テキスト分類モデルへの敵対的攻撃
PyTorch で学ぶテキストの Deep Learning

Shubham Jain
Instructor
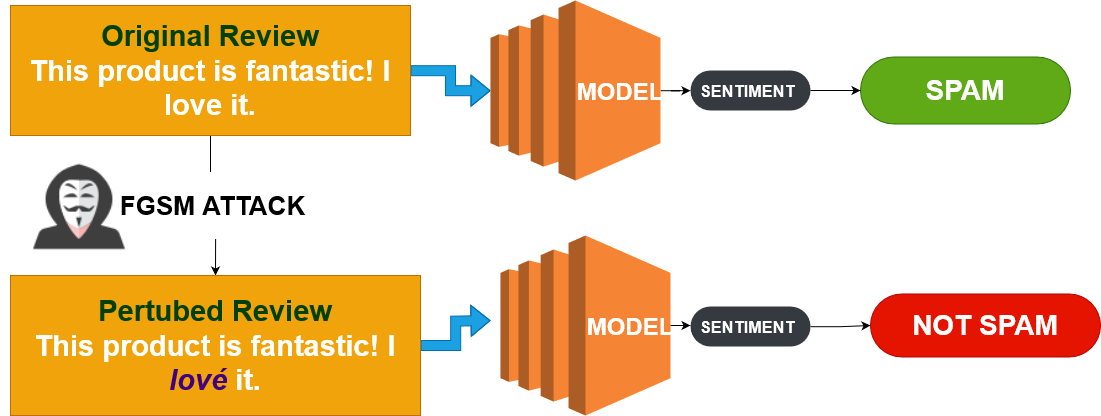
Fast Gradient Sign Method (FGSM)
- モデルの学習情報を突く
- 可能な限り最小の変更で欺く
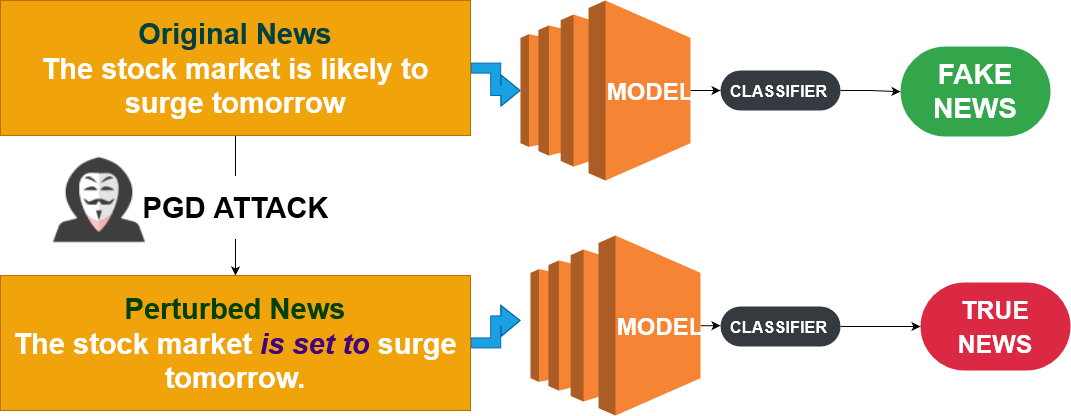
Projected Gradient Descent (PGD)
- FGSMより高機能:反復的
- 最も効果的な摂動を探索
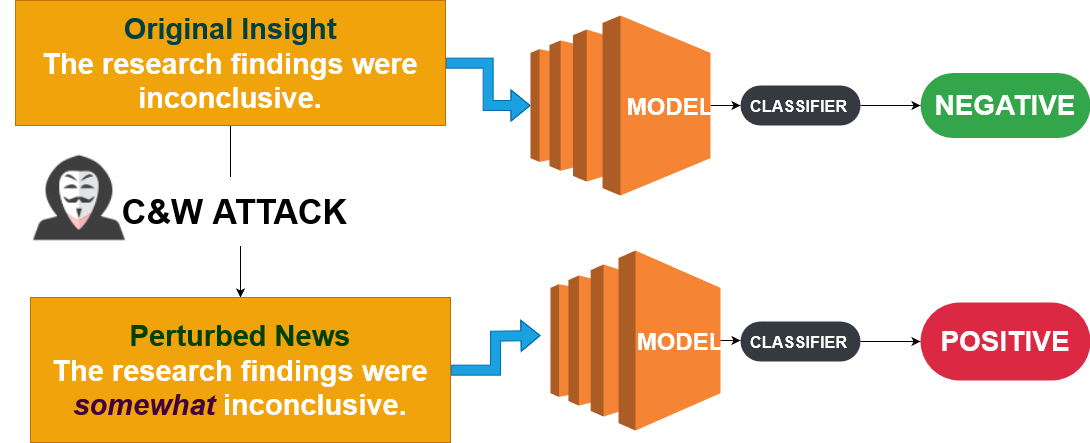
Carlini & Wagner (C&W) 攻撃
- 損失関数の最適化に注力
- だますだけでなく検出回避も重視
防御の構築:戦略
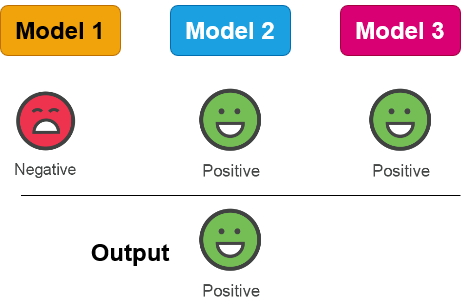
防御の構築:ツールと手法


1 https://adversarial-robustness-toolbox.readthedocs.io/en/latest/, https://stock.adobe.com/ie/contributor/209161356/designer-s-circle

