Audio classification
Working with Hugging Face

Jacob H. Marquez
Lead Data Engineer
What is audio data?
The importance of sampling
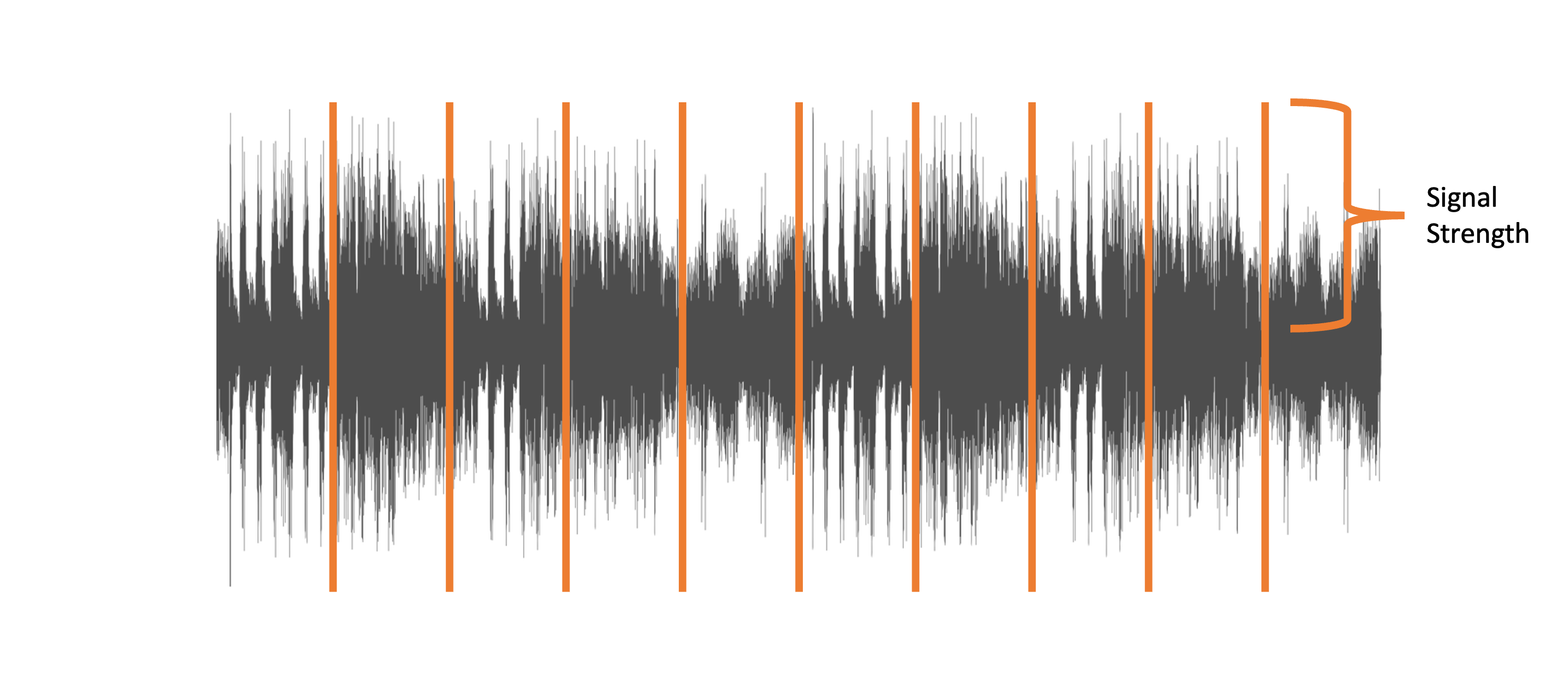
The importance of sampling
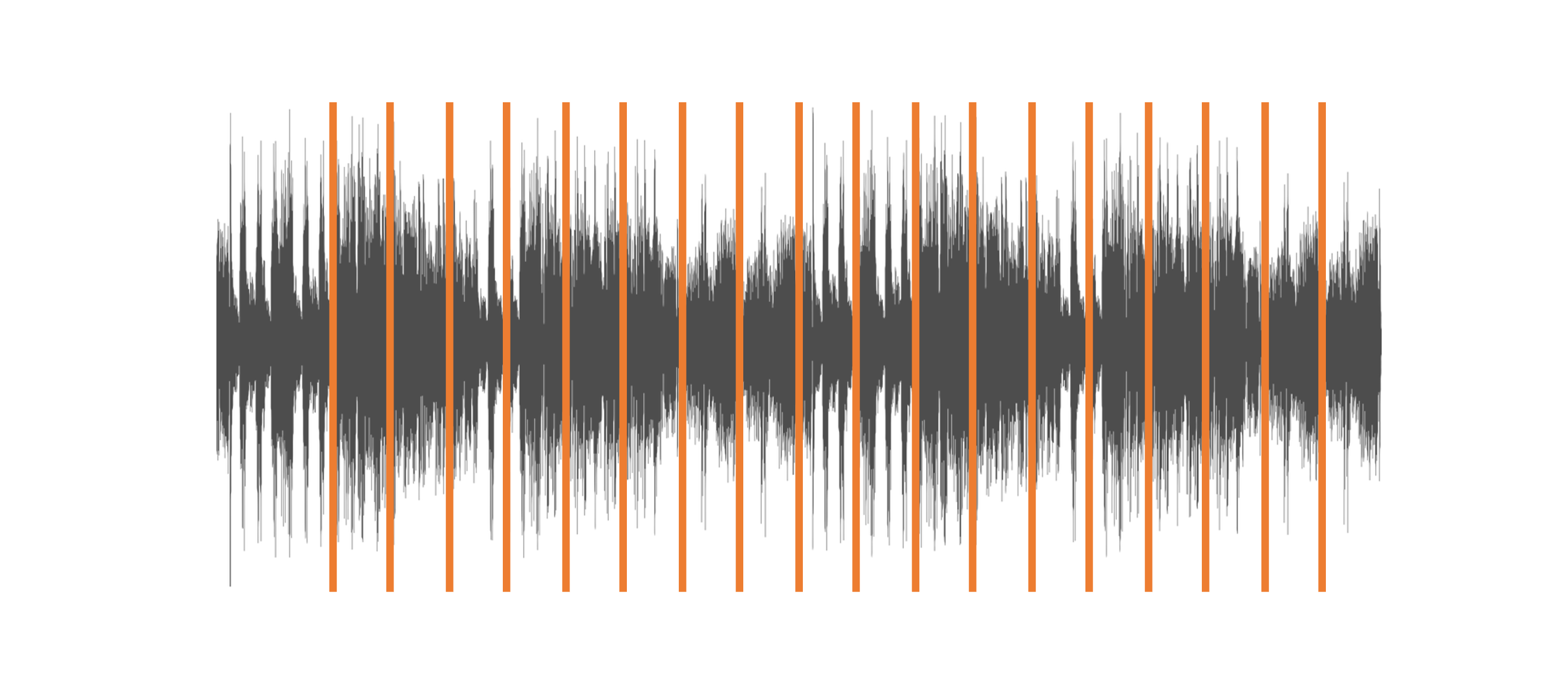
- Speech models trained at 16kHz
- Sampling rate specified in the model card
Resampling
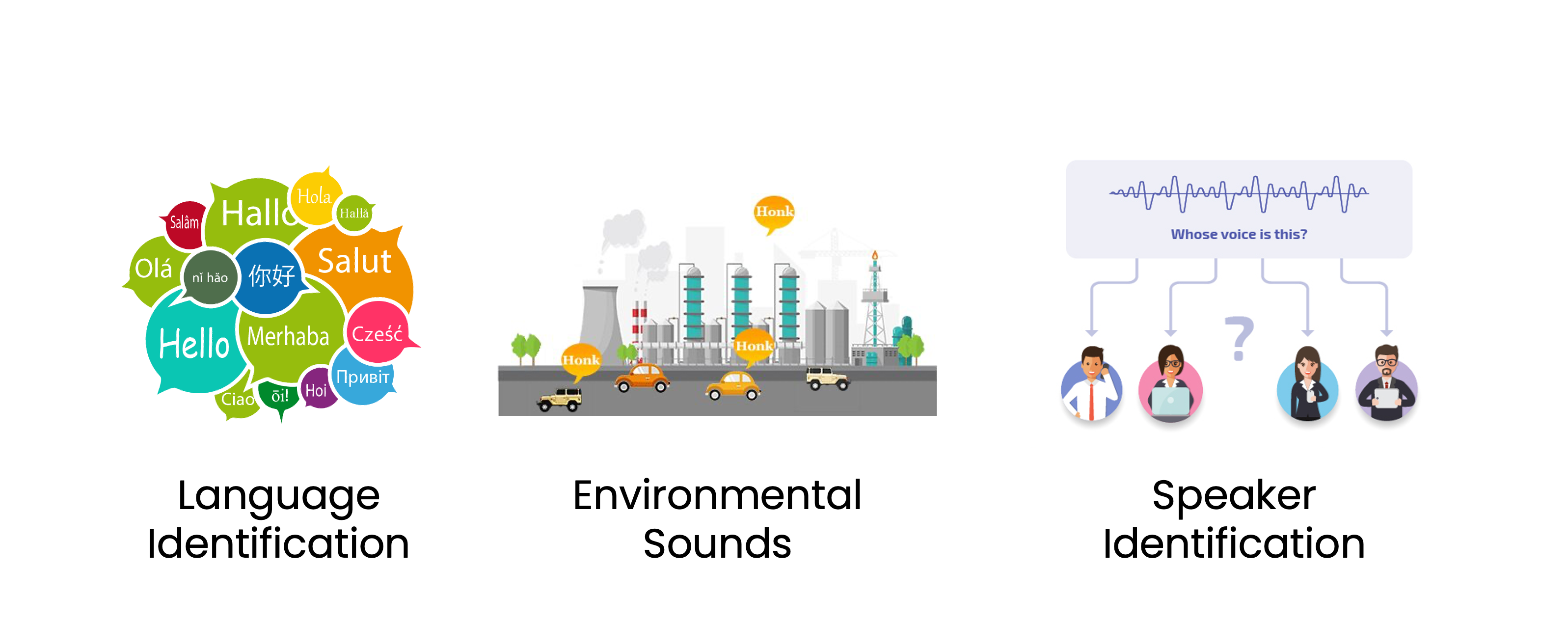
What is audio classification?
Definition: process of assigning one or more labels to audio clips based on its content

What is audio classification?
Definition: process of assigning one or more labels to audio clips based on its content

What is audio classification?
Definition: process of assigning one or more labels to audio clips based on its content