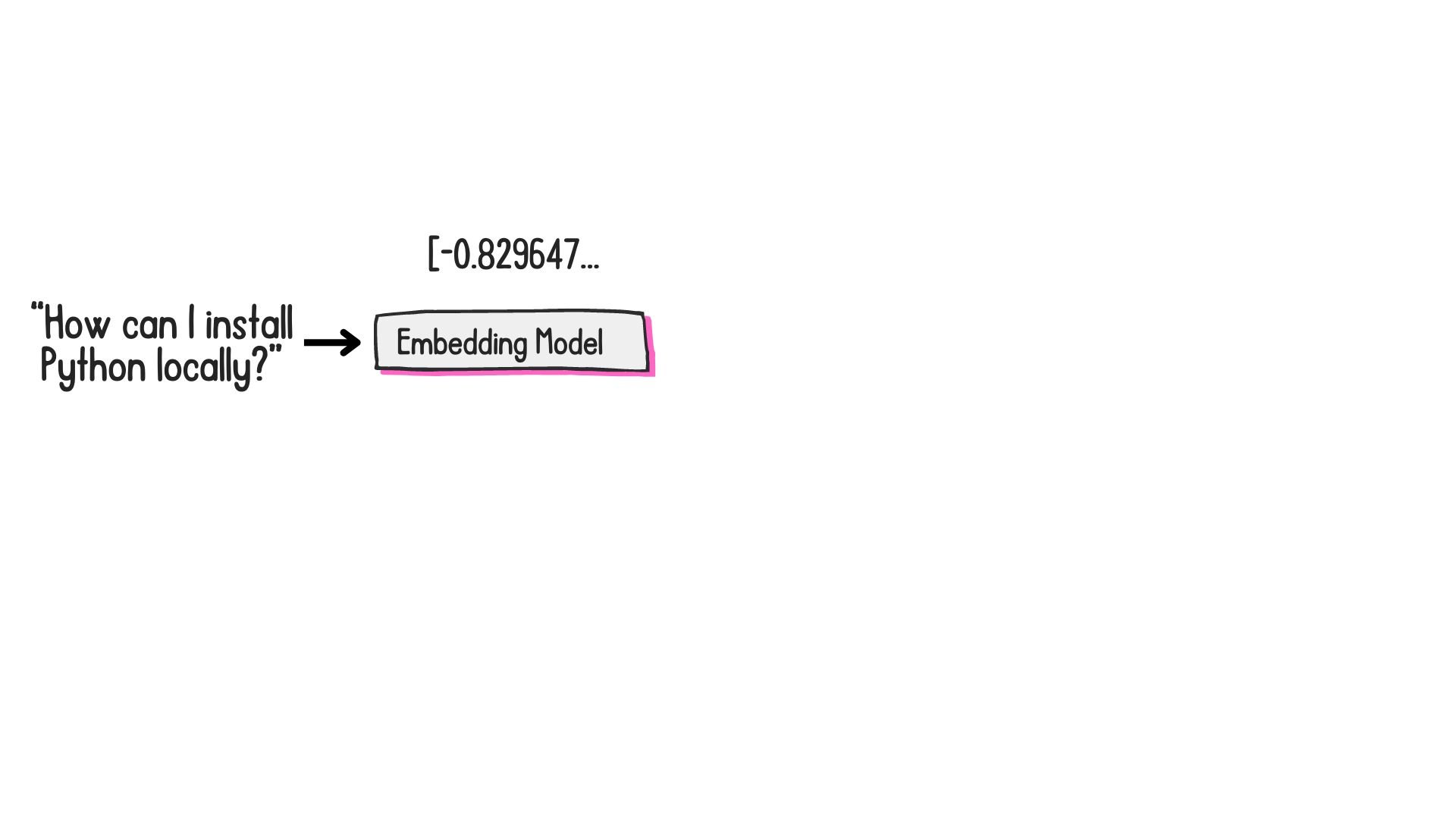
What are embeddings?
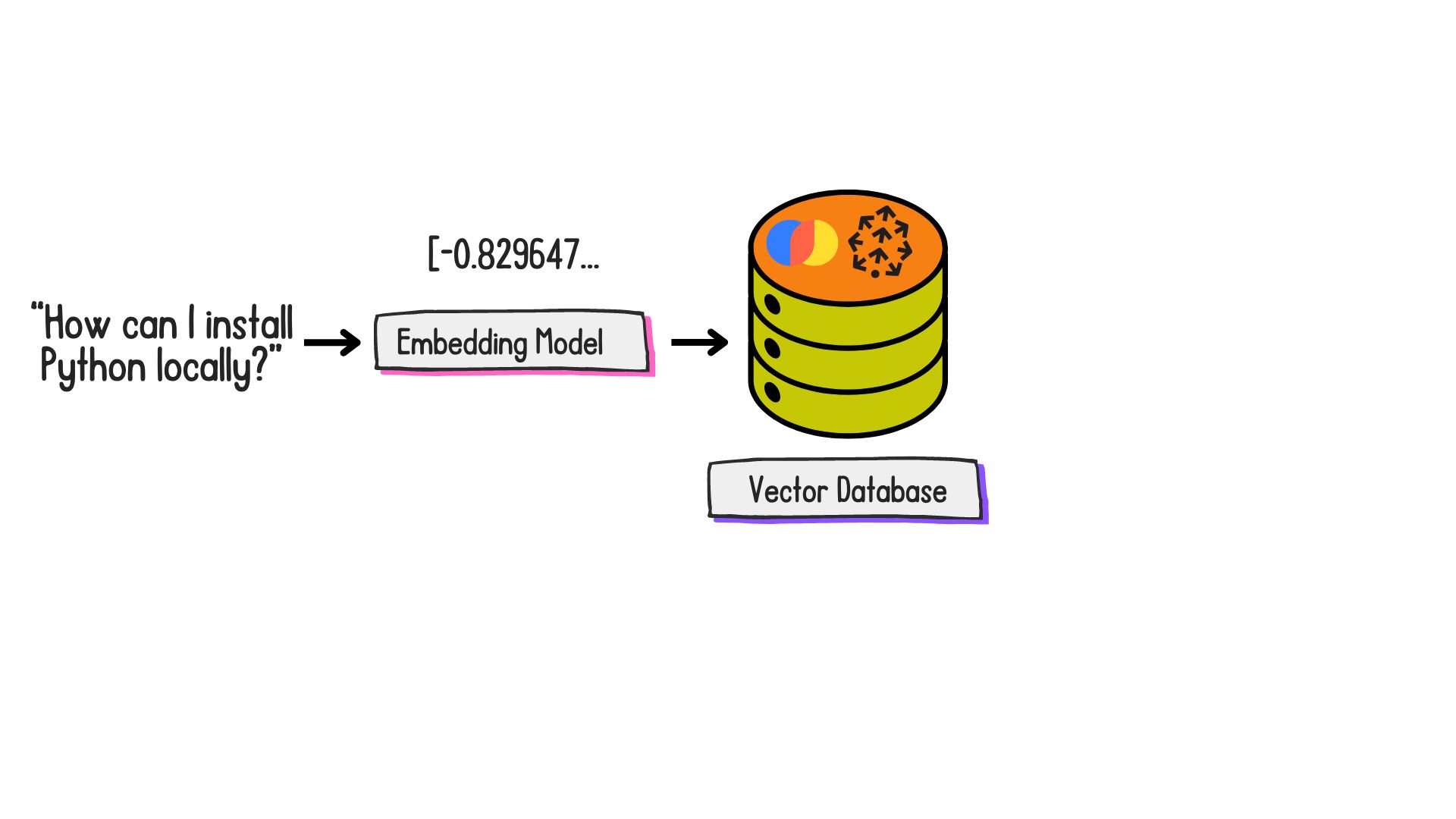
What are embeddings?